Object detection 계열의 논문에서 자주 나오는 용어에 대해 먼저 간단히 설명하겠습니다.
Selective Search
Uijlings의 논문에서 제안된 이 방법은, image에서 object의 candidate를 찾기 위한 알고리즘입니다. Color space 정보와 다양한 similarity measure를 활용해서 복잡한 segmentation 결과를 (위의 그림의 가장 왼쪽에서 오른쪽으로) grouping합니다. 뒤에서 설명할 R-CNN의 처음 단계에서 실행되는 알고리즘이기도 합니다.
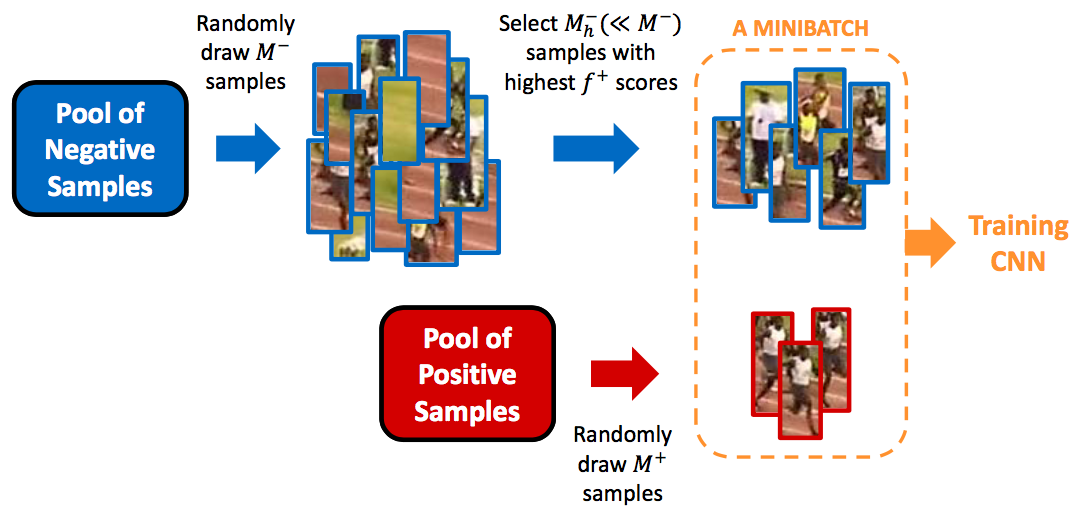
Hard Negative Mining
Hard Negative Mining은 positive example과 negative example을 균형적으로 학습하기 위한 방법입니다. 단순히 random하게 뽑은 것이 아니라 confidence score가 가장 높은 순으로 뽑은 negative example을 (random하게 뽑은 positive example과 함께) training set에 넣어 training합니다.
Bound box의 parameter를 찾는 regression을 의미합니다. 초기의 region proposal이 CNN이 예측한 결과와 맞지 않을 수 있기 때문입니다. Bounding box regressor는 CNN의 마지막 pooling layer에서 얻은 feature 정보를 사용해 region proposal의 regression을 계산합니다. 뒤에서 소개할 R-CNN에서 bounding box regressor가 등장합니다.
2-stage Detection
지금부터 설명드릴 R-CNN 계열의 연구는 모두 2-stage detection에 속합니다.
R-CNN
R-CNN은 CNN을 object detection에 적용한 첫 번째 연구입니다. 위의 그림이 R-CNN 개념을 설명하는 가장 유명한 그림입니다. 그림을 차례로 살펴 보면, (1) input image를 받아서 (2) selective search로 2000개의 region proposal을 추출한 다음, (3) CNN으로 각 proposal의 feature를 계산하고 (4) 각 region의 classification 결과와 bounding box regression을 계산합니다. Classifier로는 SVM을 사용합니다.
R-CNN의 특징은 다음과 같습니다.
Regional Proposal + CNN
Regional proposal을 얻기 위해 selective search 사용
CNN을 사용한 첫 번째 object detection method
각 proposal을 독립적으로 계산 (= 많은 계산 필요)
Bounding box regression으로 detection 정확도 향상
R-CNN의 전체 구조를 다른 그림으로 살펴 보면 아래와 같습니다.
R-CNN은 몇 가지 문제를 가지고 있습니다.
Test 속도가 느림
모든 region proposal에 대해 전체 CNN path를 다시 계산
GPU(K40)에서 장당 13초
CPU에서 장당 53초
SVM과 bounding box regressor의 학습이 분리
Feature vector를 disk에 caching
CNN 학습 과정 후, SVN과 bounding box regressor의 학습이 나중에 진행됨(post-hoc)
학습 과정이 복잡함: 다단계 training pipeline
GPU(K40)에서 84시간
Fast R-CNN
Fast R-CNN은 다음과 같은 특징을 가집니다.
같은 image의 proposal들이 convolution layer를 공유
ROI Pooling 도입
전체 network이 End-to-end로 한 번에 학습
R-CNN보다 빠르고 더 정확한 결과
Fast R-CNN도 처음에 initial RoI (= region proposal)를 찾는 것은 selective search를 사용합니다. 하지만 각 RoI를 매번 convolution 하는 것이 아니라, 전체 image를 한 번만 convolution 합니다. 그 결과로 나온 convolution feature map에서 RoI에 해당하는 영역을 추출해 pooling (= subsampling) 과정을 거쳐 fully connected layer에 넣는 것이 Fast R-CNN의 핵심입니다. 아래 그림은 RoI pooling 과정을 설명하고 있습니다.
Faster R-CNN은 앞에서 설명한 Fast R-CNN을 개선하기 위해 Region Proposal Network (RPN)을 도입합니다. RPN은 region proposal을 만들기 위한 network입니다. 즉, Faster R-CNN에서는 외부의 느린 selective search (CPU로 계산) 대신, 내부의 빠른 RPN (GPU로 계산)을 사용합니다. RPN은 마지막 convolutional layer 다음에 위치하고, 그 뒤에 Fast R-CNN과 마찬가지로 RoI pooling과 classifier, bounding box regressor가 위치합니다. 아래 그림은 RPN의 구조를 보입니다.
Box regression을 위한 초기 값으로 anchor라는 pre-defined reference box를 사용합니다. 이 논문에서는 3개의 크기와 3개의 aspect ratio를 가진 총 9개의 anchor를 각 sliding position마다 적용하고 있습니다. 아래 그림은 anchor의 개념을 보입니다.
Faster R-CNN의 실험 결과입니다. PASCAL VOC 2007 test set을 사용한 실험에서 Faster R-CNN은 R-CNN의 250배, Fast R-CNN의 10배 속도를 내는 것을 볼 수 있습니다. Faster R-CNN은 약 5 fps의 처리가 가능하기 때문에 저자들은 near real-time이라고 주장합니다.
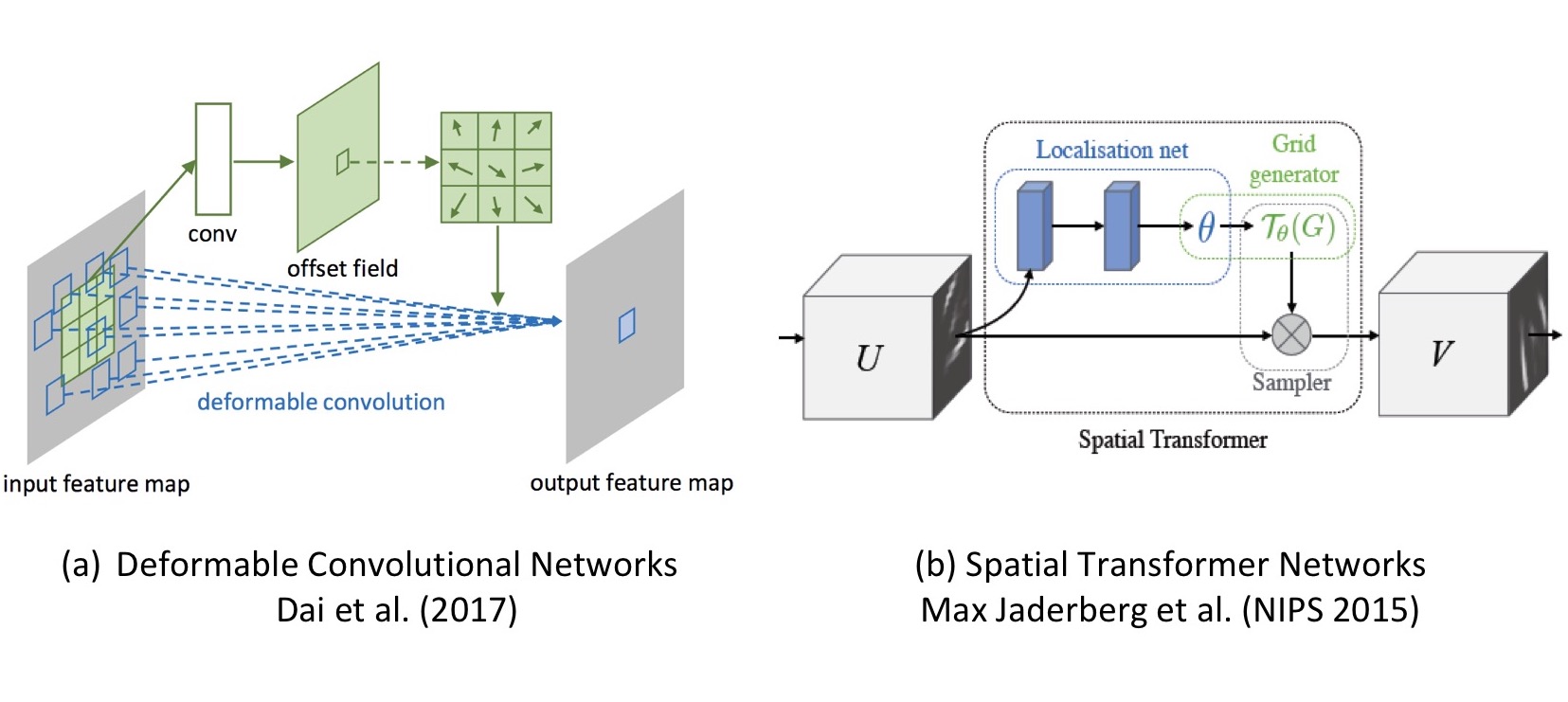
이 논문의 저자들은, CNN (Convolutional Neural Network)이 spatially invariant하지 못한 점이 근본적인 한계라고 주장합니다. CNN의 max-pooling layer가 그런 점을 다소 만족시켜 주기는 하지만, $2 \times 2$ 픽셀 단위의 연산으로는 데이터의 다양한 spatial variability에 대처하기 어렵다는 것입니다. 여기서 말하는 spatial variability란 scale (크기 변화), rotation (회전), translation (위치 이동)과 같은 공간적 변화를 의미한다고 보시면 되겠습니다.
이를 해결하기 위해 이 논문에서는 기존 CNN에 끼워 넣을 수 있는 Spatial Transformer라는 새로운 모듈을 제안합니다.
Spatial Transformer의 개념
Spatial transformer란, 기존의 neural network architecture에 집어넣어 아래 그림과 같이 spatial transformation 기능을 동적으로 제공하는 모듈입니다.
Spatial transformer는 image (또는 feature map)를 입력으로 받아서, scaling, cropping, rotation 뿐만 아니라 thin plate spline과 같은 non-rigid deformation까지 다양하게 지원합니다. 현재 image에서 가장 관련 있는 영역만 골라 선택하거나 (attention), 뒤에 오는 neural network layer의 추론 연산을 돕기 위해 현재의 image (또는 feature map)를 가장 일반적인 (canonical) 형태로 변환하는 등의 용도로 활용할 수 있습니다.
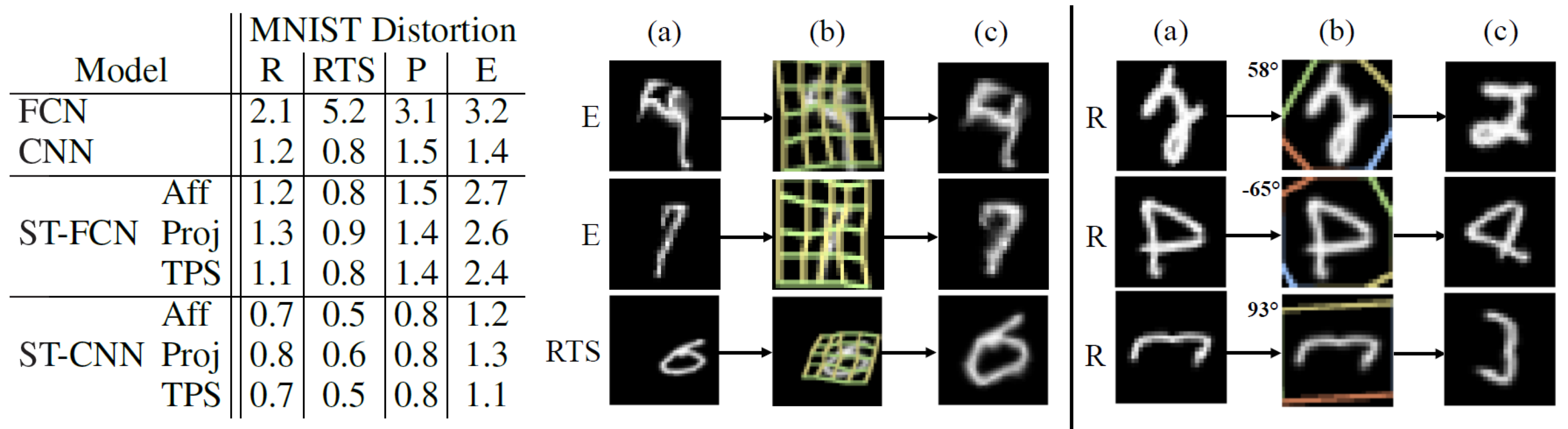
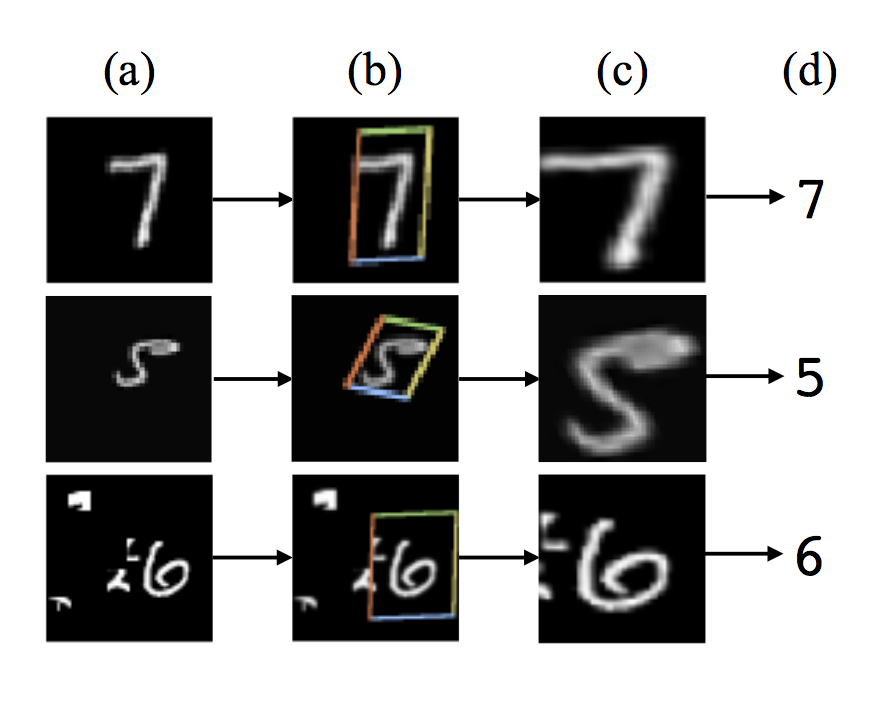
위의 그림은 fully-connected network의 바로 앞 단에 spatial transformer를 사용하고 MNIST digit classification을 위해 training한 결과입니다.
크기와 각도, 중심 위치가 각각인 (a)의 입력들에 대해, spatial transformer는 (b)에 보이는 4각형 영역을 찾아내서 그림 (c)와 같이 변환된 출력을 만들어 fully-connected network에 전달합니다. 그 결과로 classifier가 예측한 숫자 값이 (d)가 됩니다.
Spatial transformer의 동작은 각 입력 데이터 샘플마다 달라지고, 특별한 supervision 없이도 학습 과정에서 습득됩니다. 즉, 사용된 모델의 end-to-end training 과정 중에 backpropagation을 통해 한꺼번에 학습된다는 점이 중요합니다.
Spatial Transformer의 구조
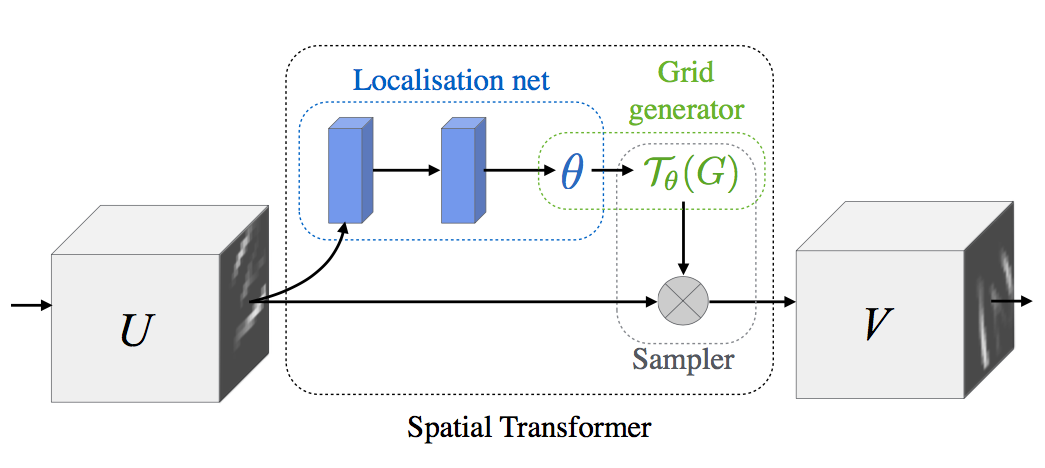
Spatial transformer는 아래 그림과 같이 세 부분으로 구성됩니다.
제일 처음, 그 자체로 작은 neural network인 Localisation Network은 input feature map $U$에 적용할 transform의 parameter matrix $\theta$를 추정합니다.
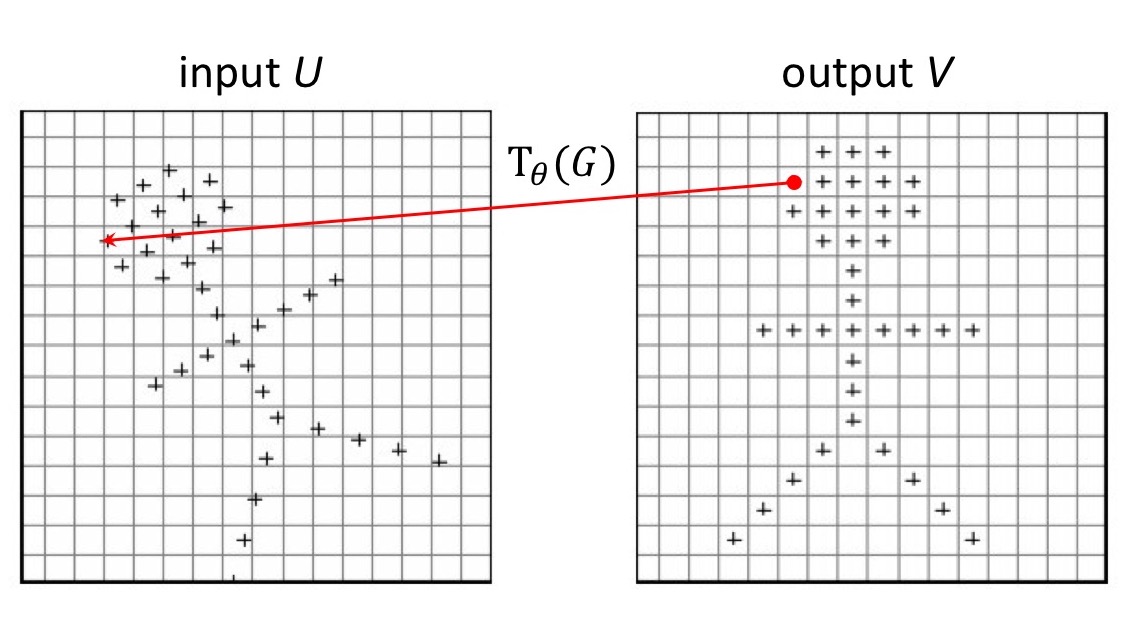
그 다음, Grid Generator는 추정한 $\theta$에 따라 input feature map에서 sampling할 지점의 위치를 정해주는 sampling grid $\mathcal{T}_{\theta}(G)$를 계산합니다.
Localisation network은 input feature map $U$에 적용할 transform의 parameter matrix $\theta$를 추정합니다. 입력 $U \in \mathbb{R}^{H \times W \times C}$은 가로 $W$, 세로 $H$, 채널 수 $C$를 가집니다.
Localisation network은 fully-connected network 또는 convolutional network 모두 가능하며, 마지막 단에 regression layer가 있어 transformation parameter $\theta$를 추정할 수 있기만 하면 됩니다. 이 논문의 실험에서 저자들은 layer 4개의 CNN을 쓰기도 했고 layer 2개의 fully connected network을 사용하기도 했습니다.
Grid Generator
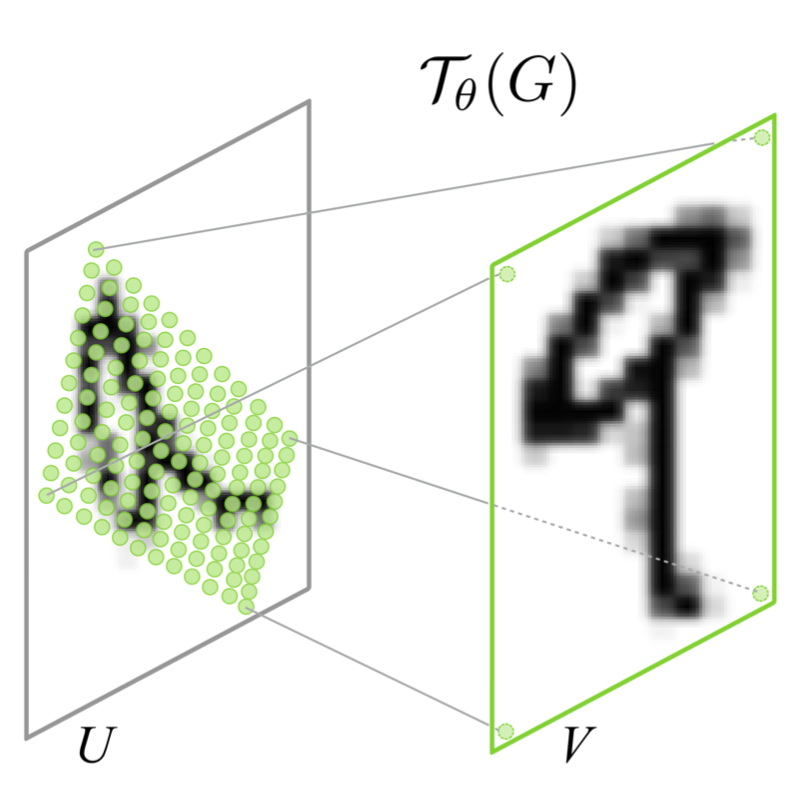
Grid generator는 추정한 $\theta$에 따라 input feature map에서 sampling할 지점의 위치를 정해주는 sampling grid $\mathcal{T}_{\theta}(G)$를 계산합니다.
출력 $V$의 각 pixel $(x_i^t, y_i^t)$은 regular grid (= 일반적인 직사각형 모눈 형태) $G$ 위에 위치하고 있습니다. 출력 $V$의 sampling grid $G$는 transform 를 거쳐 입력 $U$의 sampling grid $\mathcal{T}_{\theta}(G)$으로 mapping 됩니다. 이 과정을 그림으로 보이면 아래와 같습니다.
위의 그림에서 보는 것처럼 그 위치가 정확히 정수 좌표 값을 가지지 않을 가능성이 더 높기 때문에, 주변 값들의 interpolation을 통해 값을 계산합니다. 이 과정을 표현하면 아래 식처럼 됩니다.
Interpolation을 구현하는 함수를 일반적인 sampling kernel $k()$로 표시했기 때문에 어렵게 보입니다만, 그 의미는 어렵지 않습니다. (참고로 Interpolation 이론에 대해서는 Image Processing 과목의 자료에 잘 나와 있습니다. Silvio Savarese의 슬라이드 “Interpolation”를 추천 드립니다
전체 네트워크에서 loss 값을 backpropagation으로 계산하려면 $U$와 $G$에 대해 미분 가능해야 합니다. Bilinear interpolation의 경우 각각의 partial derivative를 구해보면 아래 식과 같습니다.
$\frac{\partial V_i^c}{\partial y_{i}^s}$의 식도 마찬가지로 구할 수 있습니다. Sampling function이 모든 구간에서 미분가능하지 않은 경우에도, 구간별로 나눠 subgradient를 통해 backpropagation을 계산할 수 있습니다.
Spatial Transformer Networks
Localisation network, grid generator와 sampler로 구성한 spatial transformer module을 CNN 구조에 끼워 넣은 것을 Spatial Transformer Network이라고 합니다. Spatial transformer module은 CNN의 어느 지점에나, 몇 개라도 이론상 집어넣을 수 있습니다.
Spatial transformer가 어떻게 input feature map을 transform할 지는 CNN의 전체 cost function을 최소화하는 training 과정 중에 학습됩니다. 따라서 전체 training 속도에 미치는 영향이 거의 없다고 저자들은 주장합니다.
Spatial transformer module을 CNN의 입력 바로 앞에 배치하는 것이 가장 일반적이지만, network 내부의 깊은 layer에 배치해 좀더 추상화된 정보에 적용을 한다거나 여러 개를 병렬로 배치해서 한 image에 속한 여러 부분을 각각 tracking하는 용도로 사용할 수도 있다고 합니다. 복수의 spatial transformer module을 동시에 적용하는 실험 결과가 뒷 부분에 있는 동영상에서 MNIST Addition이라는 이름으로 소개됩니다.
실험 결과
Supervised learning 문제에 대해 spatial transformer network를 적용하는 몇 가지 실험 결과를 보겠습니다.
Distorted MNIST
먼저, distorted된 MNIST 데이터셋에 대해 spatial transformer로 classification 성능을 개선하는 실험입니다.
이 실험에서 사용된 MNIST 데이터는 4가지 방법으로 distorted 되었습니다: rotation (R), rotation-translation-scale (RTS), projective transformation (P), elastic warping (E)
모델로는 기본 FCN과 CNN, 그리고 각각 앞 단에 spatial transformer를 추가한 ST-FCN과 ST-CNN을 사용했습니다. CNN에는 2개의 max-pooling layer가 있습니다.
아래의 실험 결과에서 ST-CNN이 가장 성능이 좋은 것을 알 수 있습니다. CNN이 FCN 보다 더 성능이 좋은 것은 max-pooling layer가 spatial invariance에 기여하고 convolutional layer가 모델링을 더 잘하기 때문일 것으로 보입니다.
한편, 같은 모델 안에서는 TPS transformation이 가장 좋은 성능을 보였습니다.
아래 YouTube 비디오는 이 논문의 저자가 직접 공개한 실험 결과를 요약한 동영상입니다. 이 논문에서 상세히 다루지 않은 MNIST addition 실험(2개의 숫자 동시 인식)과 co-localisation (수십 개의 숫자 인식) 실험도 추가되어 있습니다.
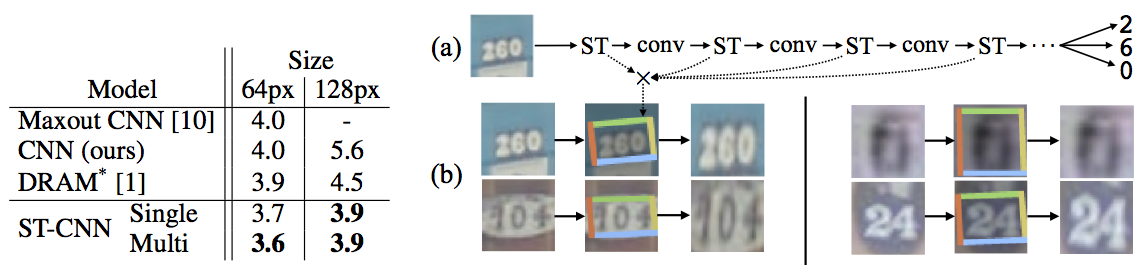
이 실험에서는 아래 그림의 (a)와 같이 CNN의 convolutional stack 부분에 복수의 spatial transformer를 삽입해서 사용했습니다.
모델로는 기본 CNN 모델 (11개 hidden layer)과 ST-CNN Single, ST-CNN Multi를 사용했습니다. ST-CNN Single은 CNN 입력 단에 4-layer CNN으로 구성된 spatial transformer를 추가한 것입니다. ST-CNN Multi은 아래 그림의 (a)와 같이 CNN의 처음 4개의 convolutional layer 앞 단에 2-layer FCN spatial transformer를 하나씩 삽입한 모델입니다. 즉 뒤 3개의 spatial transformer는 convolutional feature map을 transform하는 용도입니다. 모든 spatial transformer에는 affine transformation과 bilinear sampler를 사용했습니다.
실험 결과, ST-CNN Multi 모델이 가장 높은 성능을 보였는데 그럼에도 기본 CNN 모델보다 6%만 느려졌다고 합니다.
Fine-Grained Classification
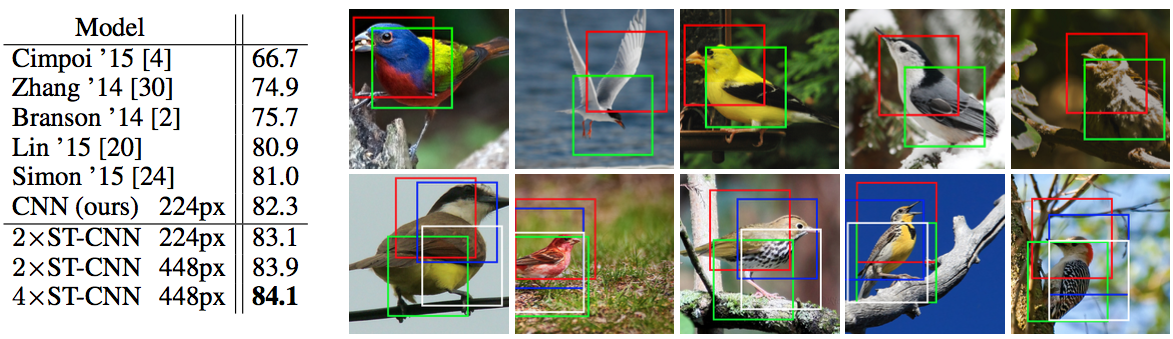
세 번째로, 200종의 새 사진 11,788장으로 구성된 Caltech의 CUB-200-2011 birds 데이터셋에 fine-grained bird classification을 적용한 실험입니다.
이 두 논문은 공통적으로 내부의 transformation parameter를 데이터로부터 학습한다는 특징이 있습니다.
차이점으로는, spatial transformer networks는 parameter로 transform matrix (affine의 경우 6개 element)면 충분한 반면, deformable convolution networks는 sampling grid의 모든 pixel에 대해 offset 값이 필요합니다.
또한, spatial transformer networks는 input $U$에서 output $V$로 mapping하는 연산이 explicit하게 필요하지만, deformable convolution networks는 그 과정이 원래의 convolution 연산에 포함되어 별도로 필요하지 않습니다.
그밖에, deformable convolution networks 논문의 저자들은 spatial transformer networks가 thin plate spline과 같은 warping을 지원할 수 있지만 그만큼 연산이 많이 필요하다고 주장하고 있습니다.
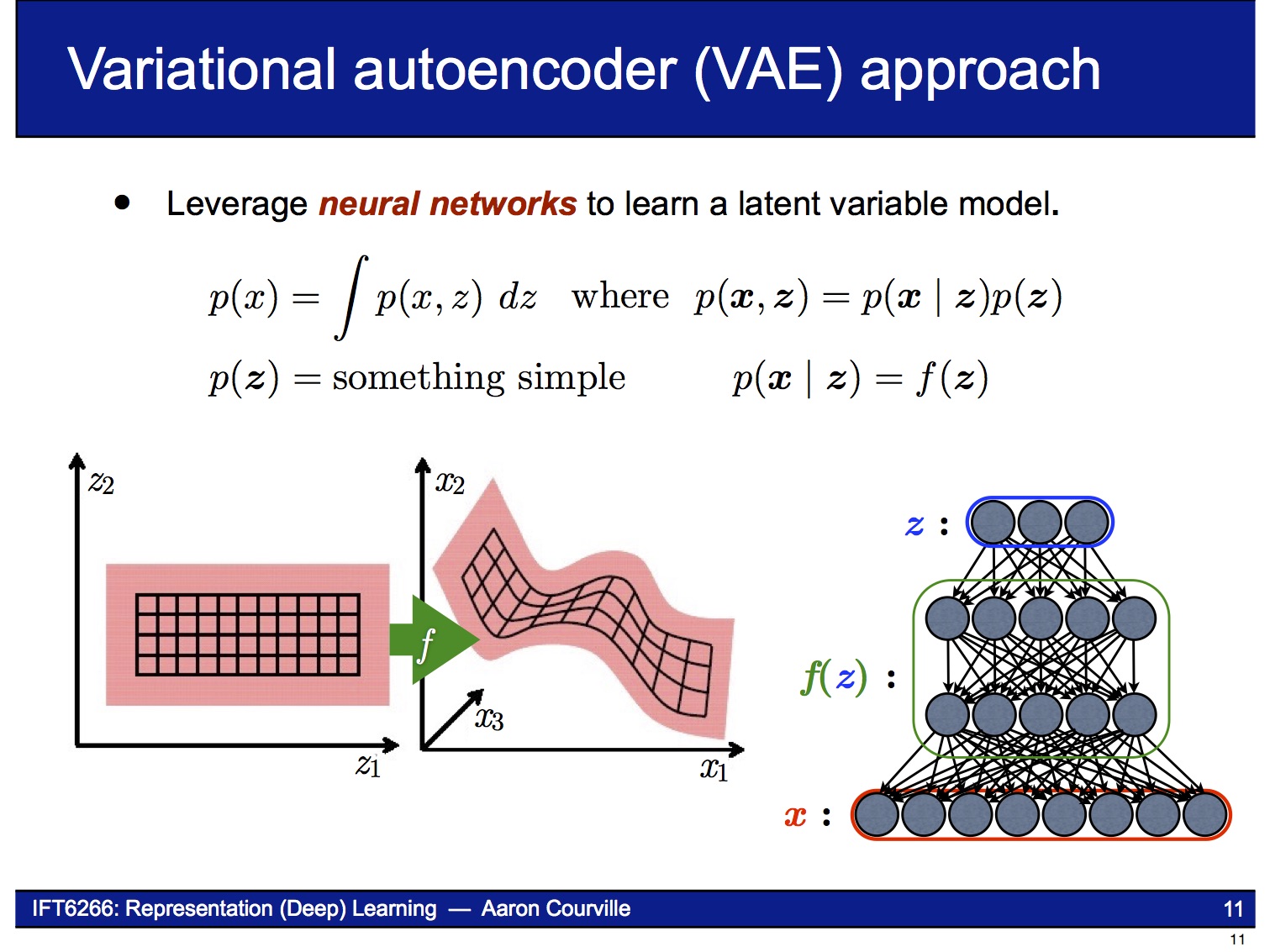
흔히 VAE (Variational Auto-Encoder)로 잘 알려진 2013년의 이 논문은 generative model 중에서 가장 좋은 성능으로 주목 받았던 연구입니다. Ian J. Goodfellow의 “GAN”을 이해하려면 필수적으로 보게 되는 논문이기도 합니다.
이 논문은 수학식이 중심이라 이해하기가 쉽지 않습니다만, 다행히 그동안 많은 분들이 해오신 풀이가 이미 있기 때문에 이번 포스팅에서는 가급적 그림과 개념적인 이해 중심으로 설명하겠습니다.
Introduction
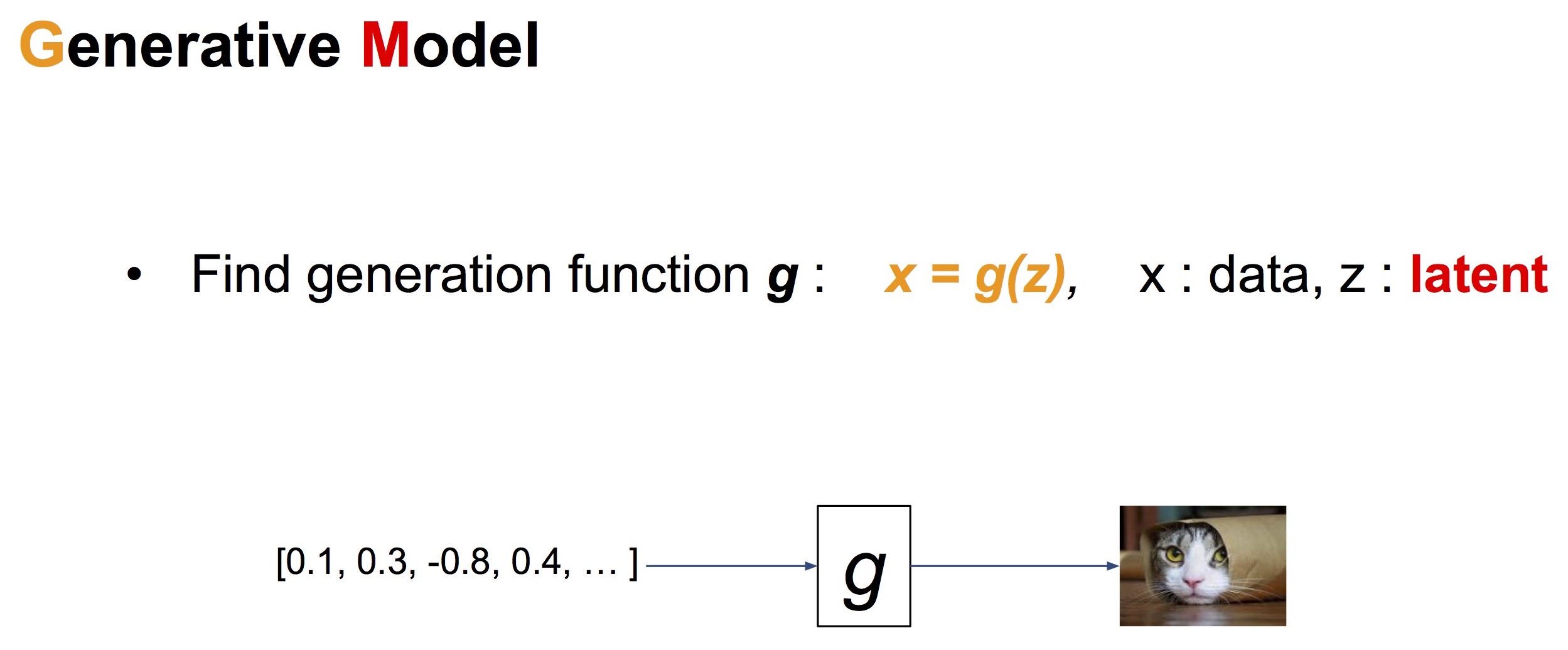
Generative Model
이 논문에서 소개할 Variational Auto-Encoder는 일종의 Generative Model입니다. Generative Model은 입력 변수(latent variable) $z$로부터 결과물 $x$ (가장 흔하게는 image)을 만들어내는 모델입니다. 아래 그림과 다음 그림은 김남주 님의 슬라이드 “Generative Adversarial Networks (GAN)”에서 인용했습니다.
Unsupervised learning과 generative model을 비교하면 아래 표와 같습니다.
model
formula
distribution
role
unsupervised model
$z = f(x)$
$p(z|x)$
Encoder
generative model
$x = g(z)$
$p(x|z)$
Decoder
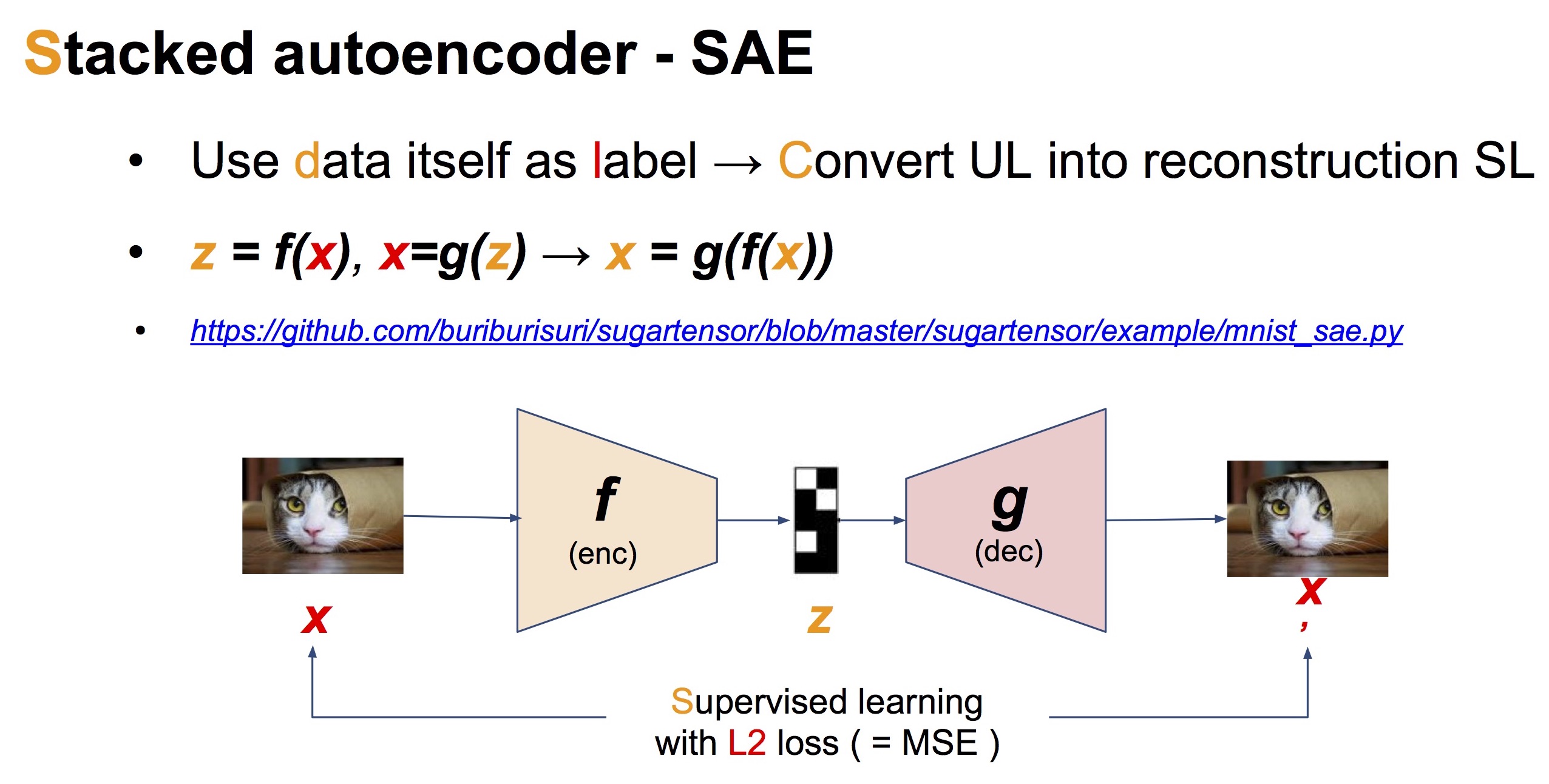
Autoencoder
Autoencoder는 입력 데이터 $x$ 자신을 다시 만들어내려는 neural network 모델입니다. 구조는 아래 그림처럼 latent code $z$를 만드는 encoder와 $x’$를 만드는 decoder가 맞붙어 있는 형태가 됩니다. Autoencoder는 입력 $x$와 출력 $x’$ 사이의 L2 loss (= mean squared error)를 최소화하도록 training 됩니다.
Variational Auto-Encoder (VAE)
VAE는 Autoencoder의 특성을 물려 받았지만, 약간 다른 점이 있습니다.
Autoencoder에서는 $z$가 training data와 특별히 관련이 없이 단순히 계산 중간에 나오는 deterministic한 값일 뿐입니다. 반면, VAE에서는 latent variable $z$가 continuous한 분포를 가지는 random variable이라는 점이 중요한 차이입니다. 이 latent variable $z$의 분포는 training 과정에서 data로부터 학습됩니다.
VAE는 decoder 부분만 떼어내 Generative Model로 사용할 수 있습니다. Encoder는 decoder에 어떤 입력 $z$를 넣을지 학습으로 알게 됩니다.
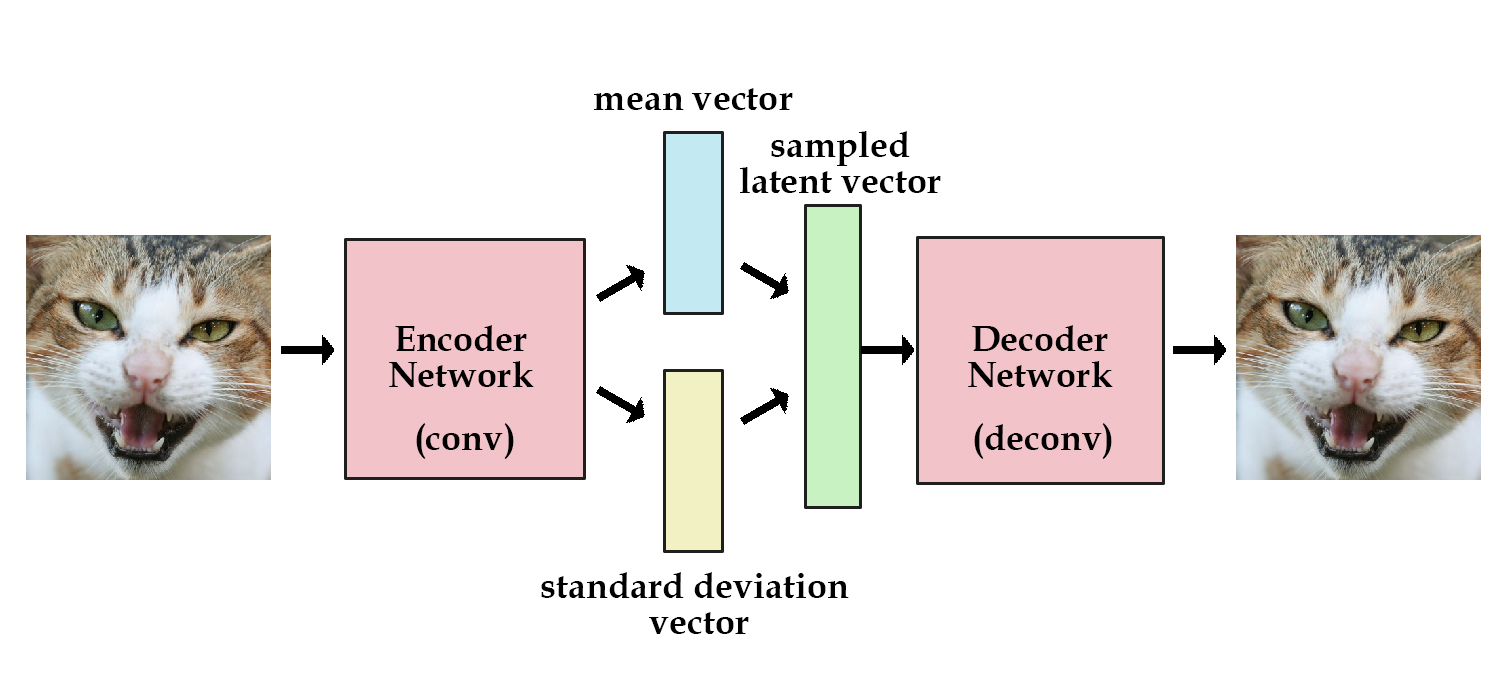
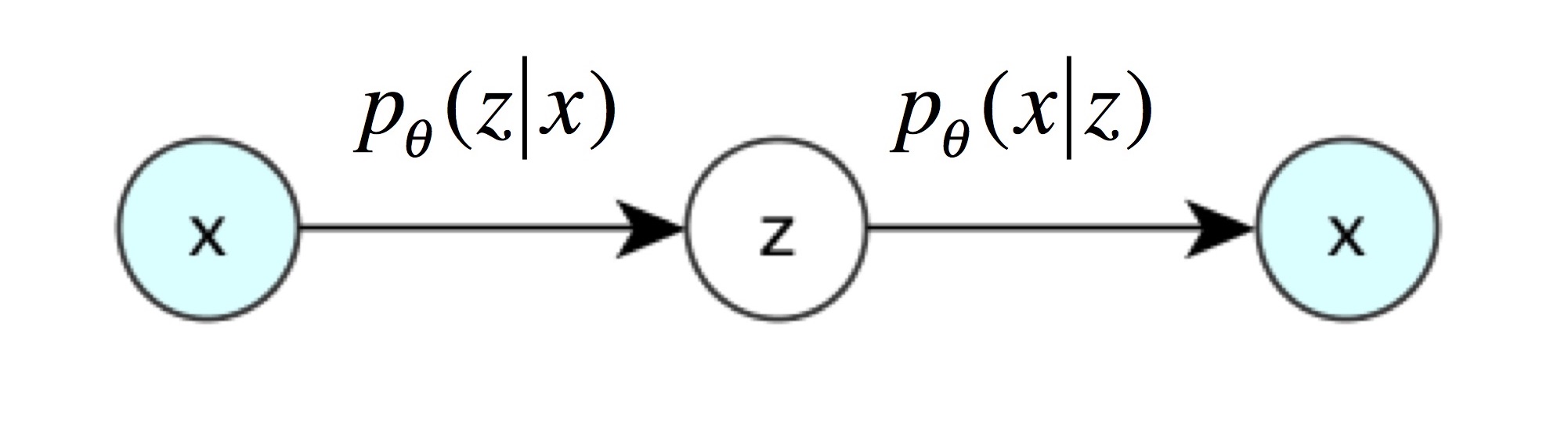
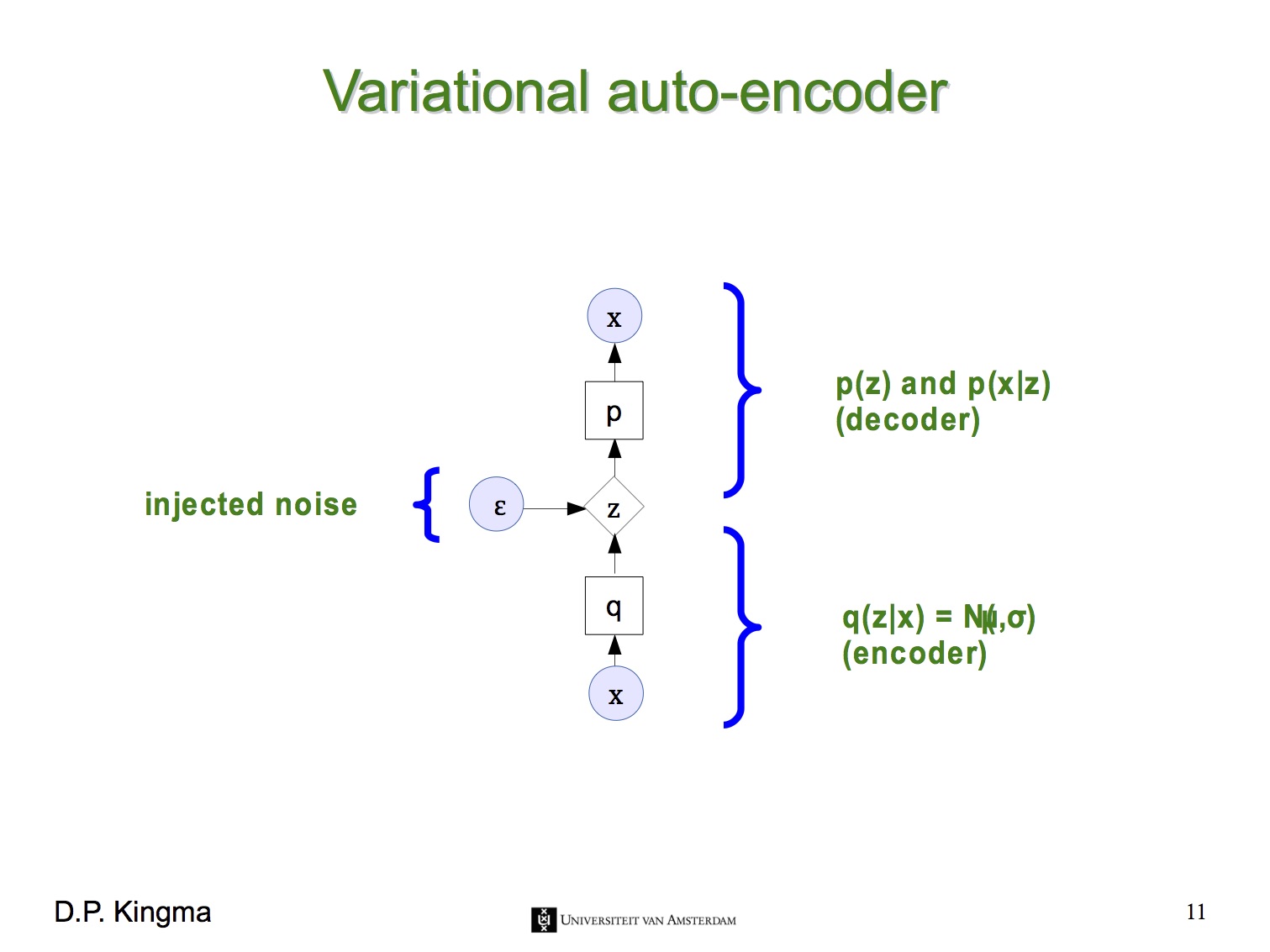
즉, 지금부터는 latent variable $z$가 평균과 표준편차로 결정되는 확률 분포를 가진다는 뜻입니다. VAE의 encoder는 주어진 $x$로부터 $z$를 얻을 확률 $p(z|x)$로, VAE의 decoder는 $z$로부터 $x$를 얻을 확률 $p(x|z)$로 나타낼 수 있습니다. 아래 그림들은 Kevin Frans의 블로그와 Oliver Dürr의 슬라이드에서 인용했습니다.
Decoder
VAE의 decoder는 latent variable $z$로부터 $x$를 만들어내는 neural network입니다. 결과물 $x$의 확률 분포 $p(x)$를 알기 위해, decoder는 $p(x|z)$을 학습합니다. 아래에 나오는 슬라이드들은 이 논문의 저자인 Kingma의 발표자료에서 인용했습니다.
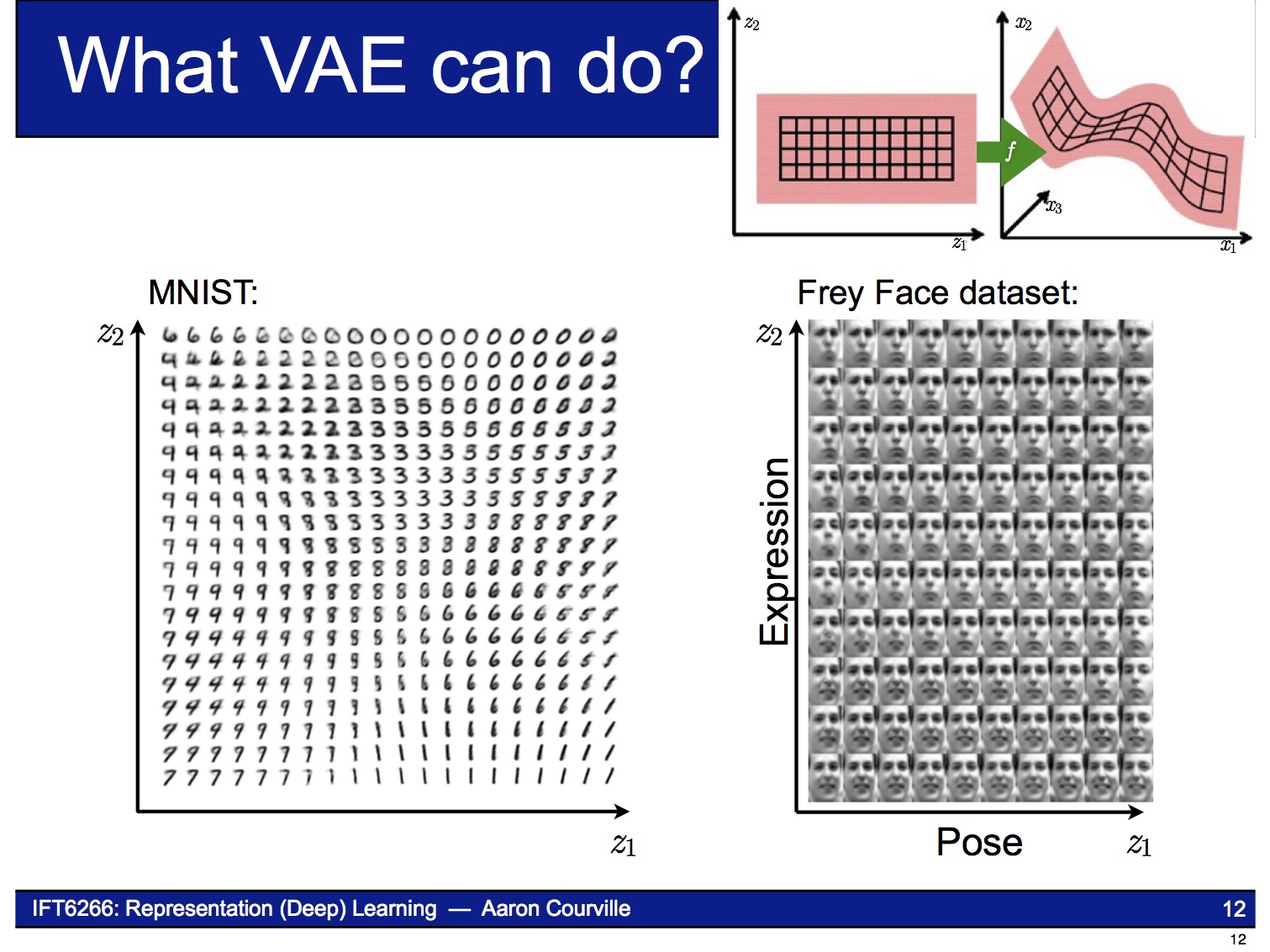
Decoder는 Generative Model이므로 latent variable $z$의 sample 값이 달라짐에 따라 아래 그림처럼 연속적으로 변하는 결과물을 만들어낼 수 있습니다.
Encoder
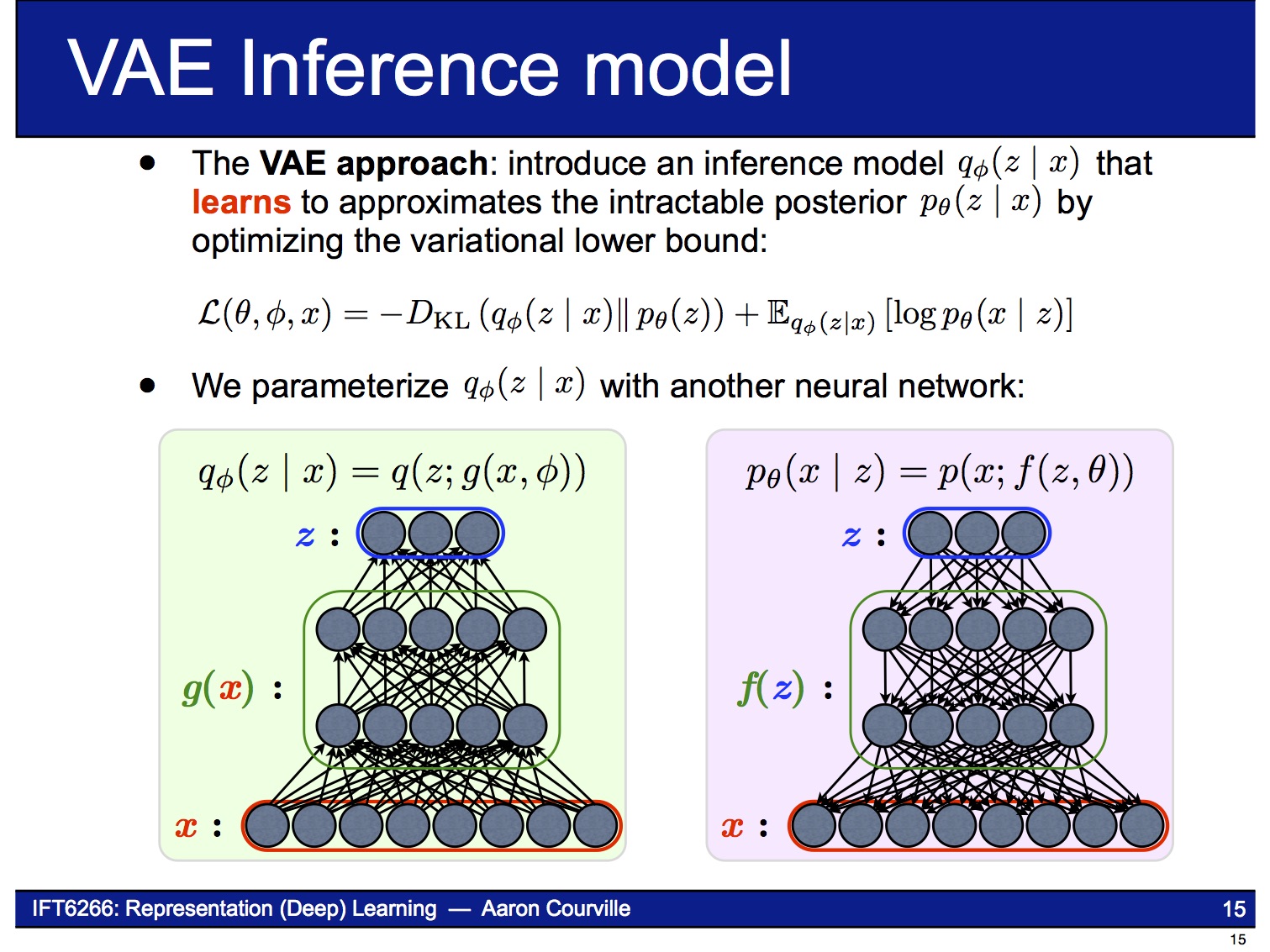
VAE의 encoder는 주어진 $x$로부터 $z$를 얻는 neural network입니다. VAE 논문에 나오는 복잡한 수학식들은 바로 이 encoder 부분을 설명하기 위한 것입니다. $x$가 주어졌을 때 $z$의 확률 분포 $p(z|x)$는 posterior distribution이라고 불리는데, 그 값을 직접 계산하기 어려운(intractable) 것으로 알려져 있습니다.
그래서 이 논문에서는 계산할 수 있는 $q(z|x)$라는 변수를 대신 도입해 $p(z|x)$로 근사 시키는 방법을 사용합니다. 이런 방법을 Variational Bayesian methods 또는 Variational Inference라고 부르고, VAE의 ‘Variational’도 거기에서 온 것입니다. (수식에 나오는 $\theta$, $\phi$는 각각 $p(z|x)$, $q(z|x)$의 parameter입니다.)
우리가 알고 싶은 것은 실제 데이터의 확률 분포인 $p(x)$이지만, 계산의 편의를 위해 log likelihood 값인 $\log p(x)$를 대신 풀어보면 lower bound 를 얻을 수 있습니다.
이제 파라미터 $\phi$와 $\theta$를 조절하여 를 maximize하는 점을 찾으면, 그때 $\log p(x)$와 이 같아질 것으로 생각할 수 있습니다.
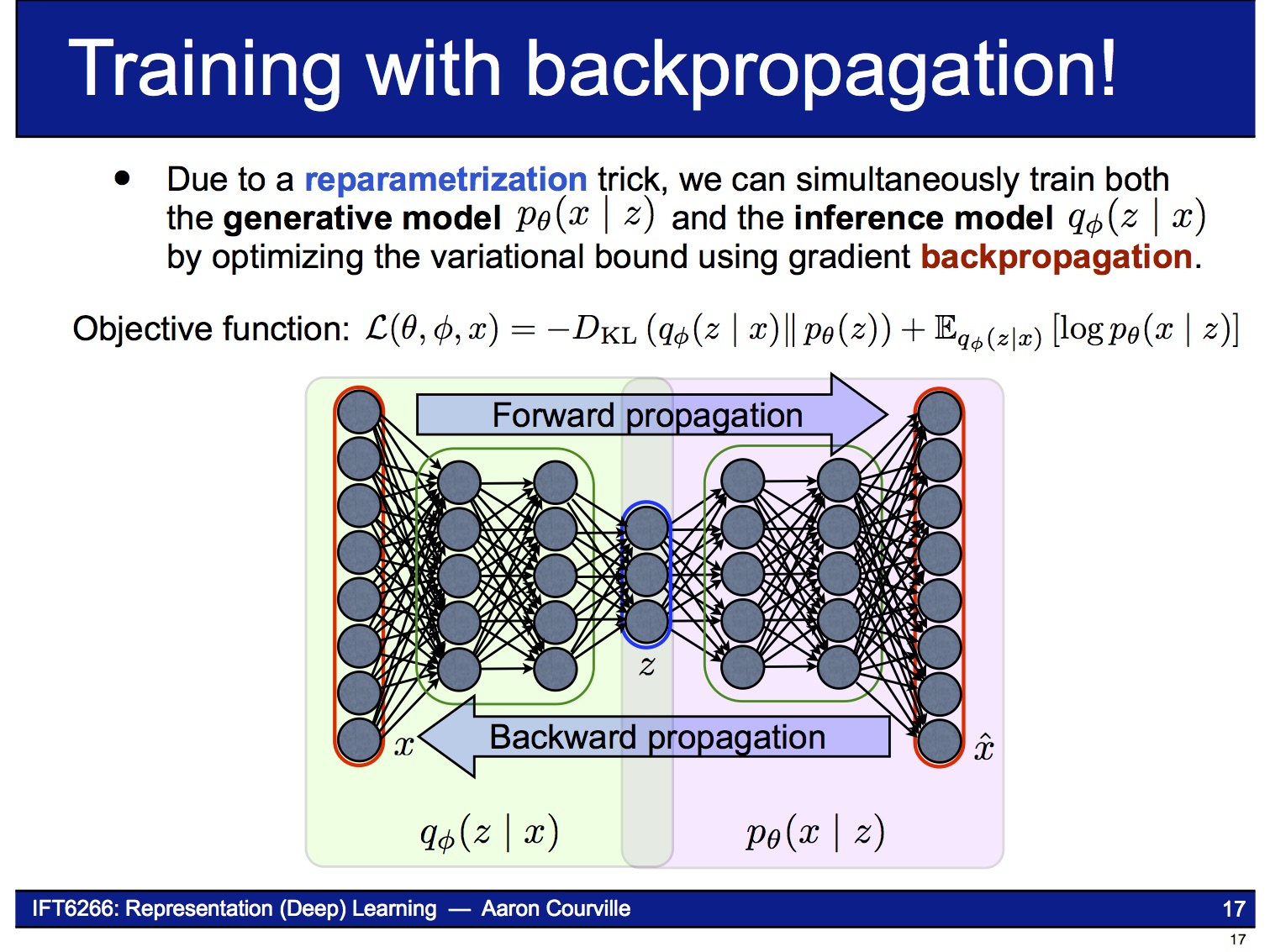
Maximize하는 문제라면 neural network를 만들어서 gradient-ascent 알고리즘으로 풀 수 있습니다. 그런데, 한 가지 문제가 있습니다.
Decoder에 latent variable $z$를 넣으려면 $z$가 random variable이므로 sampling을 해야하는데, sampling은 미분 가능하지가 않아서 gradient를 구할 수 없습니다.
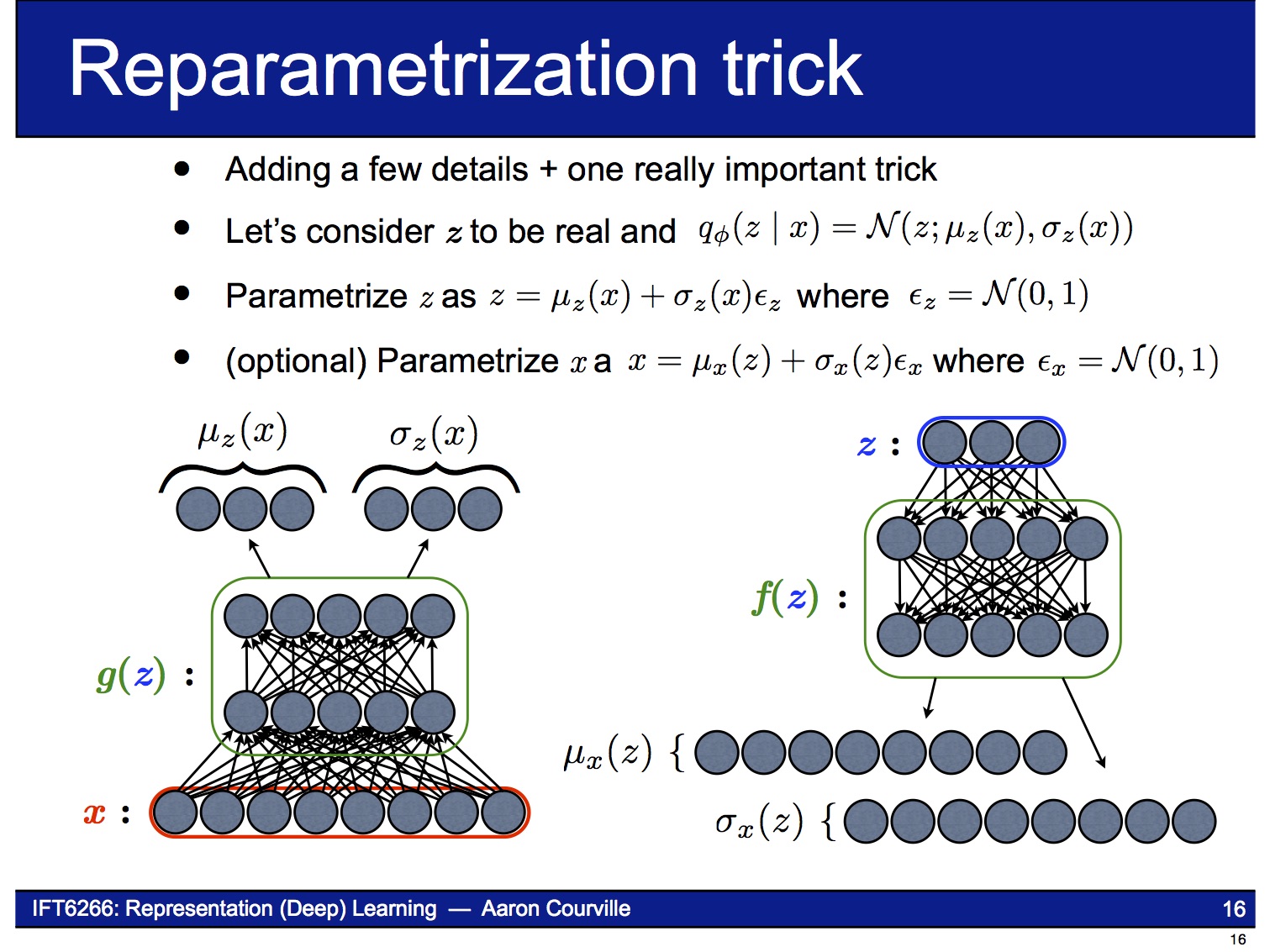
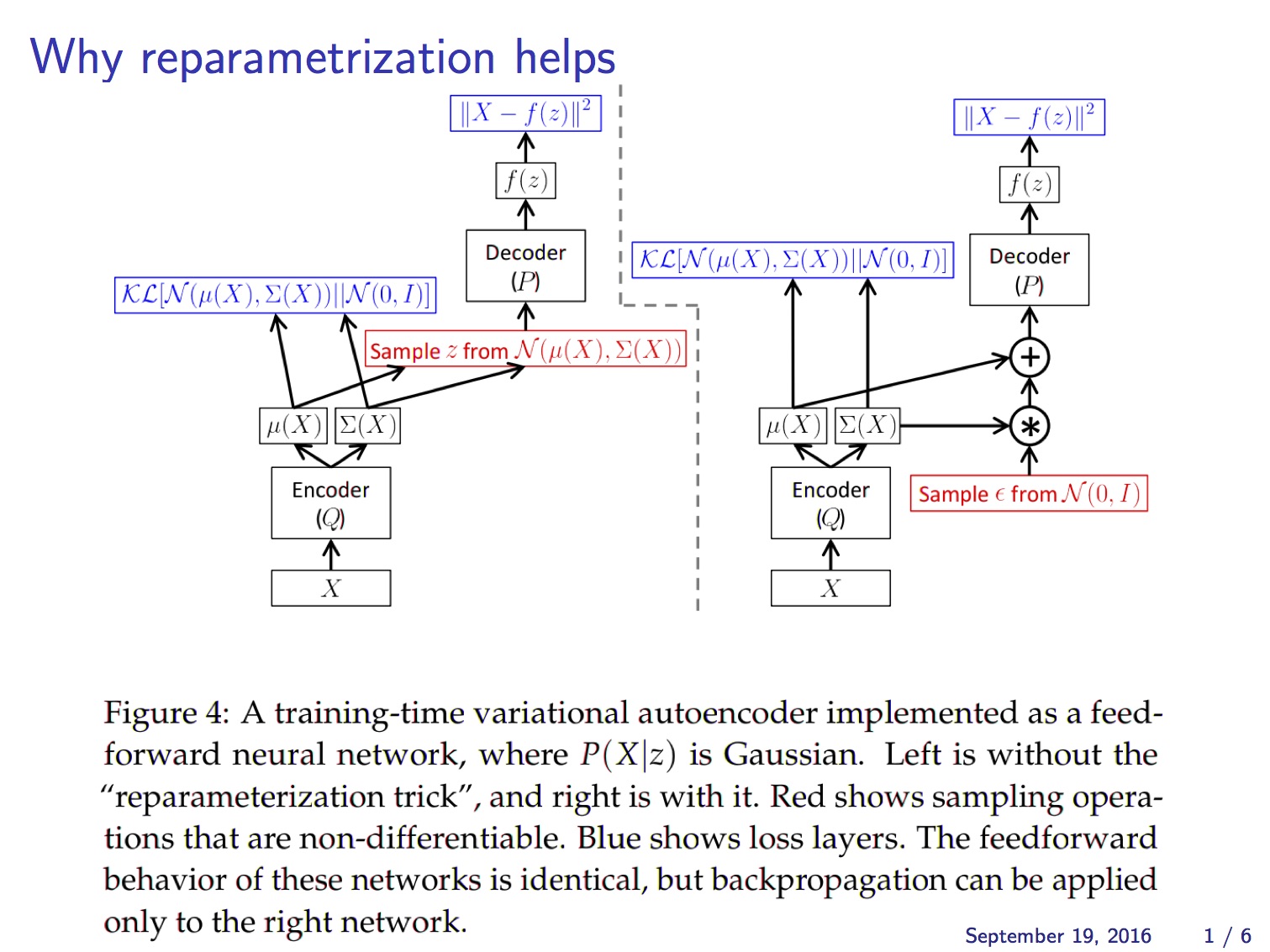
이 문제를 해결하기 위해 reparameterization trick이라는 기법을 사용합니다. 이 기법은 $z$의 stochastic한 성질을 마치 자기 자신은 deterministic한데 외부에서 random noise $\epsilon$이 입력되는 것처럼 바꿔 버립니다. 즉 이제 VAE는 parameter $\phi$ (= $\mu_z (x)$, $\sigma_z (x)$)에 대해 end-to-end로 미분 가능한 시스템이 됩니다.
Putting it all together
아래 그림은 앞에서 설명한 reparameterization trick을 반영해서 VAE의 구조를 다시 그린 것입니다.
즉 이제 VAE는 end-to-end로 미분 가능한 시스템이 되어 backpropagation을 사용하여 gradient-ascent 문제를 풀 수 있습니다. 이때 object function은 앞의 (2)식에서 보인 가 됩니다.
(2)식의 의 RHS에서 첫 번째 항에 나오는 KL-divergence $\cal{D}_{KL}(q(z|x)||p(z))$는 적절한 가정을 하면 아래와 같이 analytic하게 풀 수가 있습니다. 이 항은 흔히 regularizer라고 부르는데, $p(z)$를 표현하기 위해 $q(z|x)$를 사용하면 얼마나 많은 정보가 손실되는 지를 측정합니다. 쉽게 말해 $q(z|x)$가 $p(z)$에 얼마나 가까운지를 측정하는 measure라고 보시면 되겠습니다.
한편, (2)식의 의 RHS에서 두 번째 항인 도 어디서 많이 본 것 같은 모양입니다. 이 항은 (negative) reconstruction loss라고 부르는데, 얼마나 출력값이 입력값을 잘 따라가는 지를 측정합니다.
MNIST 같은 image 데이터를 사용한다면, ($p(x|z)$는 Bernoulli 분포, $q(z|x)$는 Gaussian 분포라고 가정하고) reconstruction loss를 입출력 image간의 binary cross-entropy로 계산할 수 있습니다. Binary cross-entropy를 수식대로 계산할 수도 있지만 Keras에서는 함수로 제공하기도 합니다.
정리하자면, 는 아래와 같이 쉽게 계산됩니다. (주의: gradient-descent로 계산하기 위해 부호가 반대로 바뀌었습니다.) 이 코드는 Agustinus Kristiadi의 블로그에서 인용했습니다.
defvae_loss(y_true,y_pred):""" Calculate loss = reconstruction loss + KL loss for each data in minibatch """# E[log P(X|z)]recon=K.sum(K.binary_crossentropy(y_pred,y_true),axis=1)# D_KL(Q(z|X) || P(z|X)); calculate in closed form as both dist. are Gaussiankl=0.5*K.sum(K.exp(log_sigma)+K.square(mu)-1.-log_sigma,axis=1)returnrecon+kl
전체 VAE의 계산 알고리즘은 아래와 같습니다.
다음은 MNIST 대상의 실험 결과를 보여주는 동영상들입니다.
VAE에 대한 평가
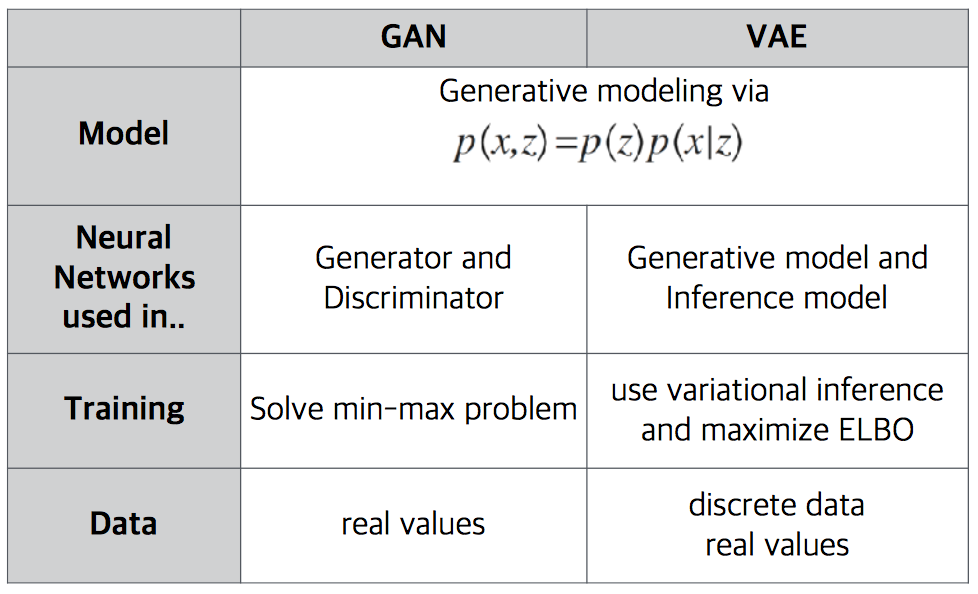
지금까지 VAE는 아래와 같은 평가를 받고 있습니다. 주로 GAN과 비교되는 것은 어쩔 수가 없는 것 같습니다.
후속 연구로 이 논문의 저자들은 VAE를 classification 문제로 확장해 semi-supervised learning에 적용하는 논문 “Semi-Supervised Learning with Deep Generative Models”(NIPS '14)을 냈습니다. 또한, 최근 가장 많이 사용되는 optimizer인 Adam을 2015년에 발표하기도 했습니다. 이 논문들에 대해서는 나중에 다른 post에서 소개 드리겠습니다.
논문의 내용에 들어가기 전에, 먼저 아래와 같은 간단한 개념을 이해하는 것이 도움이 됩니다. Google과 같은 큰 회사에서 machine learning으로 어떤 서비스를 만든다고 가정한다면, 개발 단계에 따라 training에 사용되는 모델과 실제 서비스로 deploy되는 모델에 차이가 있을 수 밖에 없을 것입니다. 즉, training에 사용되는 모델은 대규모 데이터를 가지고 batch 처리를 할 수 있고, 리소스를 비교적 자유롭게 사용할 수 있으며 최적화를 위해 비슷한 여러 변종이 존재할 수 있습니다. 반면, 실제 deployment 단계의 모델은 데이터의 실시간 처리가 필요하고 리소스에 제약을 받으며 빠른 처리가 중요합니다.
이 두가지 단계의 모델을 구분하는 것이 이 논문에서 중요한데, 그때 그때 다른 이름으로 부르기 때문에 논문 읽기가 쉽지 않습니다. 편의를 위해 아래에서 저는 그냥 1번 모델, 2번 모델로 부르겠습니다.
#
model
stage
structure
characteristic
meaning
1
“cumbersome model”
training
large ensemble
slow, complex
teacher
2
“small model”
deployment
single small
fast, compact
student
머신 러닝 알고리즘의 성능을 올리는 아주 쉬운 방법은, 많은 모델을 만들어 같은 데이터로 training한 다음, 그 prediction 결과 값을 average하는 것입니다. 이 많은 모델의 집합을 ensemble이라고 부르며, 위의 표에서 1번 모델에 해당합니다.
하지만 실제 서비스에서 사용할 모델은 2번이므로 어떻게 1번의 training 결과를 2번에게 잘 가르치느냐 하는 문제가 생깁니다.
이 논문의 내용을 한 문장으로 말하자면, 1번 모델이 축적한 지식(“dark knowledge”)을 2번 모델에 효율적으로 전달하는 (기존 연구보다 더 general한) 방법에 대한 설명이라고 할 수 있습니다.
이 논문은 크게 두 부분으로 나뉘어집니다.
Model Compression: 1번 ensemble 모델의 지식을 2번 모델로 전달하는 방법
Specialist Networks: 작은 문제에 특화된 모델들을 training시켜 ensemble의 training 시간을 단축하는 방법
Model Compression
핵심 아이디어는 1번 모델이 training되고 난 다음, 그 축적된 지식을 distillation이라는 새로운 training을 사용해서 2번 모델에 전달하겠다는 것입니다. 비슷한 아이디어가 2006년에 Caruana 등에 의해 발표된 적이 있는데, Hinton의 이 논문에서는 그 연구가 자신들이 주장하는 방법의 special case임을 보입니다.
1번 모델로 training을 하게 되면 주어진 데이터 셋에 대한 결과 prediction의 분포를 얻을 수 있습니다. Neural network에서 마지막 단에서는 대개 softmax function을 사용하기 때문에, 가장 확률이 높은 경우가 1로, 나머지는 0으로 마치 one-hot encoding처럼 만들어진 결과를 얻게 됩니다. 저자들은 그런 형태의 결과를 hard target이라고 부르면서, 1과 0으로 변환되기 전의 실수 값(soft target)을 사용하는 것이 2번 모델로 지식을 전달하는데 효과적이라고 주장합니다.
즉, 1번 모델의 결과로 나온 soft target 분포를 목표로 2번 모델을 train시키면 1번 모델이 학습한 지식을 충분히 generalize해서 전달할 수 있다는 것입니다. 상식적으로 0/1 보다 실수 값에 정보가 많이 들어있으니 당연한 것처럼 생각되기도 합니다.
이를 위해 Hinton 교수는 temperature $T$가 parameter로 들어가는 아래와 같은 softmax 함수를 사용합니다. $T$를 1로 놓으면 보통 사용하는 softmax 함수가 됩니다.
이 식에서 분모는 확률 값을 0에서 1 사이 값으로 scaling해주기 위한 것이므로 신경 쓸 필요가 없고, 분자는 단순히 exponential 함수입니다. Temperature $T$ 값이 커지면(high temperature) exponential의 입력으로 들어가는 값이 작아지므로 결과값이 천천히 증가합니다. 즉 softmax 함수를 거칠 때 큰 값이 (다른 작은 값들보다) 더 커지는 현상이 줄어들어 결과의 분포는 훨씬 부드러운(softer) distribution이 됩니다. 아래 그림은 Hinton 교수의 “Dark Knowledge”라는 발표 슬라이드에서 인용했습니다.
논문에 상세히 나와있지는 않지만, 이 방법을 MNIST에 적용했을 때 놀랄 만큼 좋은 성능을 보였다고 합니다. 특히 일부러 숫자 3을 제외하고 training했는데도 테스트에서 98.6%의 정확도를 보였다고 하는군요.
Specialist Networks
1번 모델을 training할 때, 전체 data가 많으면 아무리 parallel training을 한다고 해도 많은 시간이 걸릴 수 밖에 없습니다. 이 논문에서는 혼동하기 쉬운 특별한 부분 집합에 대해서만 training하는 specialist 모델을 만들어 training을 효율적으로 할 수 있다고 주장합니다. 여기서 ‘혼동하기 쉬운 특별한 부분 집합’의 예로는, ImageNet에서 버섯이나 스포츠카만 모아놓은 데이터 셋을 들 수 있겠습니다.
이러한 특별한 부분 집합은 overfitting되기 쉽기 때문에, 각 specialist 모델은 일반적인 데이터 셋과 반반 섞은 데이터로 training합니다. Training후에는 specialist 데이터가 전체에서 차지하는 비율에 맞춰 결과 값을 scaling합니다.
결론 짓자면, 이 논문의 저자들은 사용하는 모델이 아무리 크고 복잡하더라도 실제 서비스로 deploy 못할까 봐 걱정할 필요가 없다고 합니다. 1번 모델에서 knowledge를 추출해서 훨씬 작은 2번 모델로 옮길 수 있기 때문이지요. 이 논문에서 specialist 모델에서 추출한 지식을 커다란 하나의 모델로 옮기는 방법은 나와있지 않습니다.
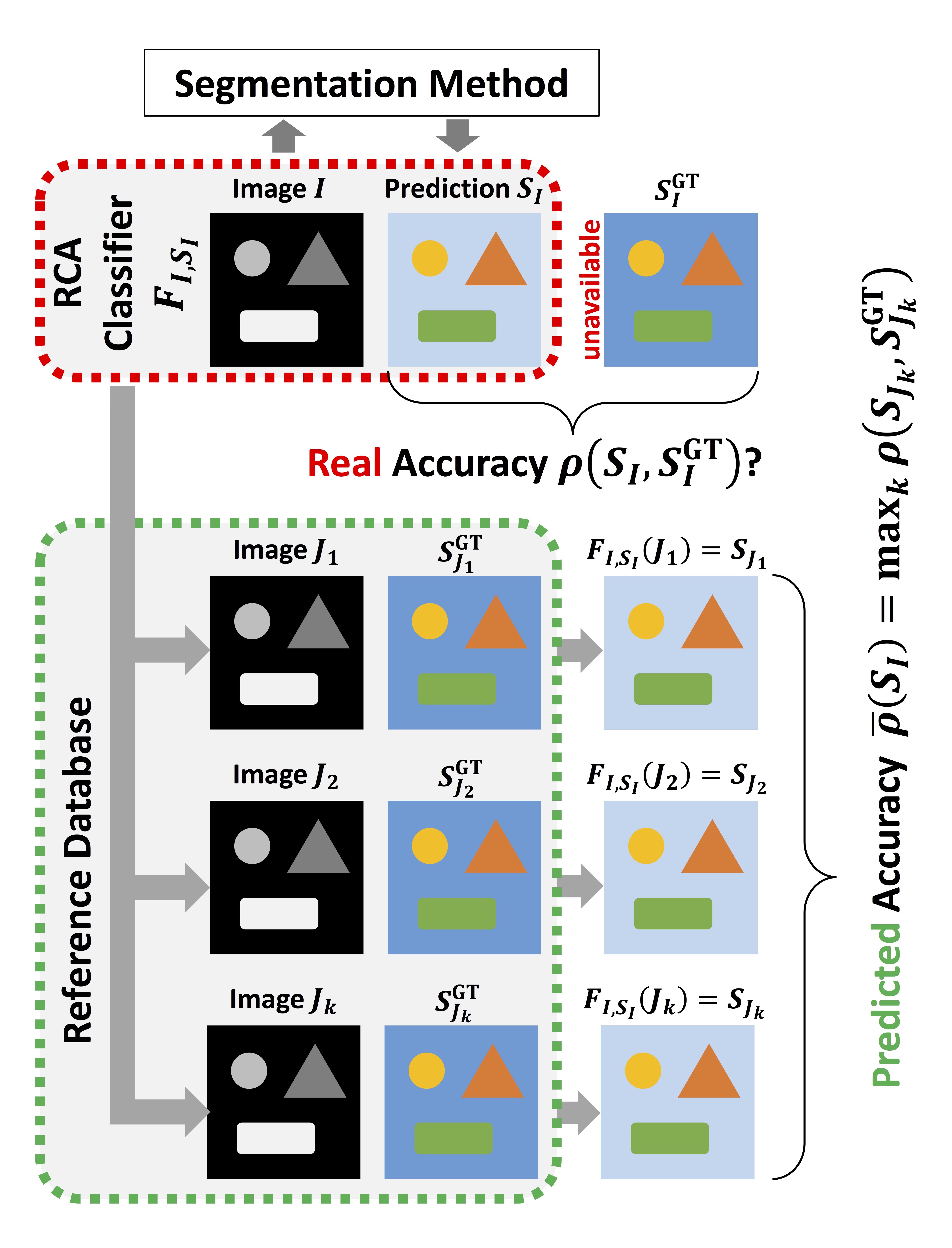
이를 위해 이 논문에서는 reverse classification accuracy (RCA)라는 개념을 도입합니다.
논문에는 명시적으로 나와있지는 않지만, 이 논문에서는 (임의의 방법으로 구현된) image segmentation을 하는 predictor가 이미 있음을 가정하고 있습니다. 이를 $P$, 입력 image를 $I$라고 하면 prediction된 출력 image $S_I$는 아래의 식과 같이 표현됩니다.
이 prediction이 얼마나 정확한지 평가하려면 accuracy $\rho(S_I, S_I^{GT})$를 계산하면 됩니다. (여기서 $\rho$는 DSC(Dice’s Similarity Coefficient)를 비롯한 임의의 evaluation metric일 수 있습니다.)
그런데, $I$에 대한 ground truth인 $S_I^{GT}$가 존재하지 않는 경우에는 $\rho$를 계산할 수가 없습니다. 그런 경우에 대신 사용할 proxy measure인 $\bar \rho$를 얻으려는 것이 이 논문의 목적입니다.
이를 위해, $I$와 $S_I$로부터 이 논문의 RCA classifier (= image segmenter) $F_{I,S_I}$를 마치 $S_I$가 pseudo ground truth인 것처럼 사용해서 training합니다. 다시 말해, test에서 생성된 prediction 값을 이용해 새로운 classifier를 만듭니다.
그 다음, 새로운 classifier $F_{I,S_I}$를 ground truth가 존재하는 reference database (= 일종의 training set으로 생각할 수 있습니다)에 적용합니다. 즉, m개의 ($J_k$, $S_{J_k}^{GT}$) reference data pair에 대해 $S_{J_k} = F_{I,S_I}(J_k)$를 구합니다. 그 다음, proxy measure인 $\bar \rho$를 아래 식과 같이 구해서 segmentation quality에 대한 추정치로 사용합니다.
아래는 지금까지 설명한 과정을 그림으로 표현한 것입니다.
실험 결과
이 논문에서는 segmentation의 evaluation metric을 $(S_{J}, S_{J}^{GT})$로 계산한 것과 $(S_{I}, S_{I}^{GT})$로 계산한 것 간에는 높은 correlation이 있다는 가정을 하고 있으며, 실험 결과로도 그 가정이 적절함을 보입니다.
또한, RCA로 prediction한 DSC 값 $\bar \rho$와 실제 DSC 값 $\rho$ 사이에 높은 유사성이 있는 것도 실험 결과에서 보입니다. 아래 그림은 MRI 이미지에서 간(liver)에 해당하는 영역을 segmentation하는 경우, 그 accuracy를 RCA를 통해 평가한 것입니다. 그림 아래 부분 24개의 reference data에서 추정한 DSC 값 $\bar \rho$가 0.898로, 실제 DSC 값 $\rho$ 0.894에 매우 근접하는 것을 볼 수 있습니다.

 (그림 출처: 한보형 님의 슬라이드 “Lecture 6: CNNs for Detection, Tracking, and Segmentation”)
(그림 출처: 한보형 님의 슬라이드 “Lecture 6: CNNs for Detection, Tracking, and Segmentation”) (그림 출처: PyImageSearch의 article “Histogram of Oriented Gradients and Object Detection”)
(그림 출처: PyImageSearch의 article “Histogram of Oriented Gradients and Object Detection”)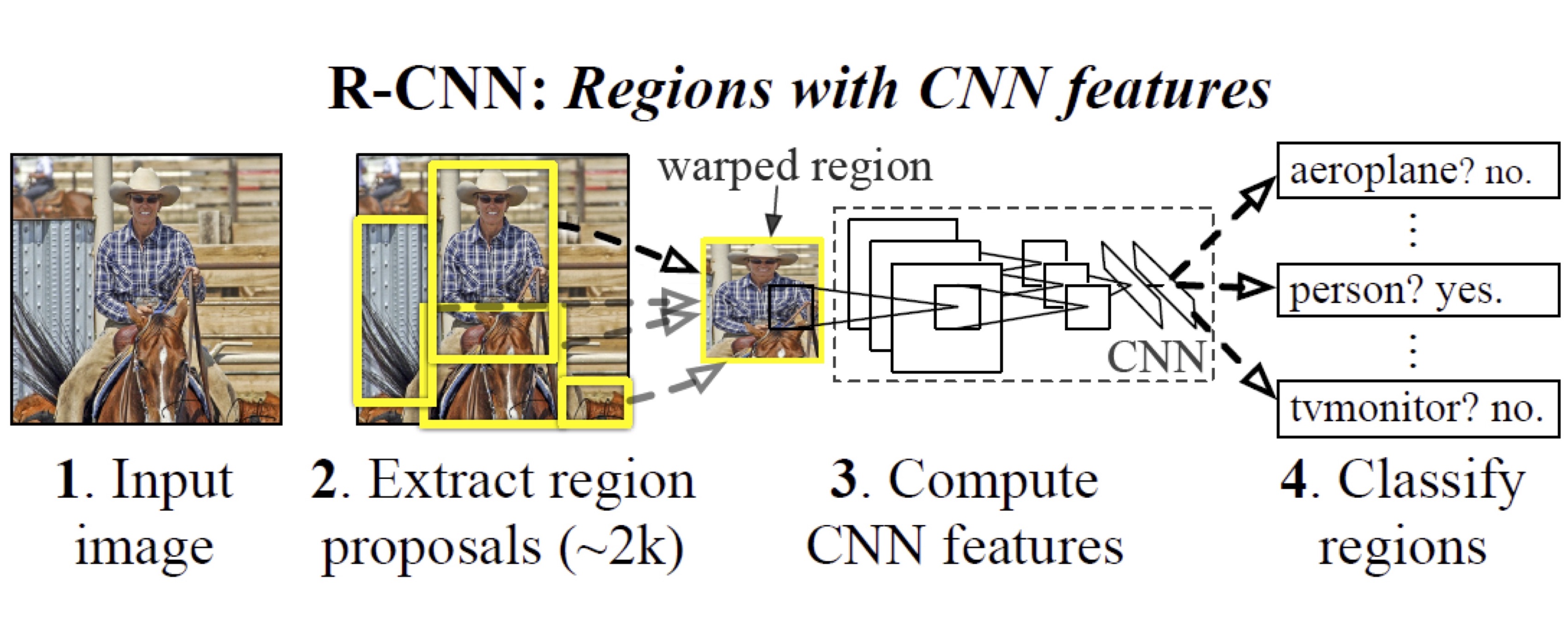
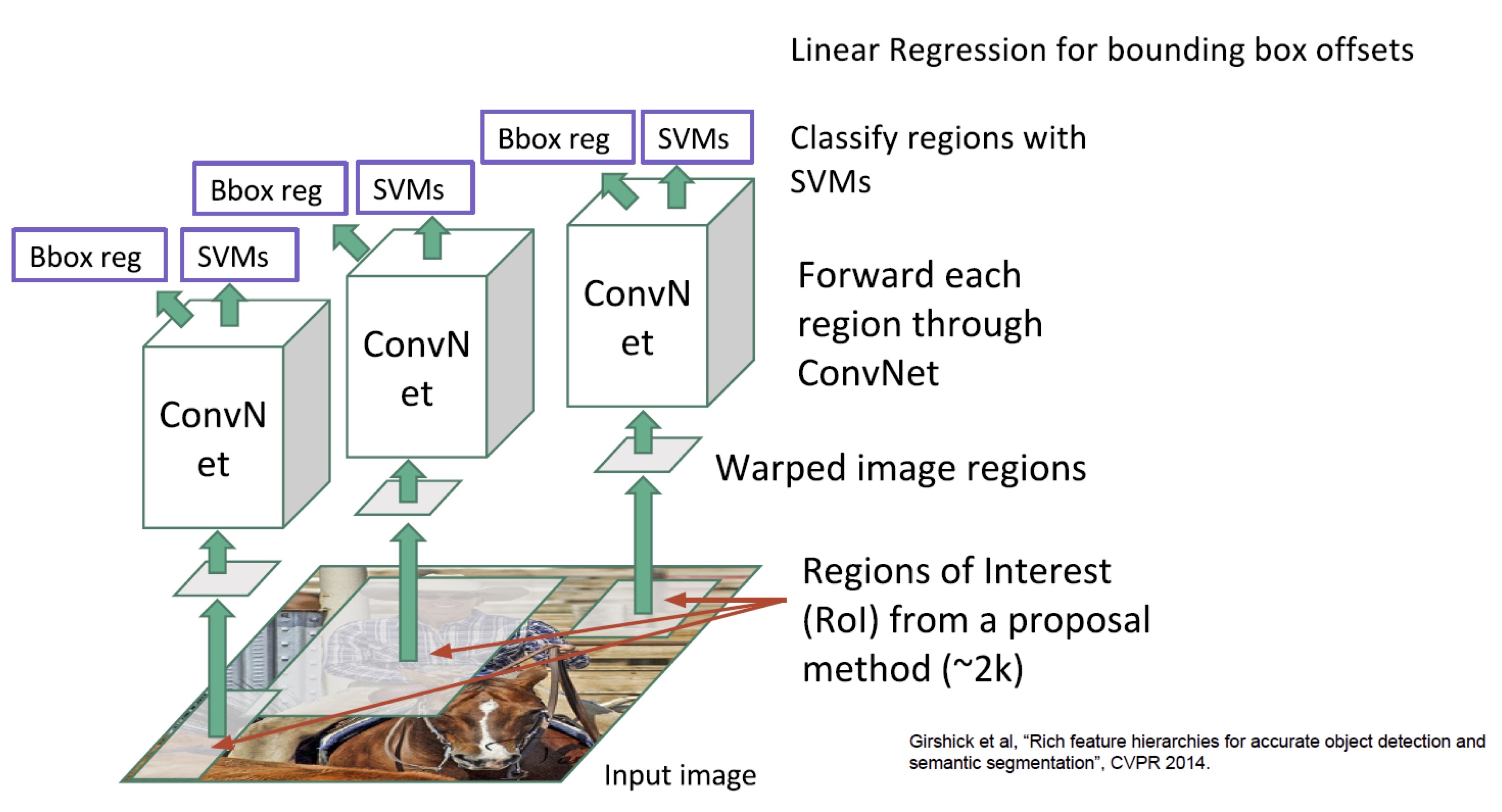
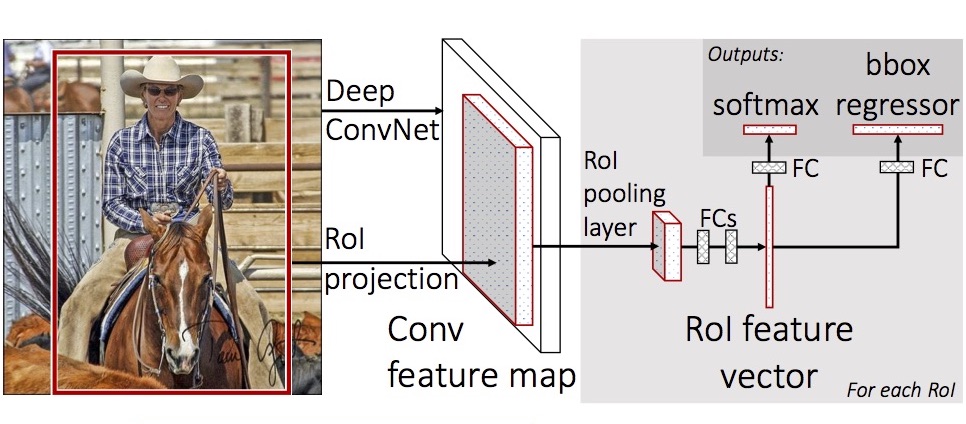
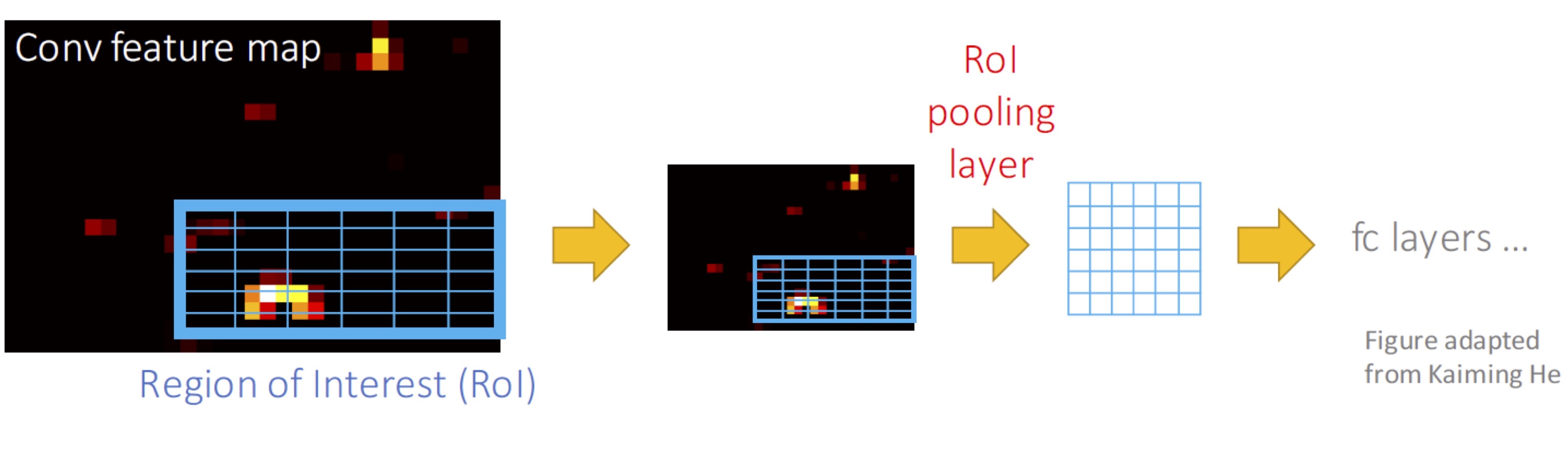 (그림 출처: 이진원 님의 발표 동영상)
(그림 출처: 이진원 님의 발표 동영상)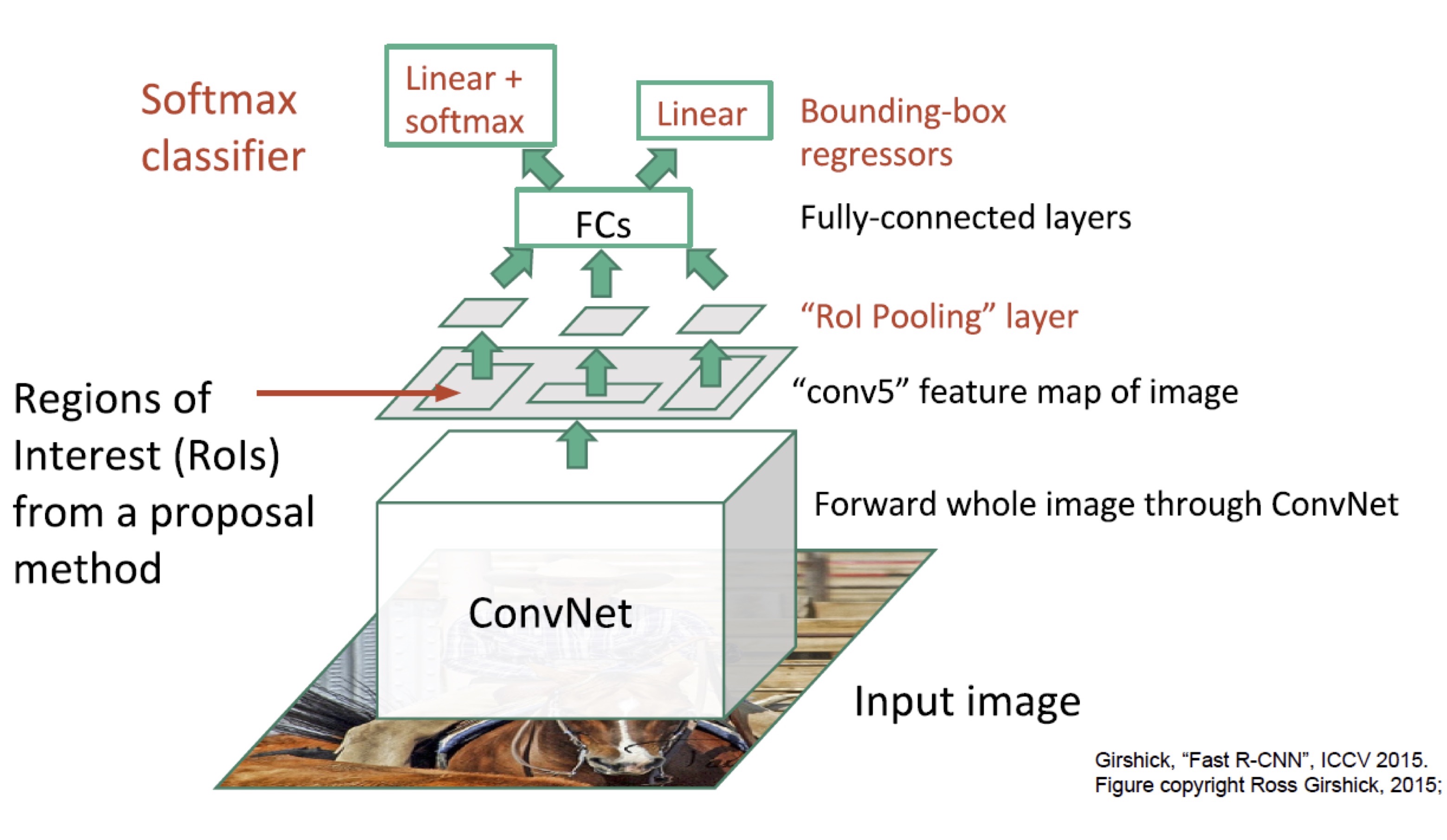
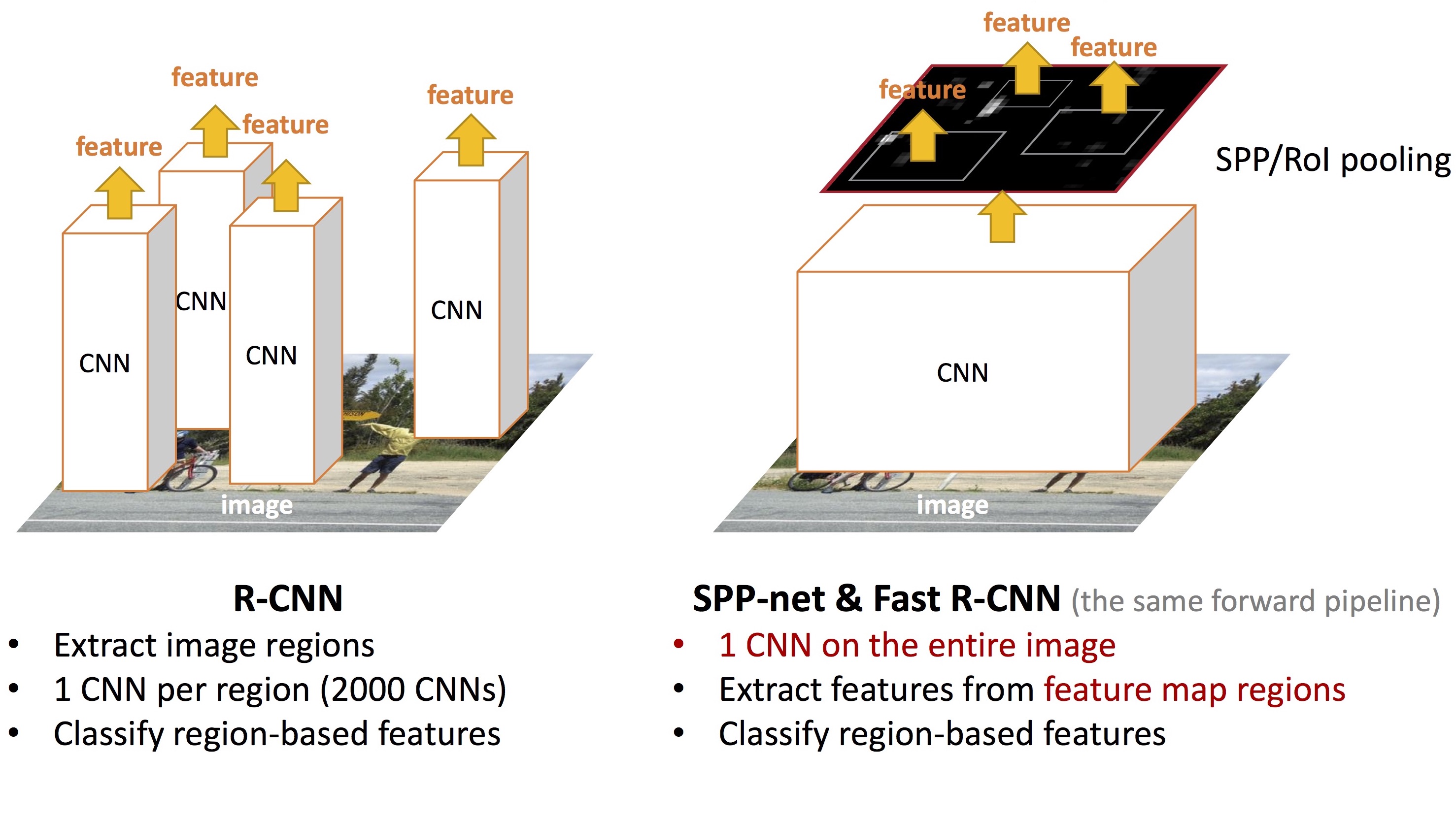 (그림 출처: Kaiming He의 ICCV 2015 Tutorial)
(그림 출처: Kaiming He의 ICCV 2015 Tutorial)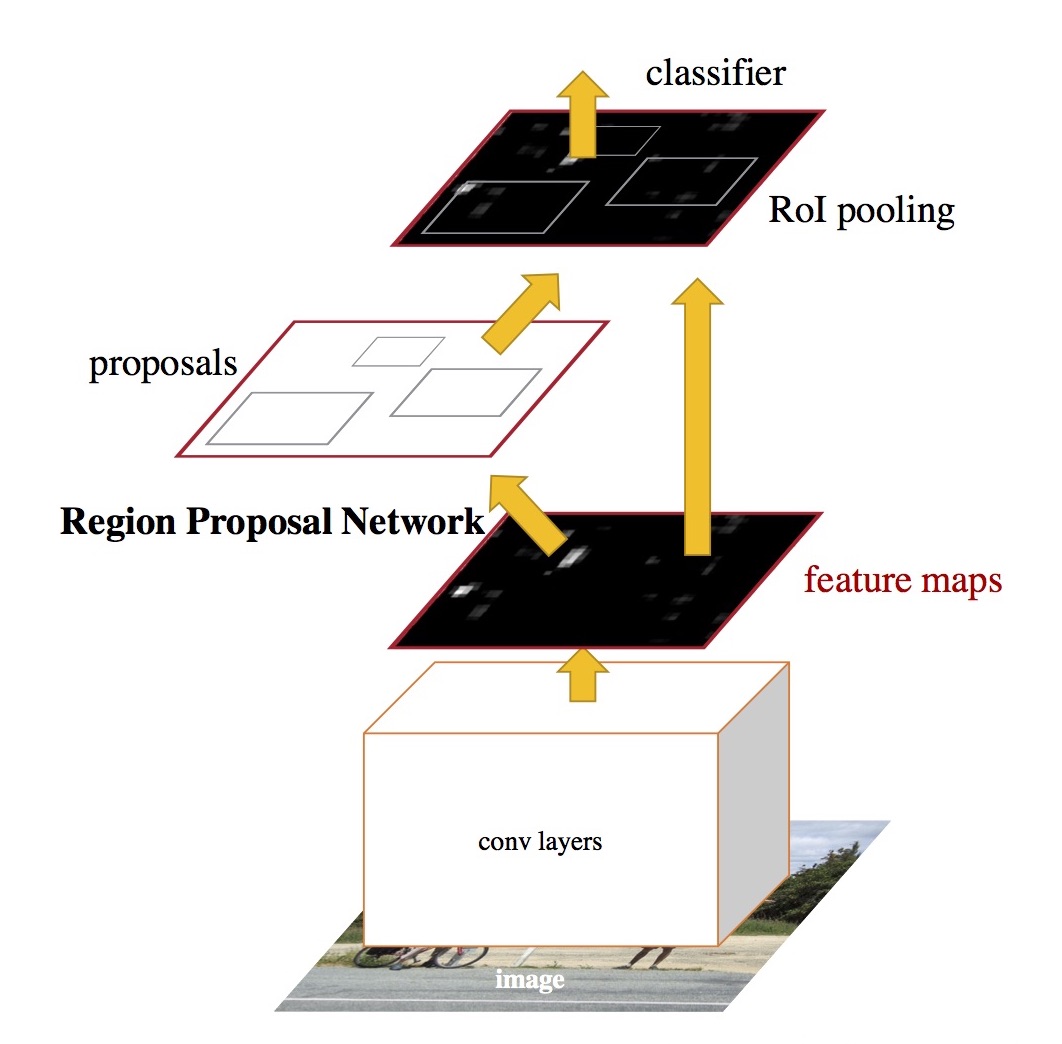
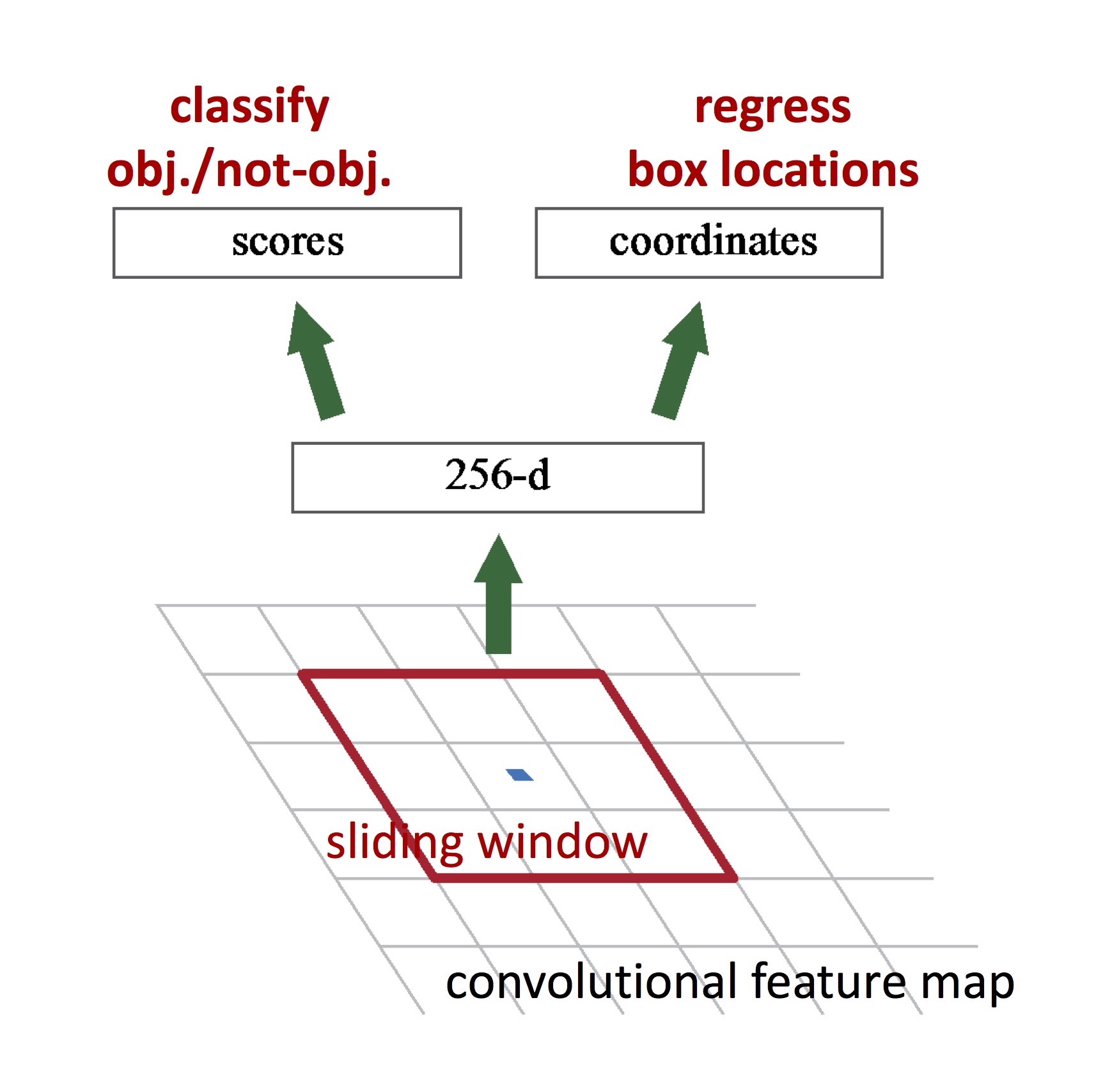 (그림 출처: Kaiming He의 ICCV 2015 Tutorial)
(그림 출처: Kaiming He의 ICCV 2015 Tutorial)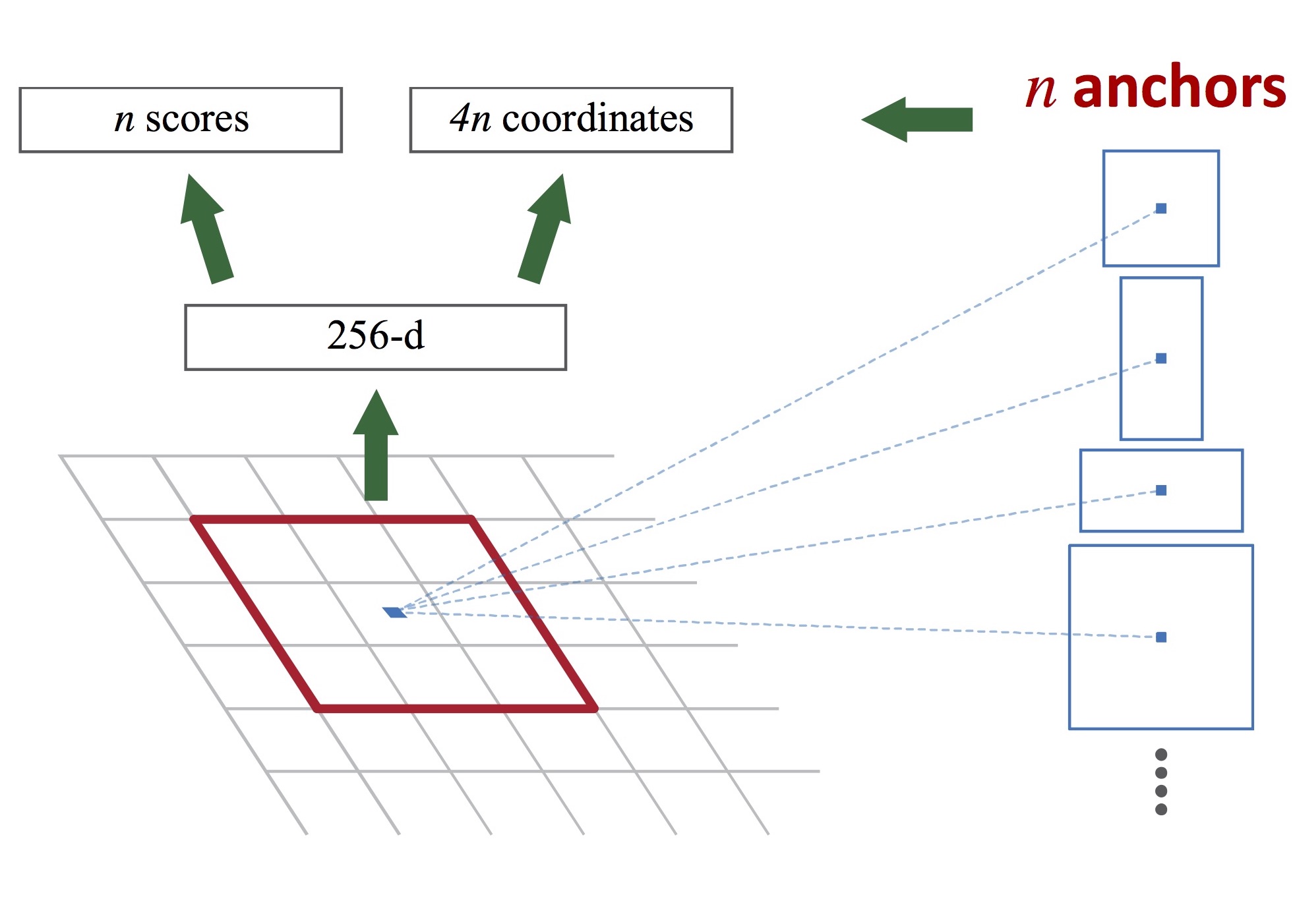
 (그림 출처: Stanford cs231n의 Lecture 8, “Spatial Localization and Detection”)
(그림 출처: Stanford cs231n의 Lecture 8, “Spatial Localization and Detection”)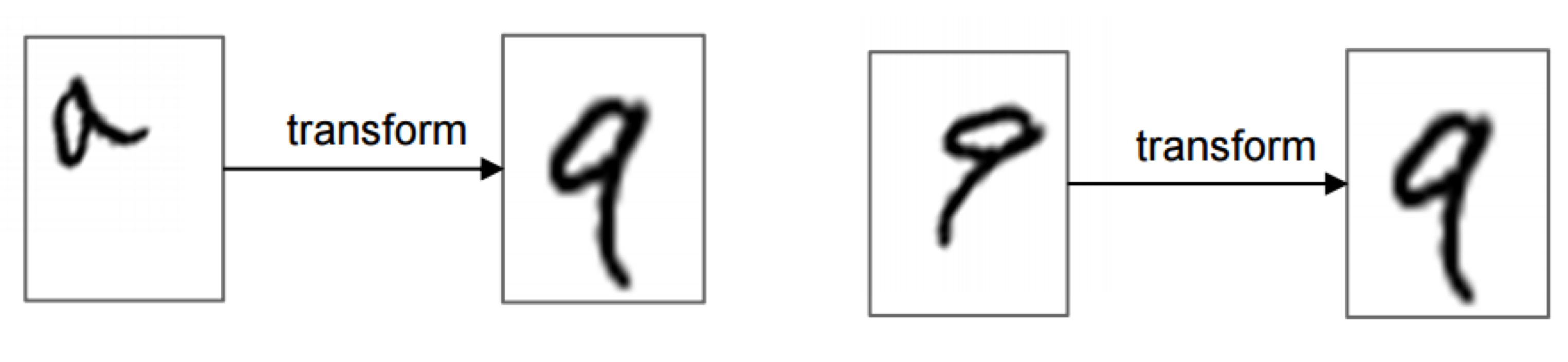
 (이 그림은
(이 그림은