You Only Look Once: Unified, Real-Time Object Detection
18 Jun 2017 | PR12, Paper, Machine Learning, CNN이번 논문은 2016년 CVPR에 발표된 “You Only Look Once: Unified, Real-Time Object Detection” 입니다.
Introduction
이 논문에서는 이미지의 bounding box를 실시간으로 검출할 수 있는 YOLO라는 새로운 네트워크 모델을 제안합니다.
YOLO는 object detection을 regression 문제로 접근하며, 별도의 region proposal을 위한 구조 없이 한 번에 전체 image로부터 어떤 object 들이 어디에 위치하고 있는지 예측할 수 있습니다.
YOLO는 초당 45 프레임, 단순화한 Fast YOLO는 초당 155 프레임을 처리할 정도로 매우 빠르지만, 정확도는 기존의 Faster R-CNN보다 약간 떨어지는 특성이 있습니다.
Unified Detection
기존의 Faster R-CNN을 비롯한 object detection 모델들은 Bounding Box (BBox)를 먼저 찾고 (region proposal), 각 BBox에 대해 classification을 하는 다단계 방식이었습니다.
하지만, YOLO는 모든 class에 대한 모든 BBox를 동시에 예측하기 때문에 매우 빠르고 global reasoning이 가능합니다.

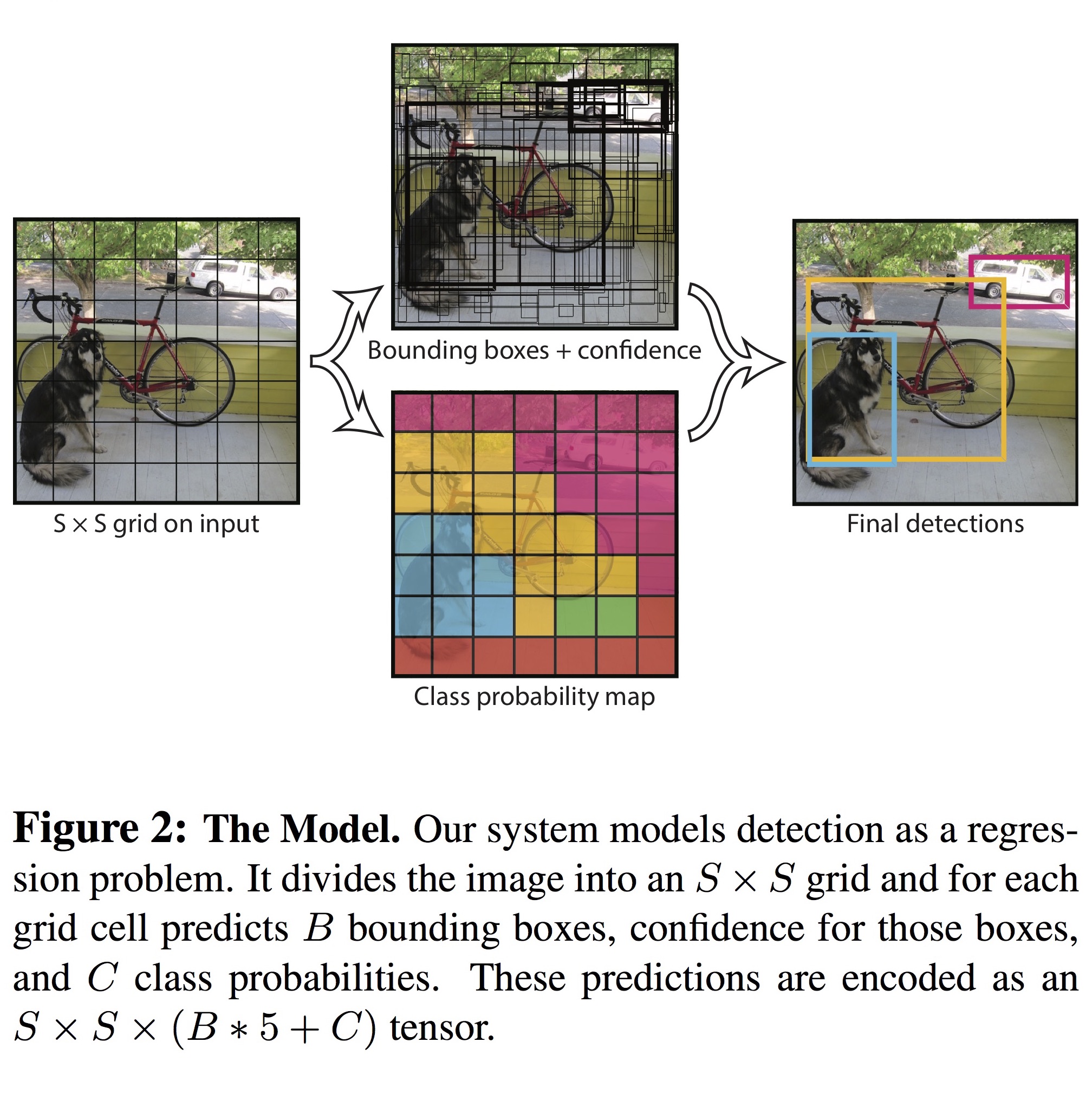
- 입력 이미지는 $448 \times 448$의 해상도를 가집니다.
- 각 이미지마다 출력은 $S \times S \times \left(B \times 5 + C \right)$ 개의 값으로 이뤄집니다.
- $S$는 grid size (default: 7)입니다. 각 이미지는 $S \times S$개의 cell로 나눠집니다.
- $B$는 각 cell 마다 테스트되는 Bounding Box (BB)의 개수이며 기본 값은 2입니다.
- 모델은 각 BB마다 위치 (x, y)와 크기 (height, width), 그리고 confidence value를 예측합니다.
- confidence value는 grid cell에 물체가 없으면 0, 있으면 예측된 BB와 실제 BB 사이의 IoU 값이 됩니다.
- $c$는 dataset의 class 개수로, Pascal VOC에서는 20이 됩니다.
Network Design
이 논문에서 사용한 neural network (YOLO) 는 Google이 ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014)에서 사용했던 GoogLeNet 을 변형한 구조입니다. 이 네트워크는 24개의 convolutional layer와 2개의 fully connected layer로 구성되어 있습니다. $1 \times 1$ reduction layer를 여러 번 적용한 것이 특징입니다.
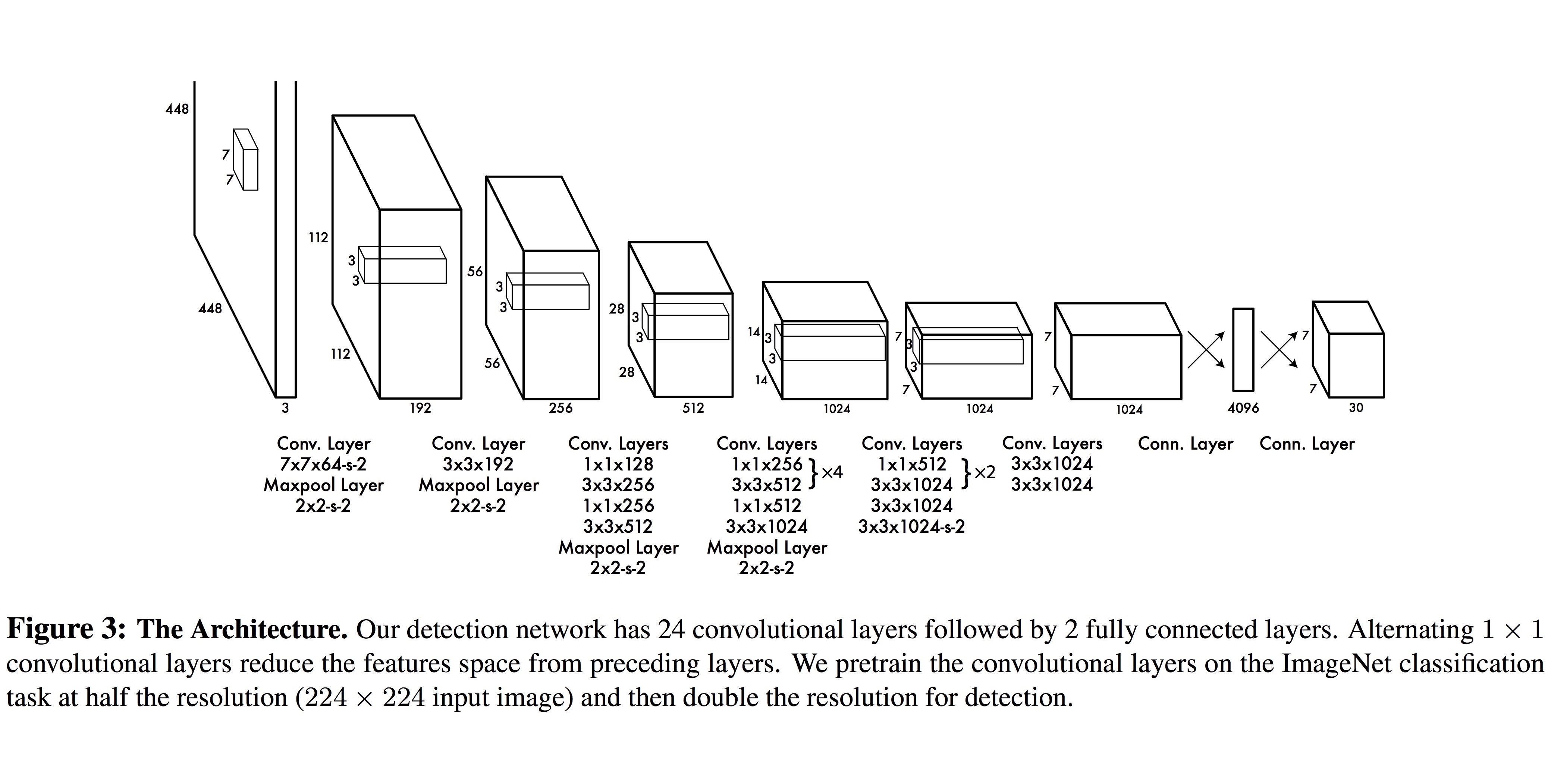
이 논문에서 사용한 또 하나의 neural network인 Fast YOLO는 9개의 convolutional layer와 더 적은 수의 filter만을 사용해 속도를 더 높이고 있습니다. 기타 training과 testing을 위한 파라미터는 YOLO와 동일합니다.
Linear activation function으로는 leaky ReLU ($\alpha = 0.1$)를 사용했습니다. Loss function은 기본적으로 sum-of-squared-error 개념이지만, object가 존재하는 grid cell과 object가 존재하지 않는 grid cell 각각에 대해 coordinates ($x$, $y$, $w$, $h$), confidence score, conditional class probability의 loss를 계산하기 때문에 아래와 같이 복잡한 식이 됩니다.
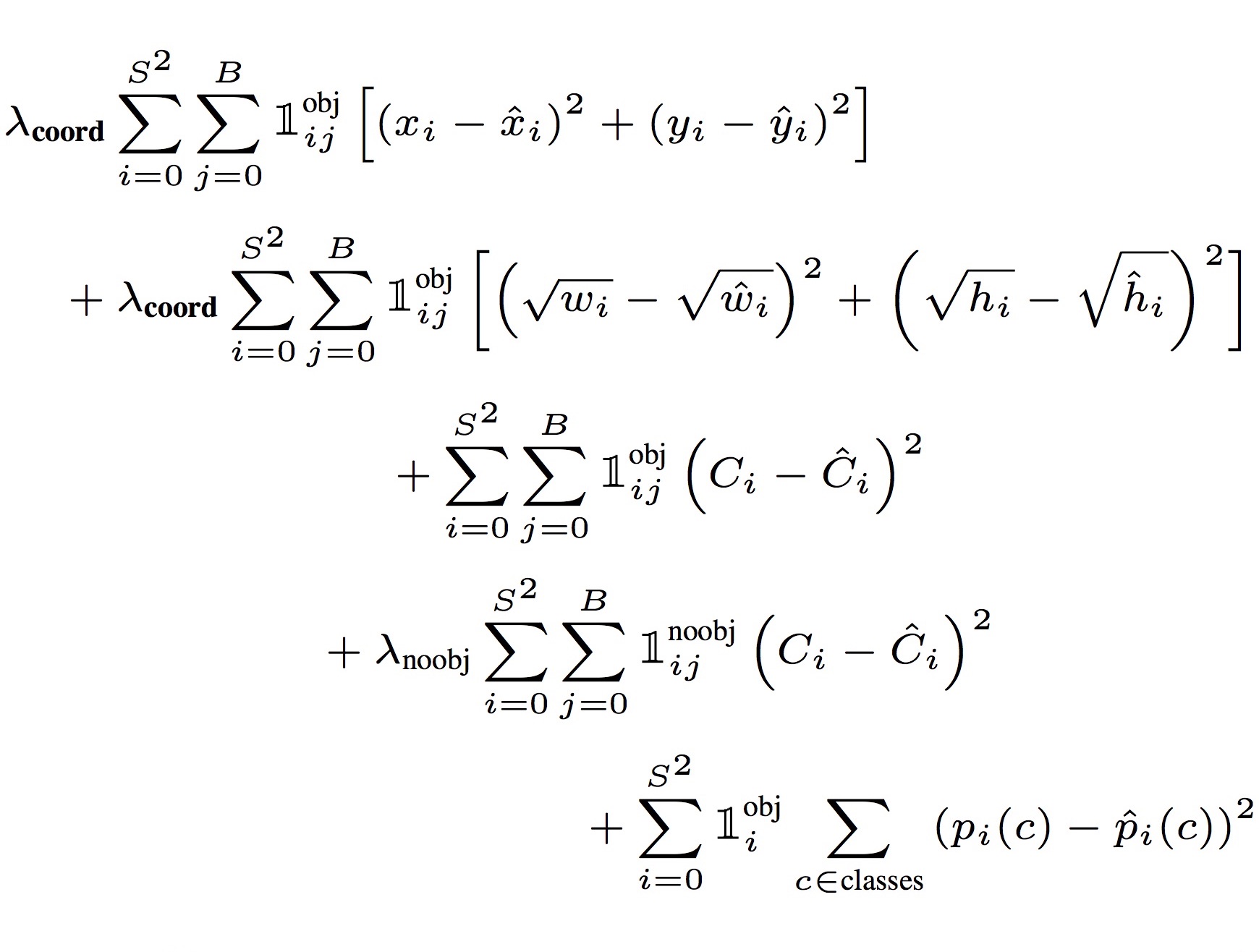
Training
이 논문의 실험에서 training은 먼저 ImageNet으로 pretraining을 하고 다음에 Pascal VOC에서 finetuning하는 2단계 방식으로 진행됐습니다. 학습에는 앞의 20개의 convolutional layer만을 사용했고 (feature extractor), 마지막 4개의 convolutional layer와 2개의 fully connected layer를 추가해서 (object classifier) 실제 object detection에 사용할 system을 구성합니다.
한 가지 특이한 점은, 저자들이 자신들이 직접 만든 Darknet이라는 framework를 사용했다는 점입니다.
Pascal VOC를 사용한 training에는 135번의 epoch, batch size 64, momentum 0.9, decay 0.0005, dropout rate 0.5를 각각 적용했습니다. Learning rate은 $10^{-3}$, $10^{-2}$, $10^{-3}$, $10^{-4}$으로 epoch에 따라 바꿔가며 사용했습니다.
Inference
이 논문에서 불필요한 중복 BBox들을 제거하기 위해 Non-maximal suppression이라는 개념이 중요하게 사용됩니다. Non-maximal suppression을 포함해 전체 YOLO 시스템의 동작은 Deepsystem.io의 슬라이드와 아래 동영상에 가장 잘 설명되어 있습니다.
Limitations of YOLO
YOLO가 사용하는 grid cell은 2개까지의 BBox와 1개의 class만을 예측할 수 있기 때문에 그에 따른 약점을 가지고 있습니다. 예를 들어 새 떼와 같이 작은 object들의 그룹이나 특이한 종횡비의 BBox는 잘 검출하지 못한다고 합니다.
Comparison to Other Detection Systems
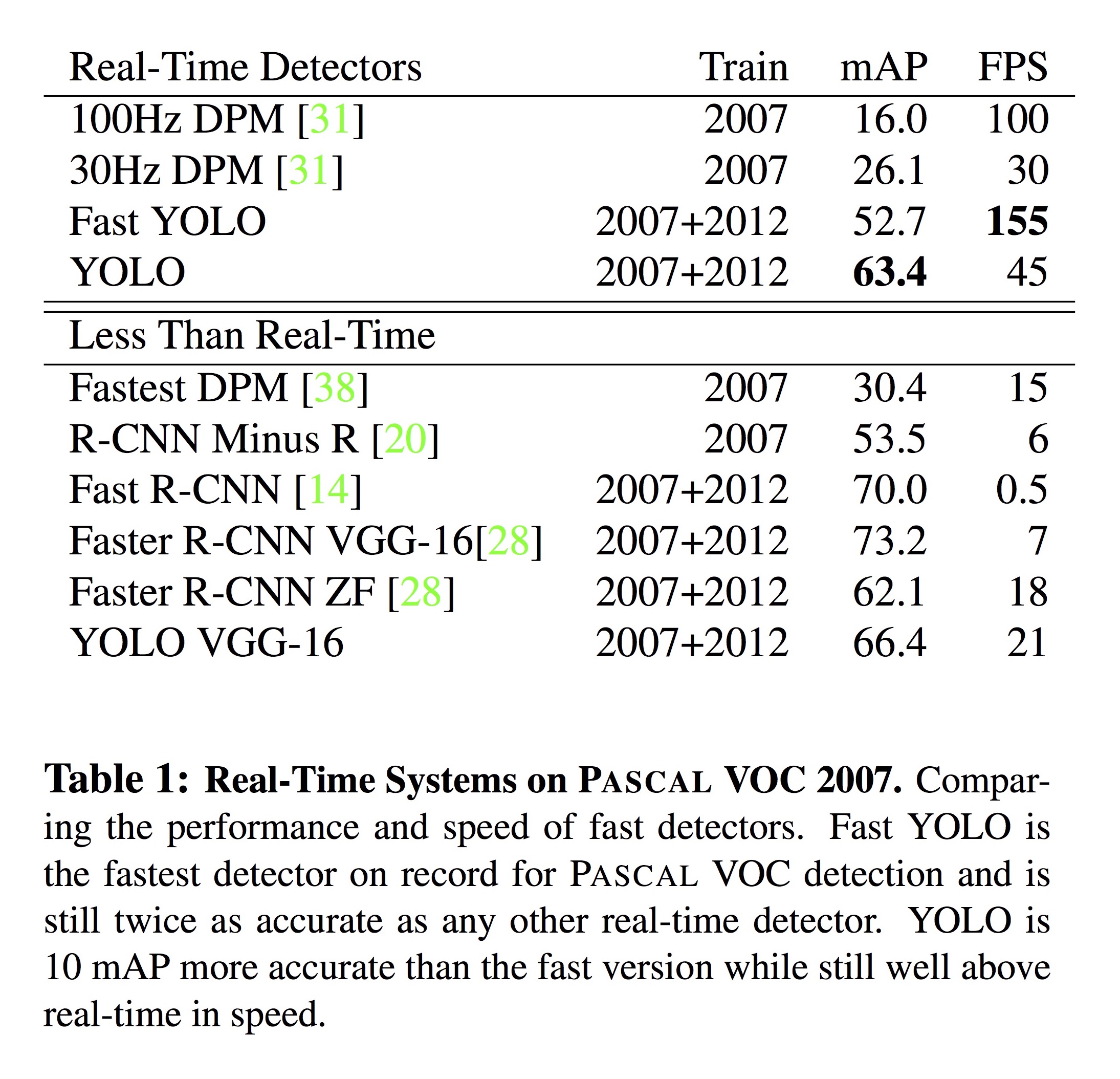
현재까지 발표된 다양한 object detection system과 비교한 실험 결과가 아래 표에 정리되어 있습니다. Fast YOLO는 155 fps로 가장 빠른 처리 성능을 보이고 있고, 표준 YOLO는 Fast YOLO보다 약간 느리면서 한편, 정확성을 나타내는 mAP 값이 Faster R-CNN과 유사한 수준을 보이고 있습니다.
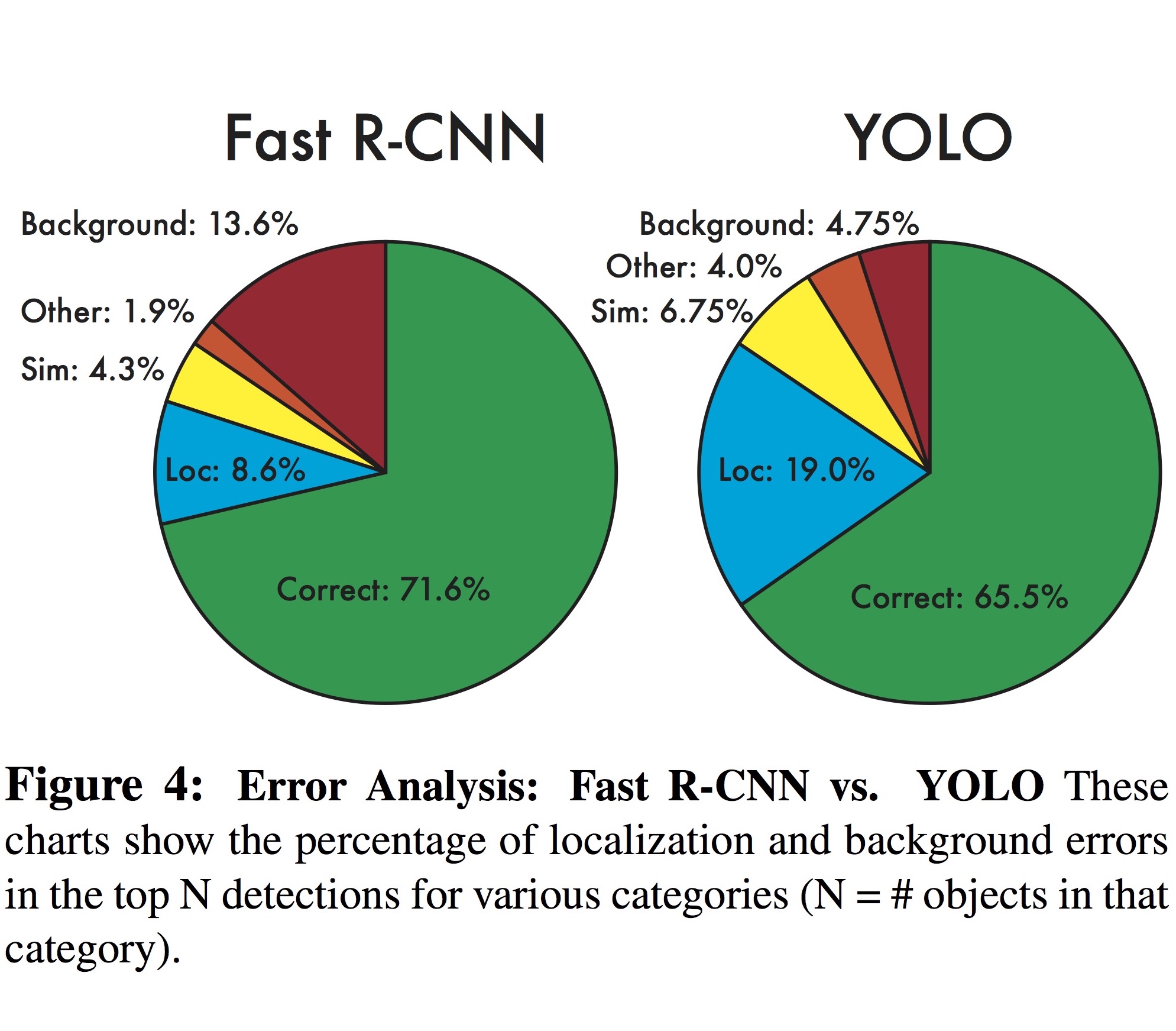
아래 그림은 Pascal VOC 2007에서 Fast R-CNN과 YOLO의 error를 분석한 것입니다. Fast R-CNN의 error는 background 영역에서 대부분 발생하는 한편, YOLO의 error는 localization에서 대부분 일어나는 것을 알 수 있습니다.
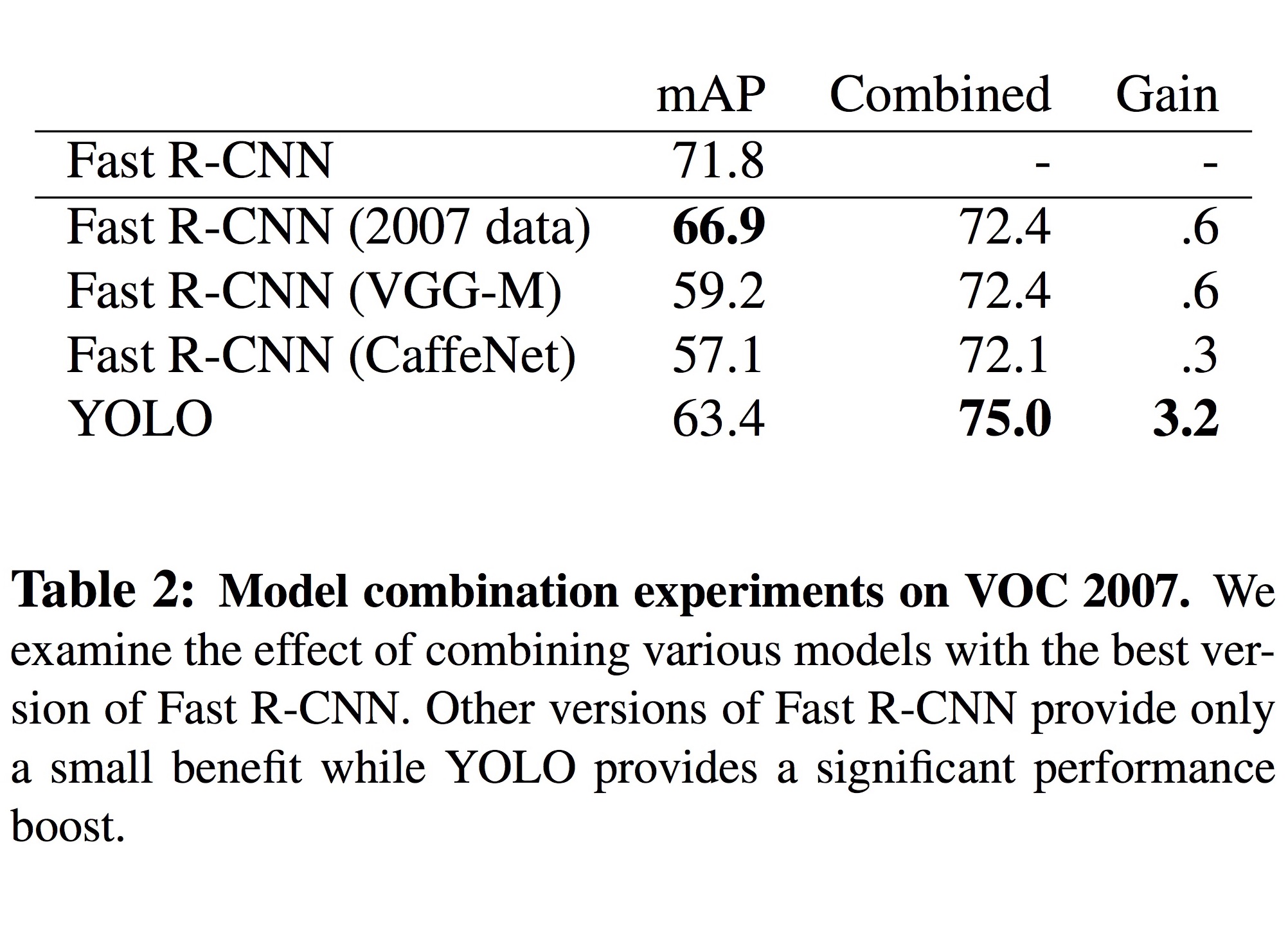
이와 같은 서로의 단점을 보완하기 위해, 두 모델을 함께 사용한 실험에서는 mAP 값이 71.8%에서 75.0%로 대폭 향상되었습니다.
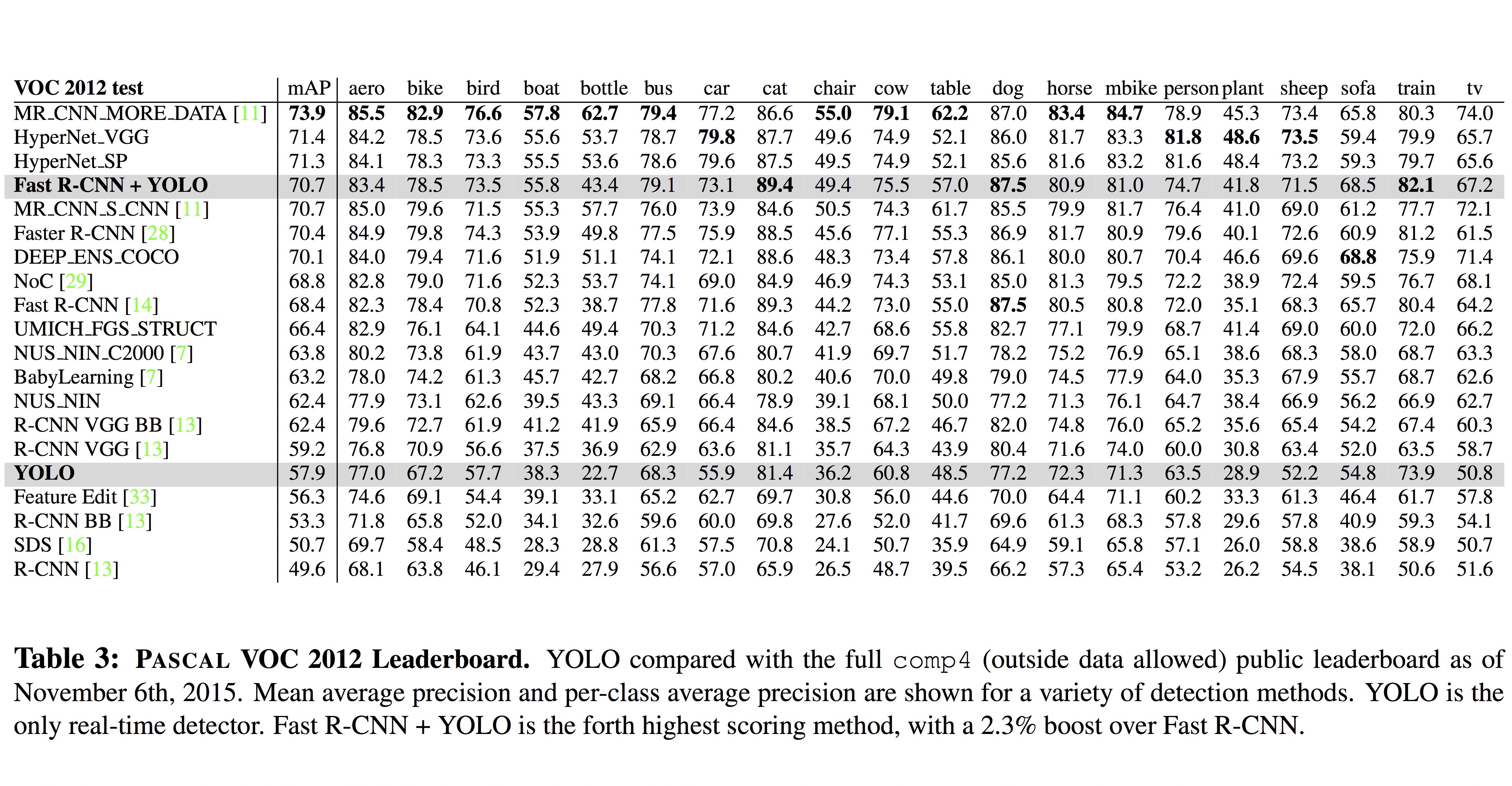
아래의 VOC 2012 테스트 표를 보면, 정확도 측면에서 Fast R-CNN과 YOLO의 조합은 최상위권에 위치하고 있는 것을 볼 수 있습니다.
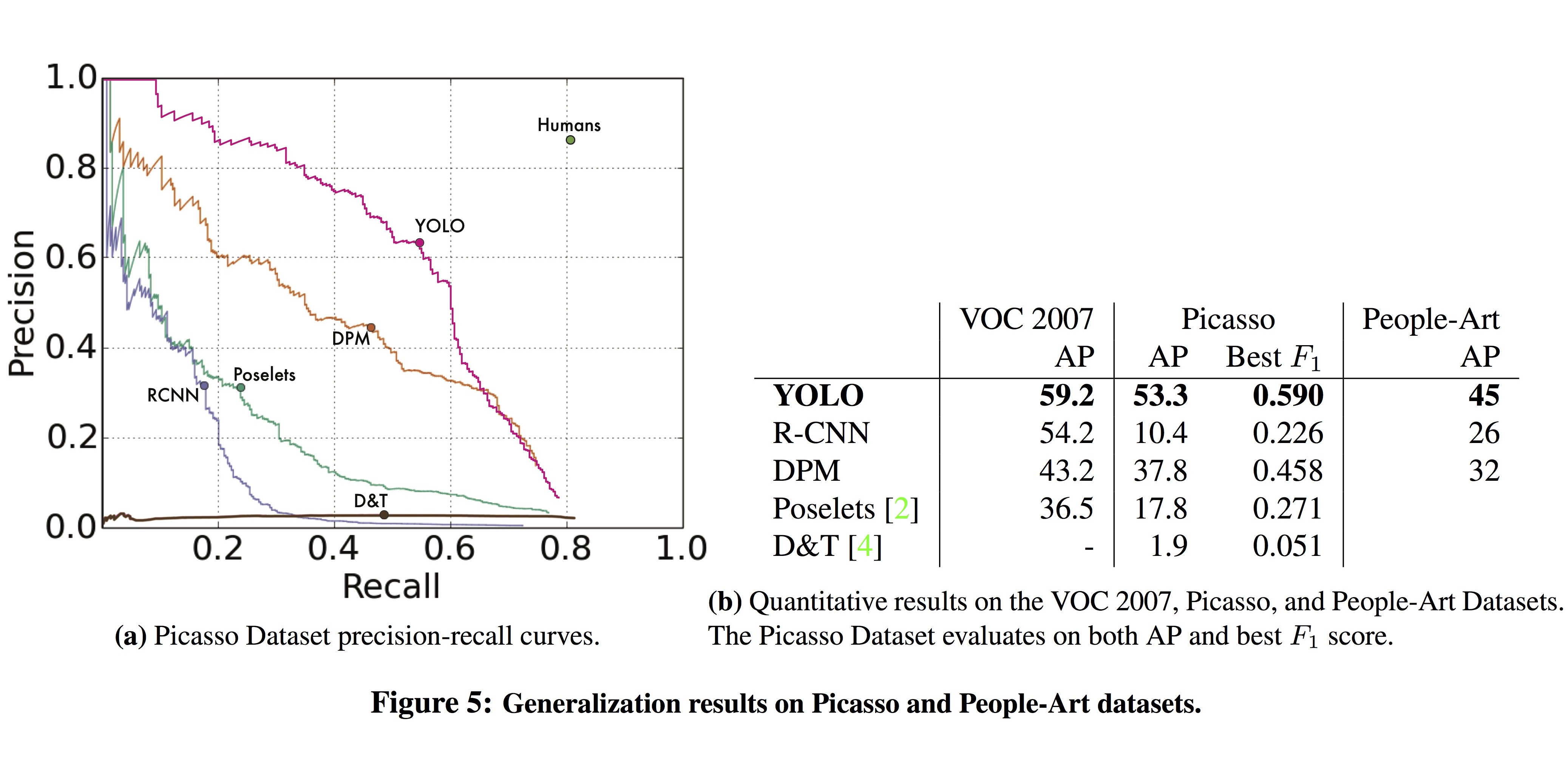
실제 환경은 dataset과 다를 수 있으므로, 다른 distribution을 가지는 환경에 이 모델이 얼마나 잘 일반화하는지 알아보기 위해 이 논문에서는 artwork (Picasso, People-Art) dataset에서 실험을 했습니다.
정확도가 크게 감소하는 다른 object detection system과는 달리, YOLO는 높은 AP 값을 보이면서 다양한 BBox들을 검출할 수 있었습니다.

지금까지 unified object detection 모델인 YOLO에 대해 소개 드렸습니다. YOLO는 이후 YOLOv2로 발전되어 정확도가 대폭 향상되었습니다. 이 논문에 대해서는 추후 다른 posting에서 다시 설명 드리겠습니다.
– Jamie;
References
- Joseph Redmon의 논문 “You Only Look Once: Unified, Real-Time Object Detection”
- Joseph Redmon의 슬라이드 “You Only Look Once: Real-Time Detection”
- Joseph Redmon의 웹페이지 “YOLO: Real-Time Object Detection”
- Joseph Redmon의 YouTube 동영상 “You Only Look Once: Unified, Real-Time Object Detection”
- Joseph Redmon의 GitHub “pjreddie/darknet”
- Martin님의 블로그 post “[Deeplearning] YOLO!, You Only Look Once : Unified, Real-Time object Detection”
- Matthijs Hollemans의 블로그 post “Real-time object detection with YOLO”
- 헬벨 님의 블로그 post “You Only Look Once: Unified, Real-Time Object Detection”
- 박진우 님의 블로그 post “You Only Look Once: Unified, Real-Time Object Detection”
- Alexander Jung의 GitHub post “aleju/papers”
- Deepsystem.io의 슬라이드 “YOLO”
- Deepsystem.io의 YouTube 동영상 “YOLO”
- PyImageSearch의 article “Intersection over Union (IoU) for object detection”
- Pascal VOC 프로젝트 웹페이지 The PASCAL Visual Object Classes Homepage
- Christian Szegedy의 GoogLeNet 논문 “Going Deeper with Convolutions”
- Joseph Redmon의 웹페이지 “Darknet”
- Joseph Redmon의 YOLOv2 논문 “YOLO9000: Better, Faster, Stronger”