Reverse Classification Accuracy
16 May 2017 | PR12, Paper, Machine Learning, Supervised Learning이번 논문은 2017년 2월에 공개된 “Reverse Classification Accuracy: Predicting Segmentation Performance in the Absence of Ground Truth”입니다. 흔히 말하는 ‘ground truth’ 데이터가 없을 때 performance를 측정하는 한 가지 방법을 제시하는 논문입니다. 이 논문이 다루는 의료 영상 분야의 image segmentation에서는 ground truth 데이터(예를 들면 MRI 영상에서 어느 부분이 어느 장기인지를 labeling한 데이터)를 얻기 위해 일일히 전문가의 수작업이 필요한 경우가 많다고 합니다.
RCA Algorithm
이를 위해 이 논문에서는 reverse classification accuracy (RCA)라는 개념을 도입합니다.
논문에는 명시적으로 나와있지는 않지만, 이 논문에서는 (임의의 방법으로 구현된) image segmentation을 하는 predictor가 이미 있음을 가정하고 있습니다. 이를 $P$, 입력 image를 $I$라고 하면 prediction된 출력 image $S_I$는 아래의 식과 같이 표현됩니다.
이 prediction이 얼마나 정확한지 평가하려면 accuracy $\rho(S_I, S_I^{GT})$를 계산하면 됩니다. (여기서 $\rho$는 DSC(Dice’s Similarity Coefficient)를 비롯한 임의의 evaluation metric일 수 있습니다.)
그런데, $I$에 대한 ground truth인 $S_I^{GT}$가 존재하지 않는 경우에는 $\rho$를 계산할 수가 없습니다. 그런 경우에 대신 사용할 proxy measure인 $\bar \rho$를 얻으려는 것이 이 논문의 목적입니다.
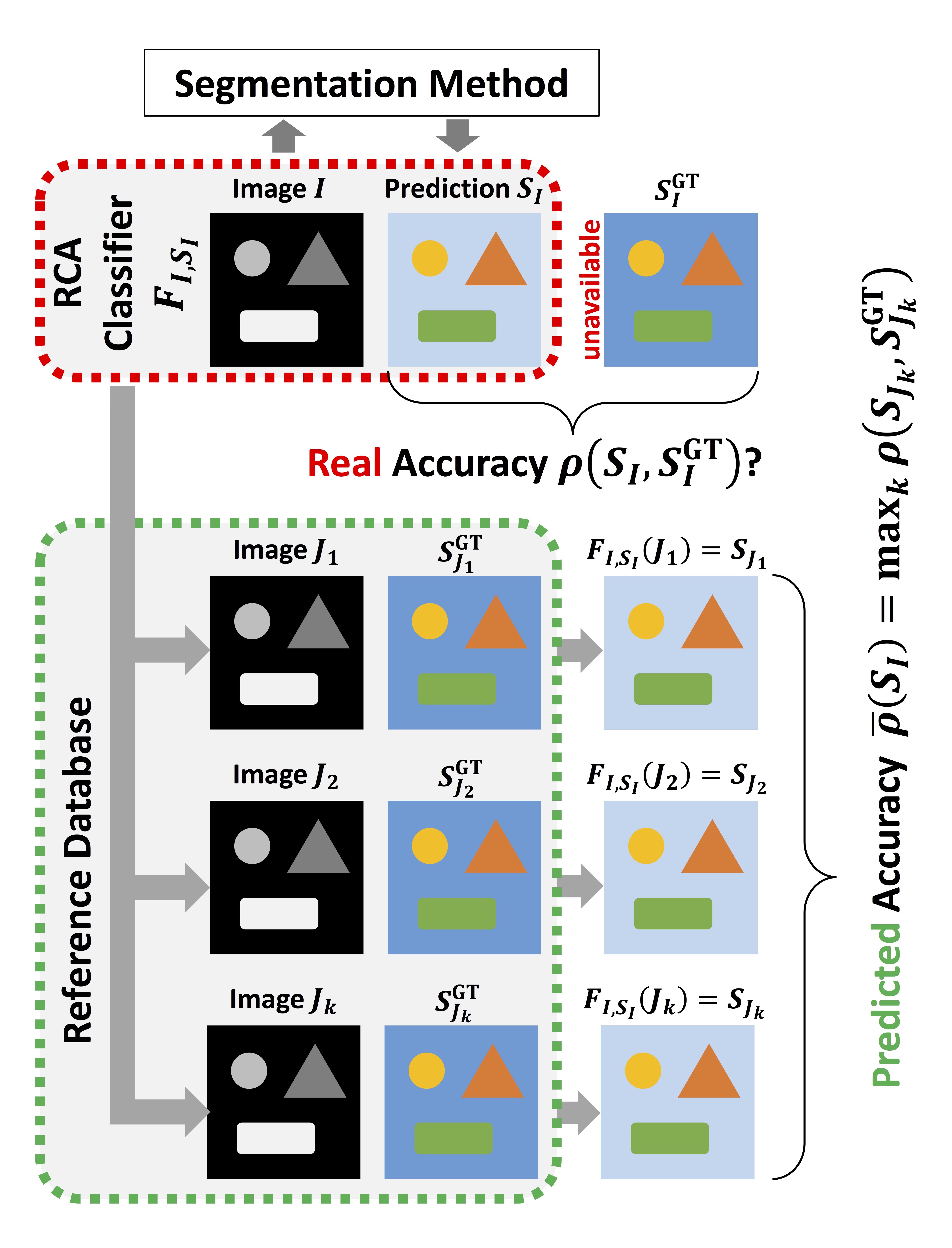
이를 위해, $I$와 $S_I$로부터 이 논문의 RCA classifier (= image segmenter) $F_{I,S_I}$를 마치 $S_I$가 pseudo ground truth인 것처럼 사용해서 training합니다. 다시 말해, test에서 생성된 prediction 값을 이용해 새로운 classifier를 만듭니다.
그 다음, 새로운 classifier $F_{I,S_I}$를 ground truth가 존재하는 reference database (= 일종의 training set으로 생각할 수 있습니다)에 적용합니다. 즉, m개의 ($J_k$, $S_{J_k}^{GT}$) reference data pair에 대해 $S_{J_k} = F_{I,S_I}(J_k)$를 구합니다. 그 다음, proxy measure인 $\bar \rho$를 아래 식과 같이 구해서 segmentation quality에 대한 추정치로 사용합니다.
아래는 지금까지 설명한 과정을 그림으로 표현한 것입니다.
실험 결과
이 논문에서는 segmentation의 evaluation metric을 $(S_{J}, S_{J}^{GT})$로 계산한 것과 $(S_{I}, S_{I}^{GT})$로 계산한 것 간에는 높은 correlation이 있다는 가정을 하고 있으며, 실험 결과로도 그 가정이 적절함을 보입니다.
또한, RCA로 prediction한 DSC 값 $\bar \rho$와 실제 DSC 값 $\rho$ 사이에 높은 유사성이 있는 것도 실험 결과에서 보입니다. 아래 그림은 MRI 이미지에서 간(liver)에 해당하는 영역을 segmentation하는 경우, 그 accuracy를 RCA를 통해 평가한 것입니다. 그림 아래 부분 24개의 reference data에서 추정한 DSC 값 $\bar \rho$가 0.898로, 실제 DSC 값 $\rho$ 0.894에 매우 근접하는 것을 볼 수 있습니다.
– Jamie;
References