이 논문은 Google의 AutoML에 대한 정보를 주는 논문이라고 할 수 있습니다. 즉, 딥러닝을 만드는 딥러닝에 대한 재미있는 내용입니다. 새로운 neural network을 설계하고 튜닝하는 것이 어려운데, 학습을 통해서 자동화할 수 있을까에 대한 첫 시도라는 점에서 의의가 있습니다.
Introduction
이 논문에서는 새로운 구조를 gradient 기반으로 찾는 Neural Architecture Search라는 방법을 제안합니다.
이 연구는 neural network의 structure와 connectivity를 가변 길이의 configuration string으로 지정한다는 관찰에서 시작됩니다. 예를 들어, Caffe에서는 아래와 같은 형태의 string을 사용해서 한 layer의 구조를 정해줍니다.
String의 처리에는 RNN을 적용하는 것이 일반적이므로, 여기서도 RNN(“Controller”)을 사용해 그와 같은 configuration string을 generation하도록 합니다. 그렇게 만들어진 네트워크(“Child Network”)의 성능을 validation set에서 측정하고, 결과로 얻은 accuracy를 reinforcement learning의 reward로 사용해 Child Network의 parameter를 update합니다.
RNN으로 convolutional architecture를 만드는 단순한 방법부터 살펴보겠습니다. 이 RNN은 만들어진 architecture의 expected accuracy를 maximize하기 위해 policy gradient method로 training됩니다. 또한, skip connection (ResNet에서 사용한)으로 모델의 구조를 복잡하게 하고 parameter server를 도입해 분산 training의 속도를 높이는 시도에 대해서도 뒤에서 다시 설명 드리겠습니다.
Generate Model Descriptions with a Controller RNN
RNN Controller는 neural network의 hyperparameter들을 token sequence를 만들어내는 방식으로 생성합니다. 아래 그림에서, filter height, filter width, stride height, stride width, number of filters 등의 한 layer의 parameter를 생성하는 네트워크가 전체 layer 수 만큼 반복되는 구조인 것을 볼 수 있습니다.
Training with REINFORCE
이 논문에서 적용한 reinforcement learning 알고리즘은 Ronald J. Williams의 REINFORCE 입니다.
REINFORCE를 사용한 이유는 가장 간단하고 다른 방법들에 비해 튜닝하기 쉽기 때문이라고 합니다. 이 연구에서 하려는 실험의 스케일이 대단히 크다는 점을 감안한 것 같습니다.
사용한 loss function은 non-differentiable한 reward signal $R$을 사용해 아래의 첫 식과 같이 표현됩니다. Gradient인 아래의 두 번째 식은 계산의 편의와 너무 높은 variance를 줄이기 위해 전개를 거쳐 실제로는 마지막의 식으로 계산됩니다.
이 논문의 실험의 수백 개의 CPU 또는 GPU를 사용하기 때문에 분산 학습 구조를 사용합니다. 아래 그림과 같이, $S$개의 shard로 나눠진 parameter server에서 받아온 parameter에 따라 $K$개의 controller는 각각 $m$개 씩의 child architecture를 병렬로 실행합니다. 각 child의 accuracy는 기록되고 parameter server로 다시 전송됩니다.
Increase Architecture Complexity with Skip Connections and Other Layer Types
GoogleNet, Residual Net에서 사용한 skip connection 구조를 적용할 수 있도록, 아래 그림에 보는 것처럼 각 layer에 기준점이 되는 Anchor Point를 도입했습니다.
Generate Recurrent Cell Architectures
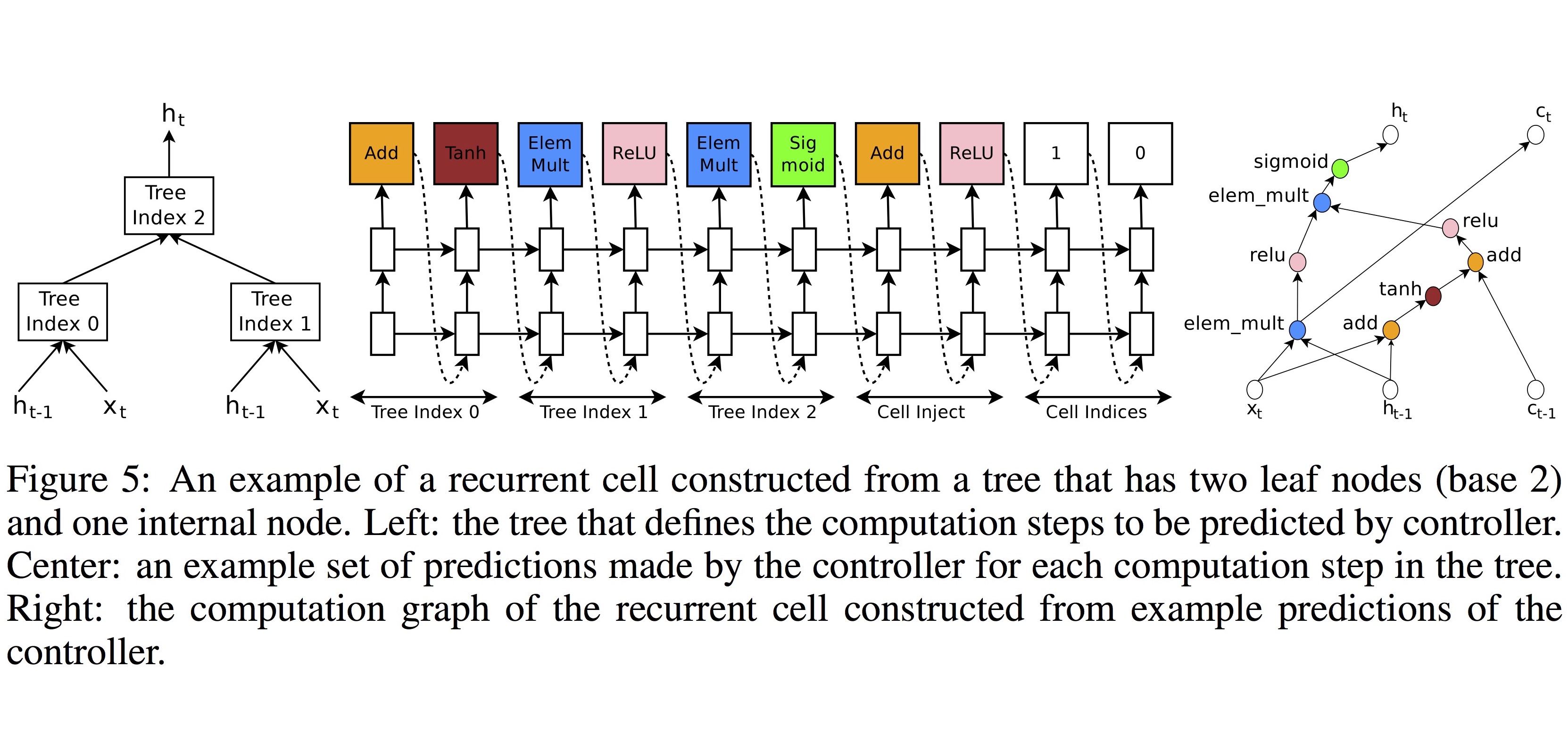
이번에는, LSTM과 유사한 RNN의 기본 연산 단위인 cell을 생성해봤습니다. RNN의 기본 cell은 input, output 뿐만 아니라 memory state로 구성되는데, 이 모델은 tree 형태로 일반화할 수 있습니다. 아래 그림은 왼쪽의 가장 간단한 형태의 tree 모델을 Neural Architecture Search를 거쳐 오른쪽의 기본적 unit들의 조합으로 만들어낸 예제입니다. 즉, LSTM이나 GRU와 같은 RNN의 cell을 이렇게 자동으로 만들어 내는 것이 가능합니다.
Experiments and Results
이 논문에서는 두 가지 실험 결과를 보여주고 있습니다. 하나는 CIFAR-10을 사용한 image classification이고, 다른 하나는 Penn Treebank를 사용한 language modeling 입니다.
Learning Convolutional Architectures for CIFAR-10
이 실험은 filter height, filter width, number of filters를 controller RNN이 찾는 문제입니다. 기본적인 search space는 convolutional architecture, ReLU, batch normalization, skip connection으로 구성되어 있습니다.
이 실험에서 controller RNN은 35개의 hidden unit으로 구성된 2계층의 LSTM 구조이고 ADAM optimizer를 사용했습니다. 분산 학습을 위해 무려 800개의 GPU ($S$:20, $K$:100, $m$:8)를 사용했다고 합니다.
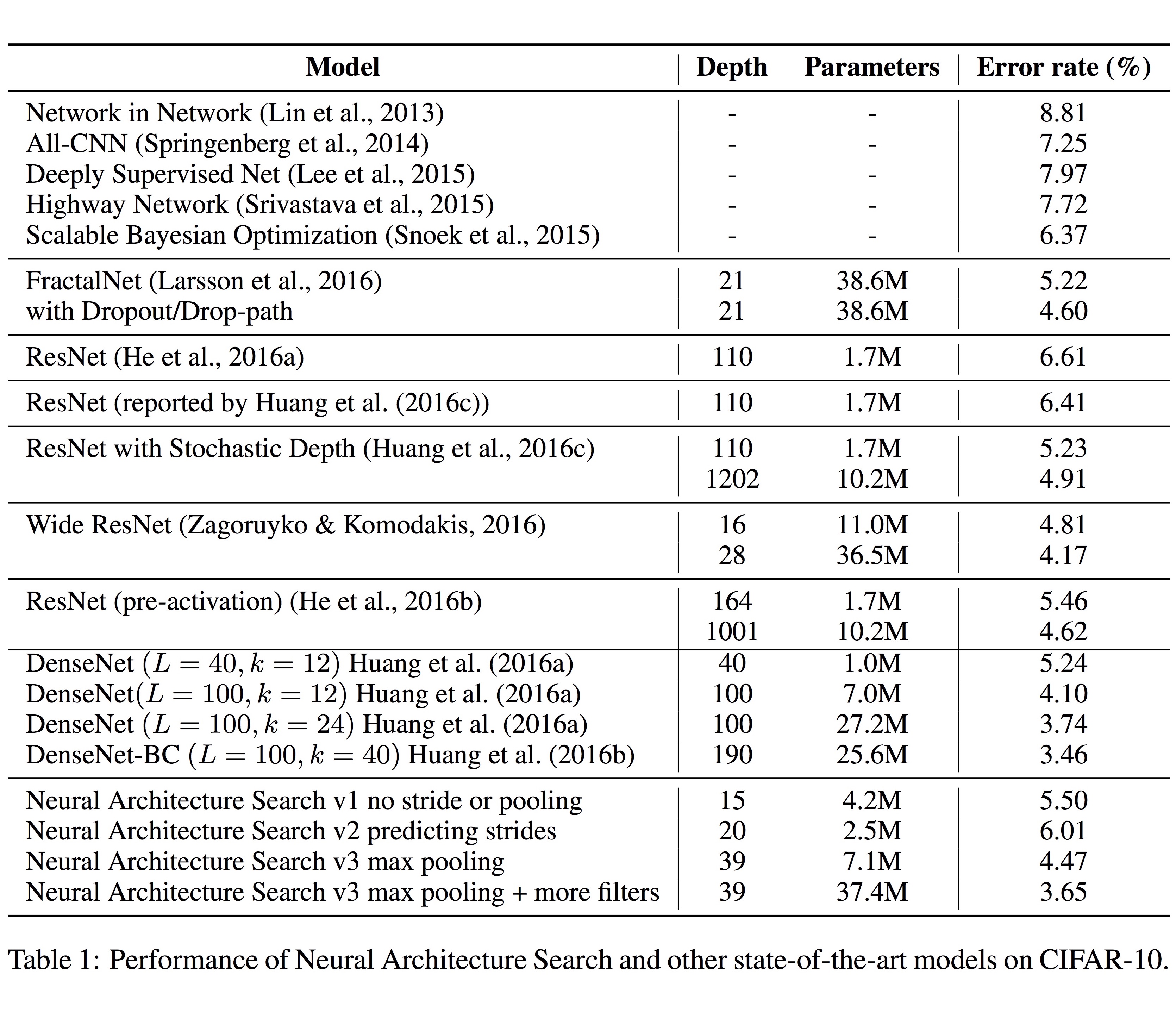
아래 표의 실험 결과에서, 맨 아래 부분 Neural Architecture Search로 만든 구조들이 DenseNet을 비롯한 인간이 설계한 state-of-the-art에 근접하는 성능을 보이는 것을 볼 수 있습니다.
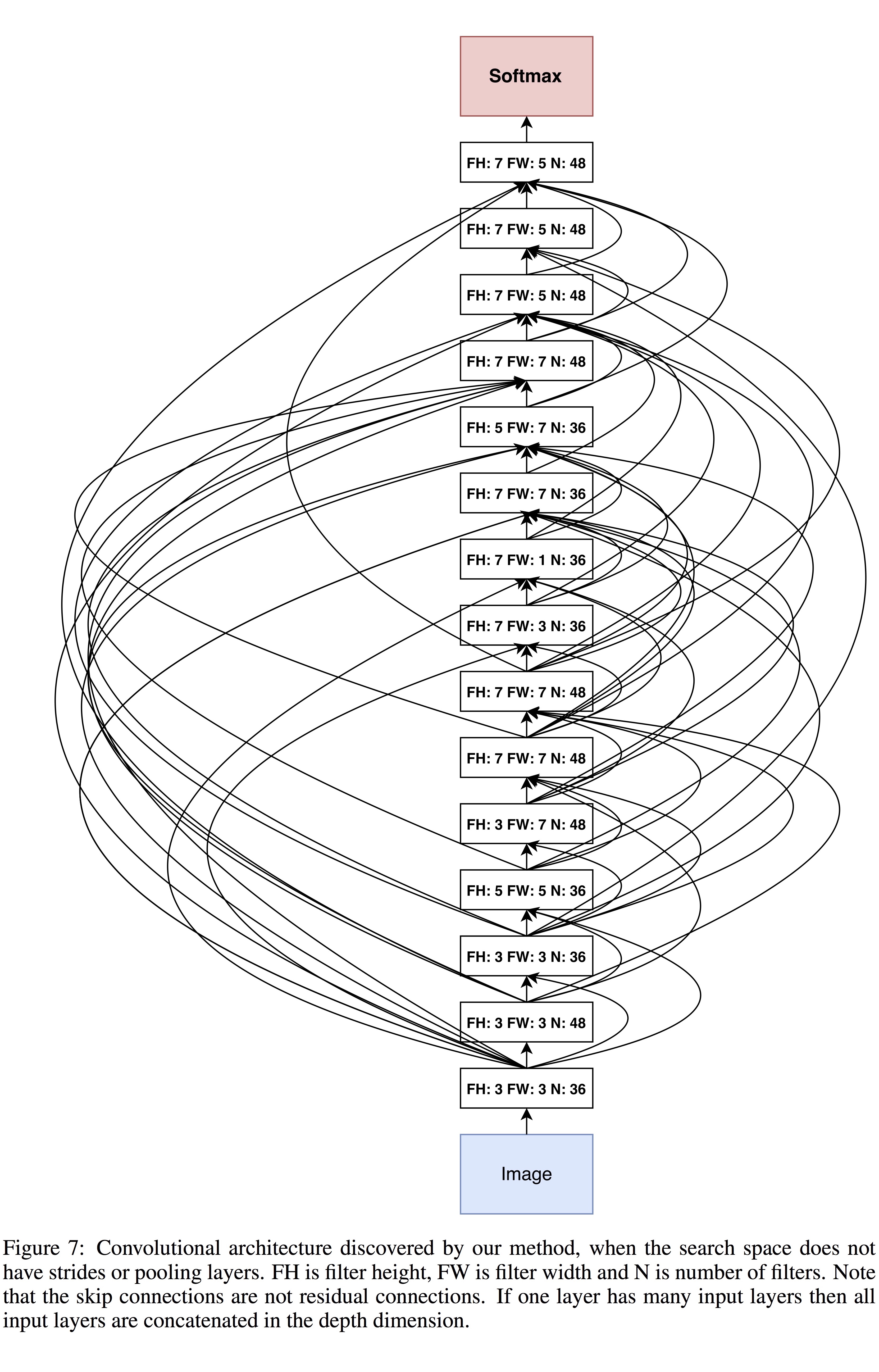
위 표의 맨 아래 부분에서 “Neural Architecture Search v1 no stride or pooling”로 표시된 결과가 아래 그림과 같습니다. 이 구조는 15개의 layer만으로 구성되어 있지만 비교적 뛰어난 성능을 보이고 있습니다.
Learning Recurrent Cells for Penn Treebank
다음 실험은 language modeling task에 적용할 RNN cell을 생성하는 것입니다. 앞에서 보인 Figure 5에서 보인 것과 같이, [add, elem_mult] 등의 combination method와 [identity, tanh, sigmoid, relu] 등의 activation method를 조합해서 tree의 각 node를 표현하도록 합니다.
실험에는 400개의 CPU를 사용했고, 총 15,000개의 child network을 만들어 평가했다고 합니다. 실험 결과로 만들어진 RNN cell은 LSTM 대비 0.5 BLEU의 향상을 보였습니다.
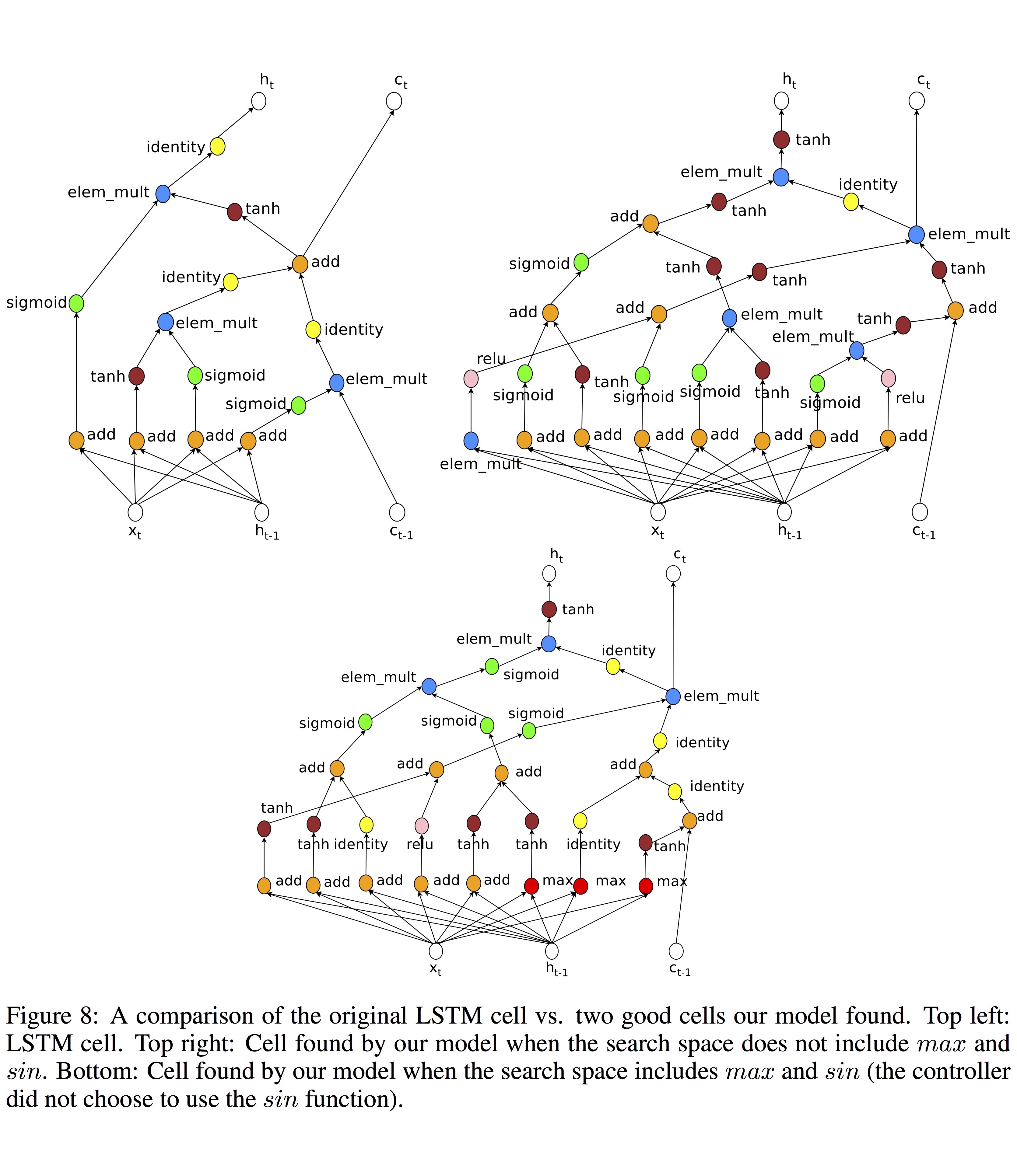
아래 그림은 기본 LSTM과 이 실험의 결과로 만든 2가지 버전의 RNN cell을 보입니다.
지금까지 RNN을 사용해 neural network 구조를 만드는 Neural Architecture Search에 대해 설명 드렸습니다. 자동으로 neural network의 구조를 탐색하는 이런 연구가 향후 어떻게 발전해 나갈지 기대가 큽니다.
이 논문에서 사용한 코드는 GitHub TensorFlow Models 페이지에 공개될 예정이며, 앞에서 만든 RNN cell은 NASCell이라는 이름으로 TensorFlow API에 추가되었습니다.
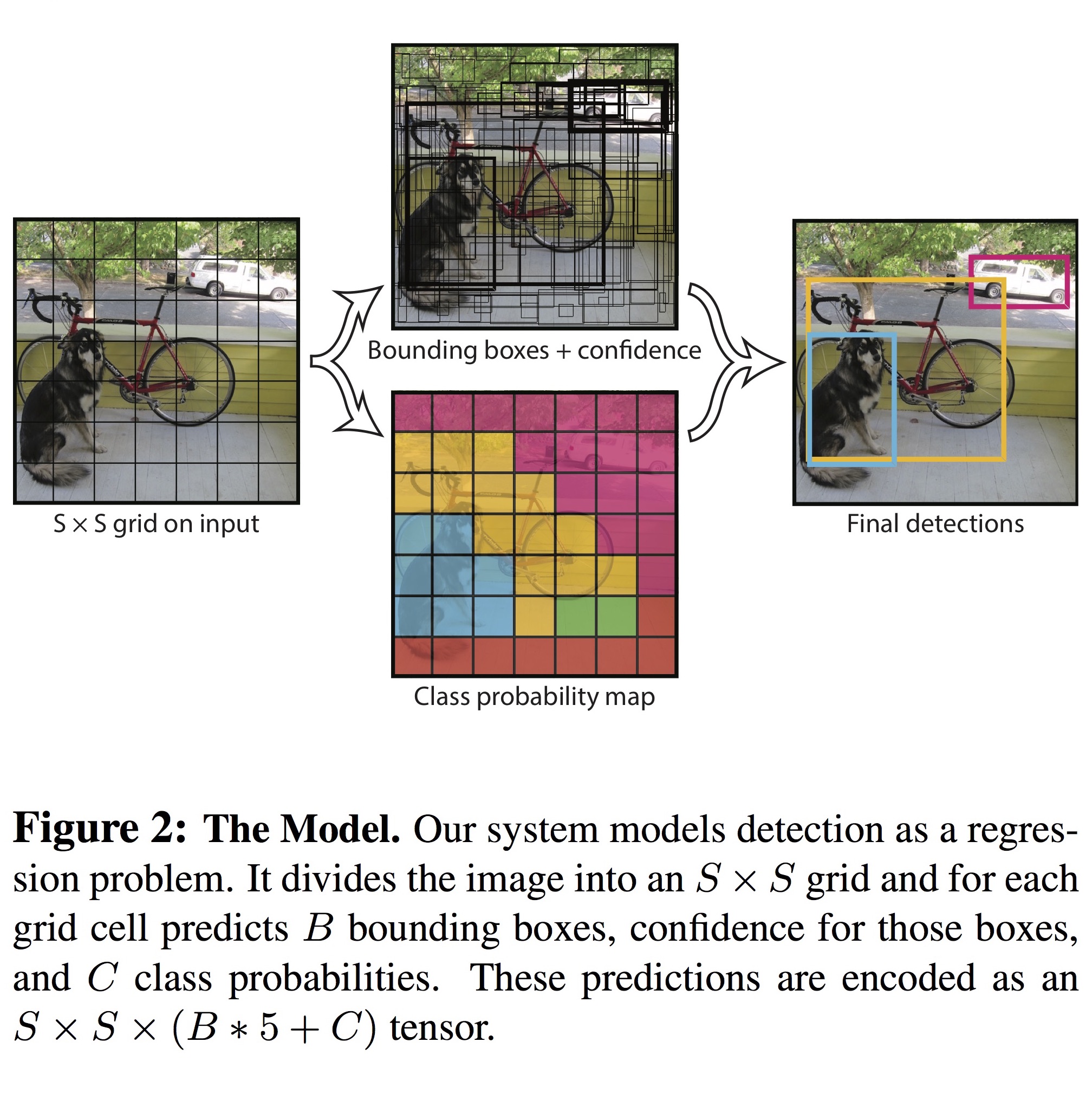
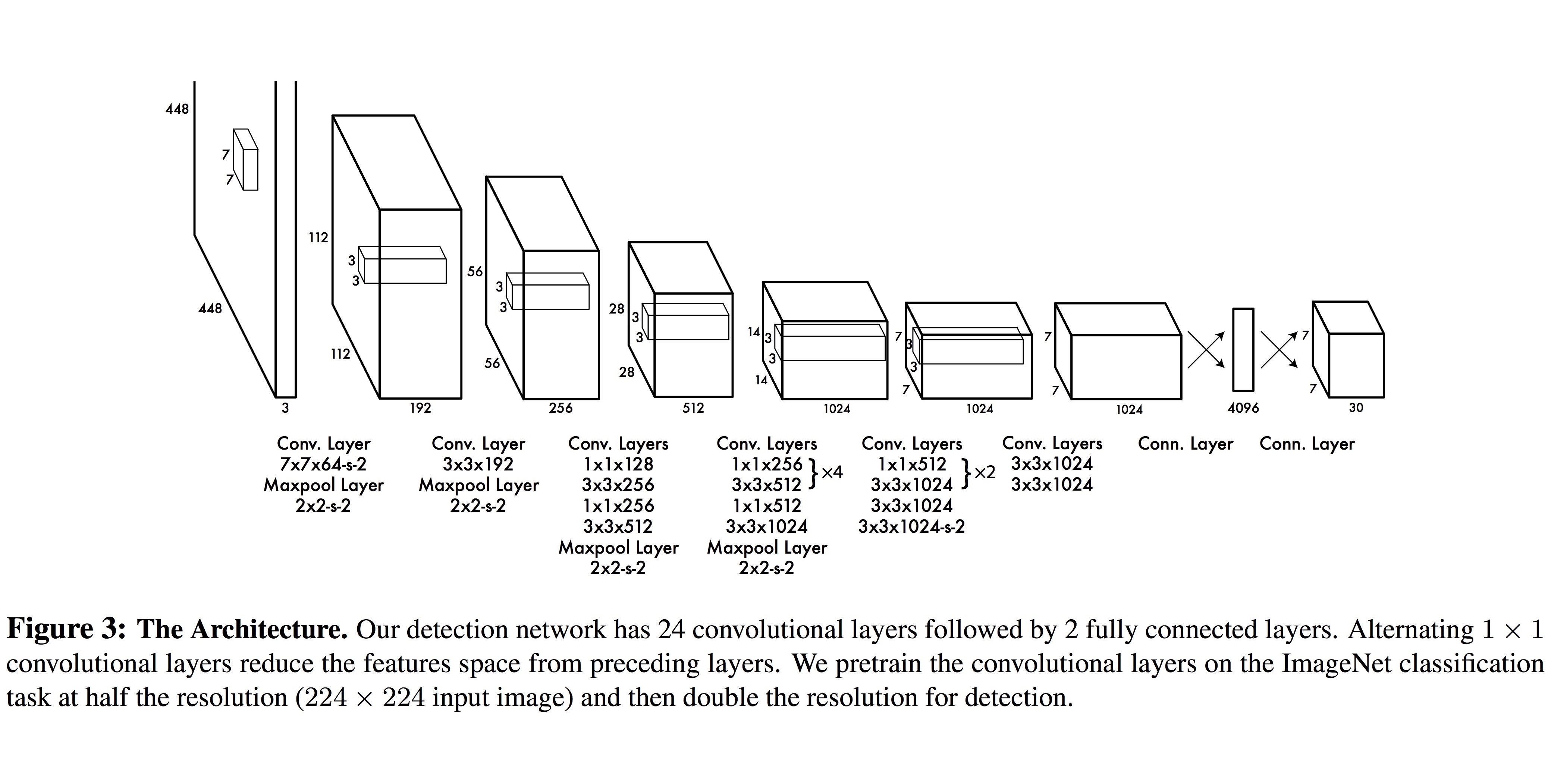
이 논문에서 사용한 neural network (YOLO) 는 Google이 ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014)에서 사용했던 GoogLeNet 을 변형한 구조입니다. 이 네트워크는 24개의 convolutional layer와 2개의 fully connected layer로 구성되어 있습니다. $1 \times 1$ reduction layer를 여러 번 적용한 것이 특징입니다.
이 논문에서 사용한 또 하나의 neural network인 Fast YOLO는 9개의 convolutional layer와 더 적은 수의 filter만을 사용해 속도를 더 높이고 있습니다. 기타 training과 testing을 위한 파라미터는 YOLO와 동일합니다.
Linear activation function으로는 leaky ReLU ($\alpha = 0.1$)를 사용했습니다. Loss function은 기본적으로 sum-of-squared-error 개념이지만, object가 존재하는 grid cell과 object가 존재하지 않는 grid cell 각각에 대해 coordinates ($x$, $y$, $w$, $h$), confidence score, conditional class probability의 loss를 계산하기 때문에 아래와 같이 복잡한 식이 됩니다.
Training
이 논문의 실험에서 training은 먼저 ImageNet으로 pretraining을 하고 다음에 Pascal VOC에서 finetuning하는 2단계 방식으로 진행됐습니다. 학습에는 앞의 20개의 convolutional layer만을 사용했고 (feature extractor), 마지막 4개의 convolutional layer와 2개의 fully connected layer를 추가해서 (object classifier) 실제 object detection에 사용할 system을 구성합니다.
한 가지 특이한 점은, 저자들이 자신들이 직접 만든 Darknet이라는 framework를 사용했다는 점입니다.
Pascal VOC를 사용한 training에는 135번의 epoch, batch size 64, momentum 0.9, decay 0.0005, dropout rate 0.5를 각각 적용했습니다. Learning rate은 $10^{-3}$, $10^{-2}$, $10^{-3}$, $10^{-4}$으로 epoch에 따라 바꿔가며 사용했습니다.
Inference
이 논문에서 불필요한 중복 BBox들을 제거하기 위해 Non-maximal suppression이라는 개념이 중요하게 사용됩니다. Non-maximal suppression을 포함해 전체 YOLO 시스템의 동작은 Deepsystem.io의 슬라이드와 아래 동영상에 가장 잘 설명되어 있습니다.
Limitations of YOLO
YOLO가 사용하는 grid cell은 2개까지의 BBox와 1개의 class만을 예측할 수 있기 때문에 그에 따른 약점을 가지고 있습니다. 예를 들어 새 떼와 같이 작은 object들의 그룹이나 특이한 종횡비의 BBox는 잘 검출하지 못한다고 합니다.
Comparison to Other Detection Systems
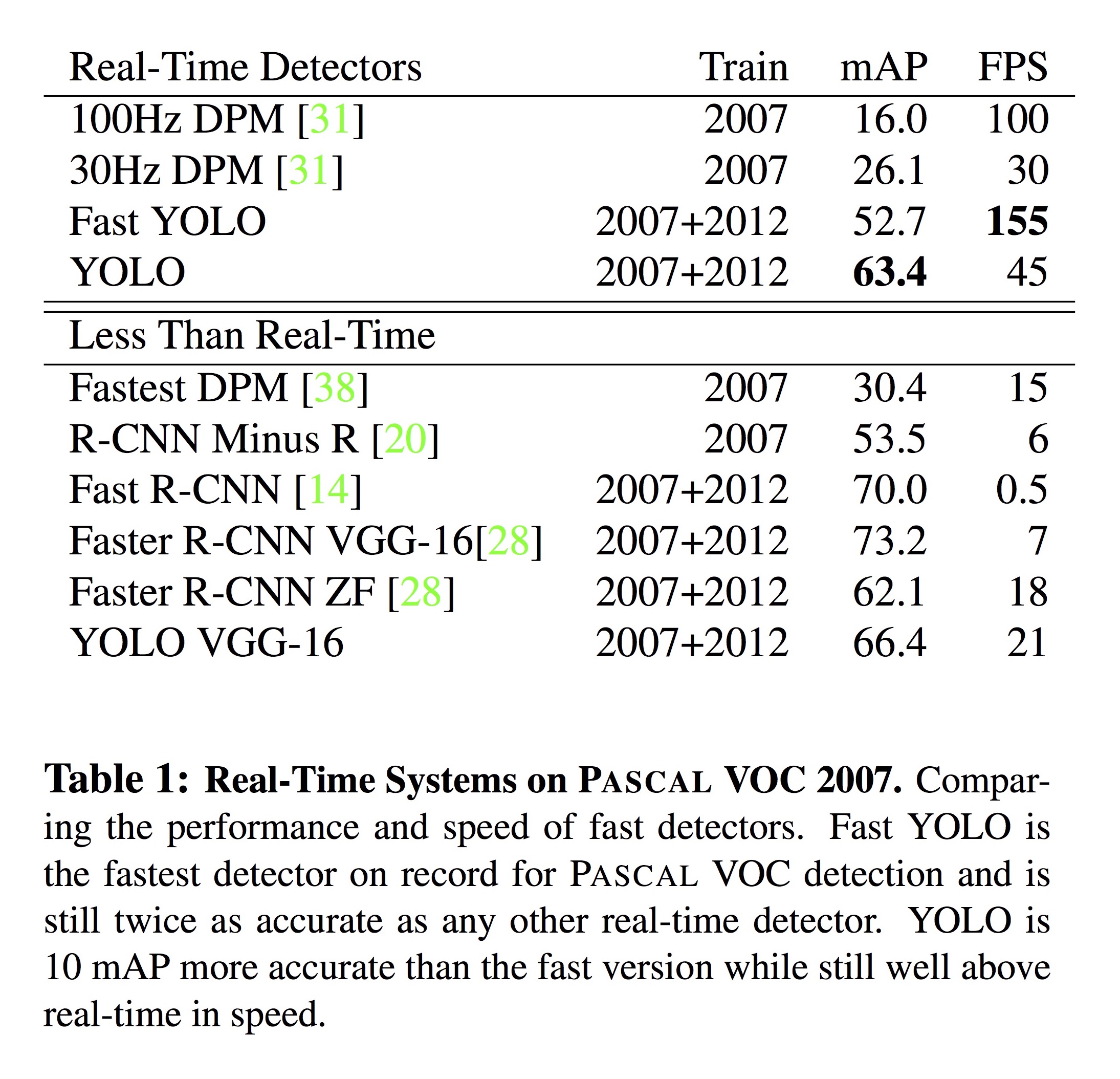
현재까지 발표된 다양한 object detection system과 비교한 실험 결과가 아래 표에 정리되어 있습니다. Fast YOLO는 155 fps로 가장 빠른 처리 성능을 보이고 있고, 표준 YOLO는 Fast YOLO보다 약간 느리면서 한편, 정확성을 나타내는 mAP 값이 Faster R-CNN과 유사한 수준을 보이고 있습니다.
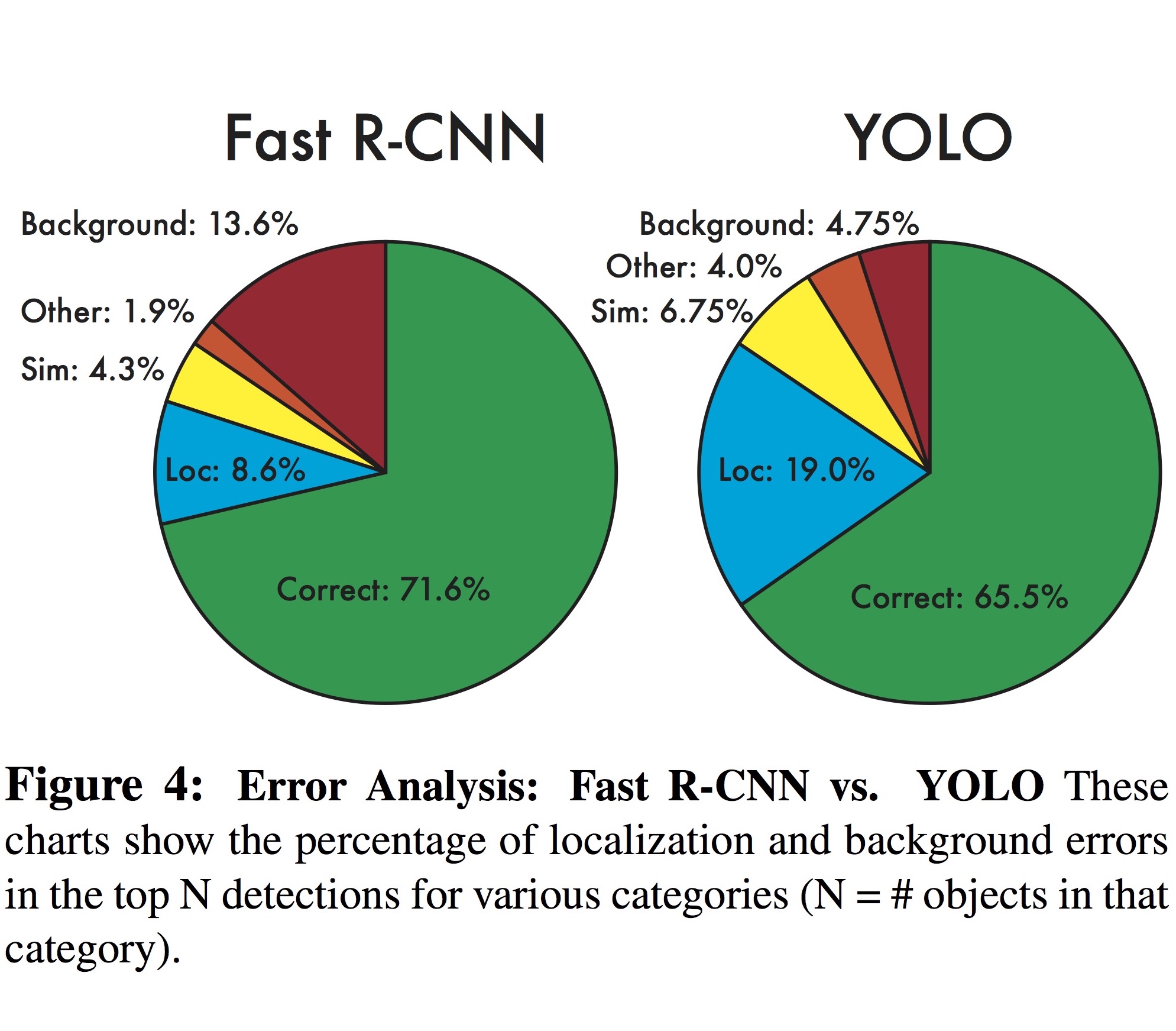
아래 그림은 Pascal VOC 2007에서 Fast R-CNN과 YOLO의 error를 분석한 것입니다. Fast R-CNN의 error는 background 영역에서 대부분 발생하는 한편, YOLO의 error는 localization에서 대부분 일어나는 것을 알 수 있습니다.
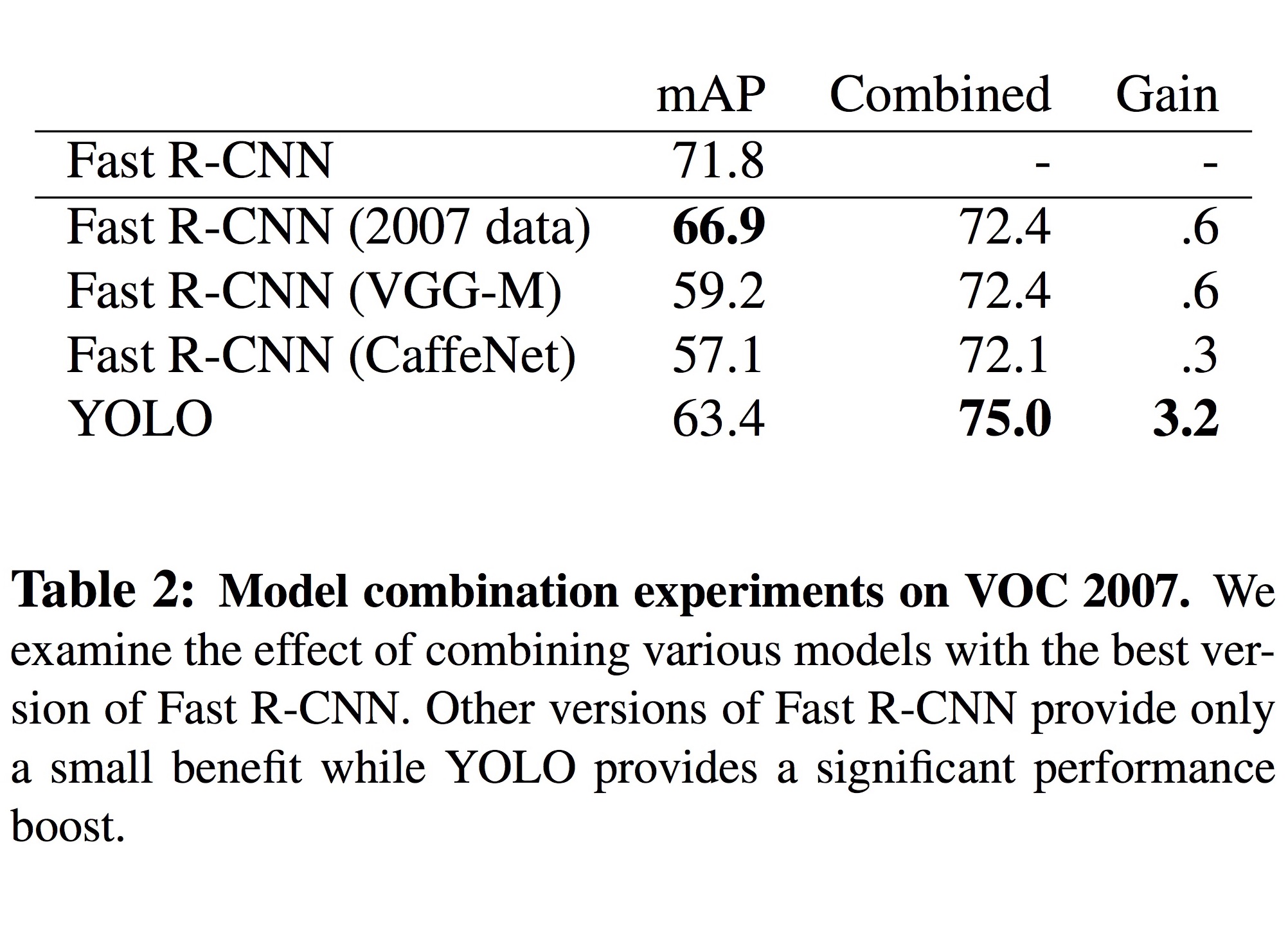
이와 같은 서로의 단점을 보완하기 위해, 두 모델을 함께 사용한 실험에서는 mAP 값이 71.8%에서 75.0%로 대폭 향상되었습니다.
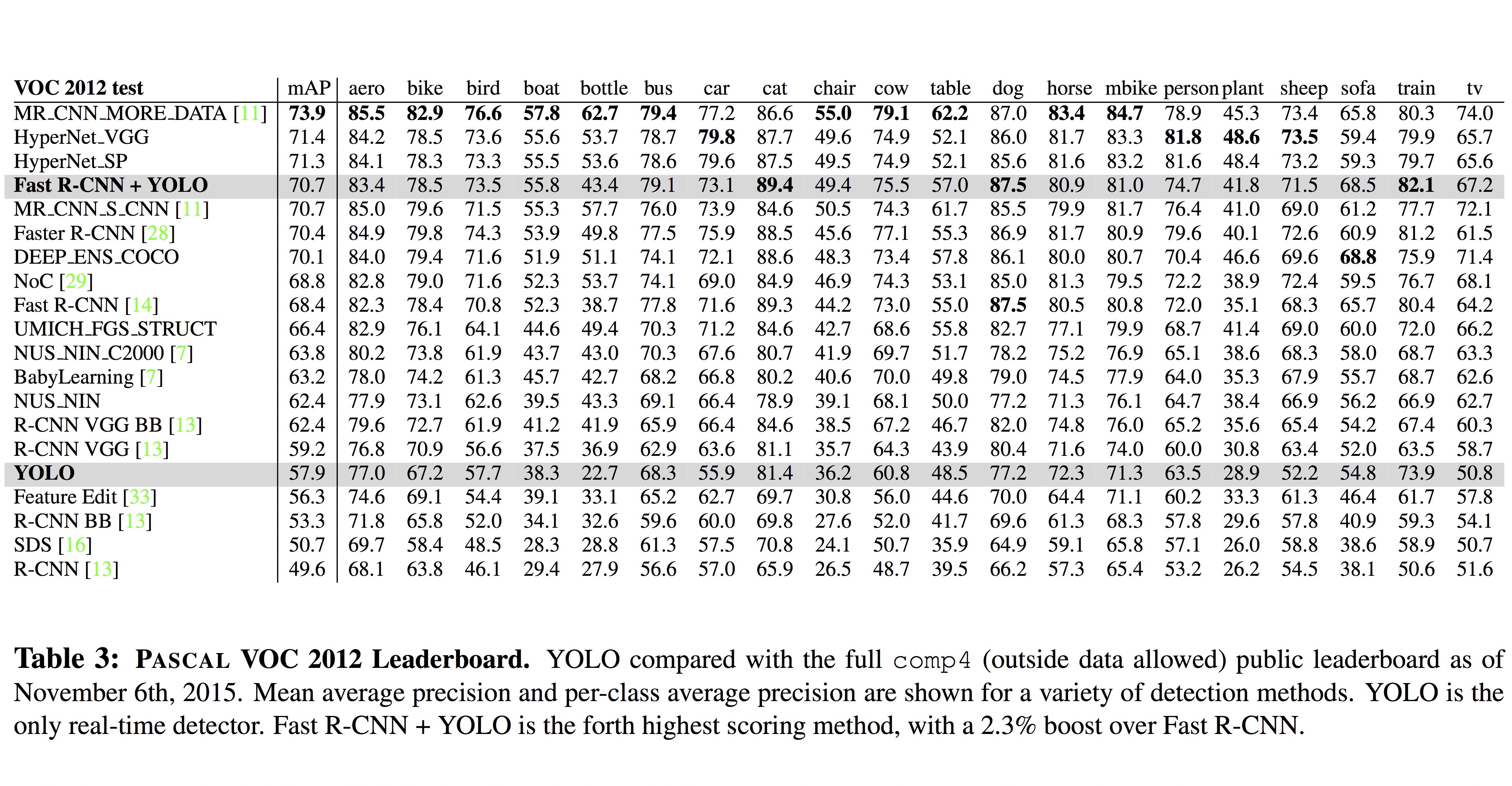
아래의 VOC 2012 테스트 표를 보면, 정확도 측면에서 Fast R-CNN과 YOLO의 조합은 최상위권에 위치하고 있는 것을 볼 수 있습니다.
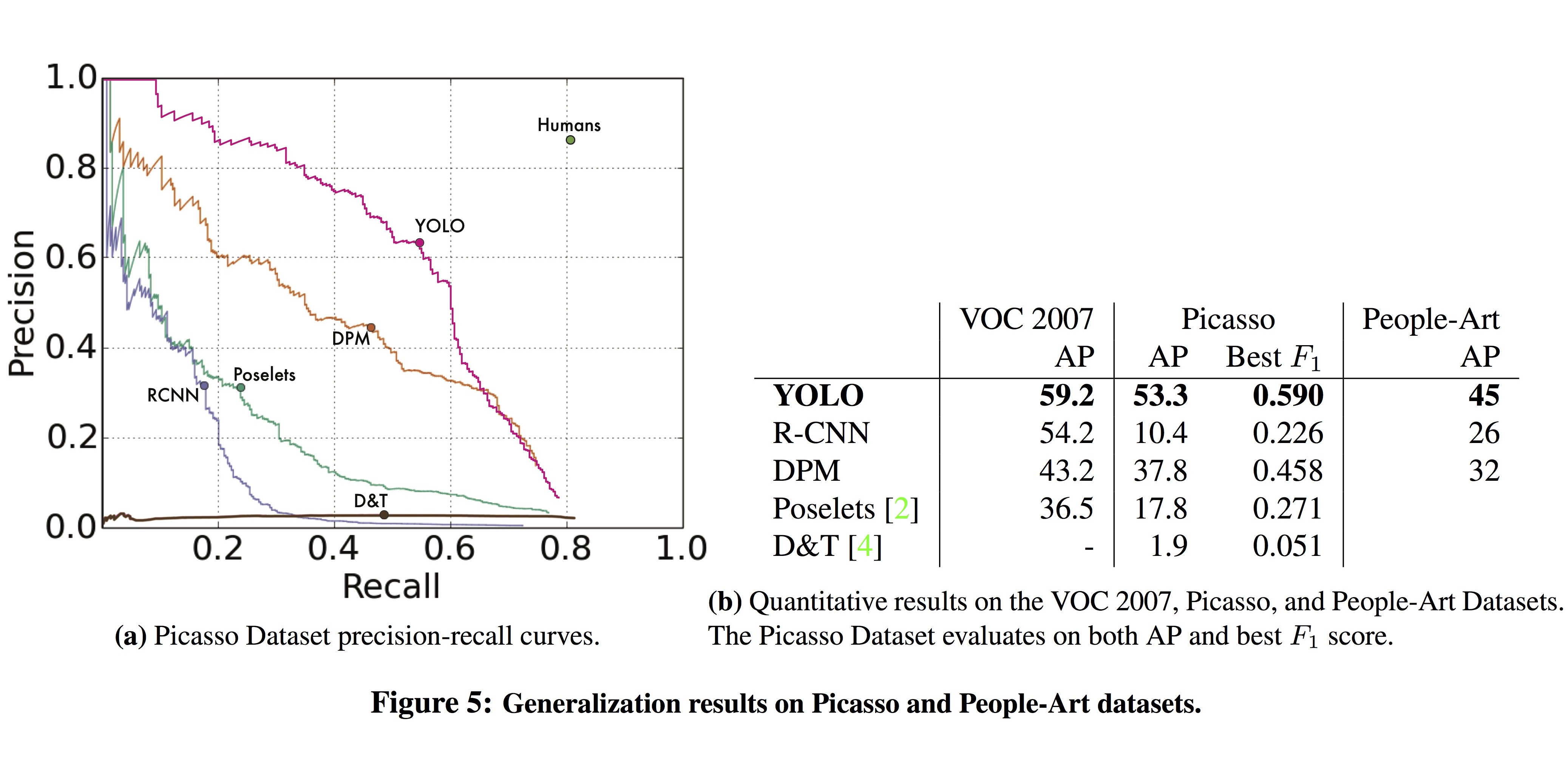
실제 환경은 dataset과 다를 수 있으므로, 다른 distribution을 가지는 환경에 이 모델이 얼마나 잘 일반화하는지 알아보기 위해 이 논문에서는 artwork (Picasso, People-Art) dataset에서 실험을 했습니다.
정확도가 크게 감소하는 다른 object detection system과는 달리, YOLO는 높은 AP 값을 보이면서 다양한 BBox들을 검출할 수 있었습니다.
지금까지 unified object detection 모델인 YOLO에 대해 소개 드렸습니다. YOLO는 이후 YOLOv2로 발전되어 정확도가 대폭 향상되었습니다. 이 논문에 대해서는 추후 다른 posting에서 다시 설명 드리겠습니다.
이 논문은 문장 수준의 classification 문제에 word vector와 CNN을 도입한 연구를 다루고 있습니다.
Introduction
이 논문을 이해하기 위해서는 Word Embedding과 Word2vec에 대한 사전 지식이 필요합니다.
Word Embedding
Word embedding은 NLP (Natural Language Processing, 자연어 처리) 분야에서 컴퓨터가 인식할 수 있도록 수치적인 방법으로 단어를 표현하는 방법입니다. 초기의 NLP는 one-hot encoding을 많이 사용했는데, 간단하고 적용하기 쉬웠지만 단어들 간의 관계를 표현할 수 없는 한계가 있었습니다.
Word2vec
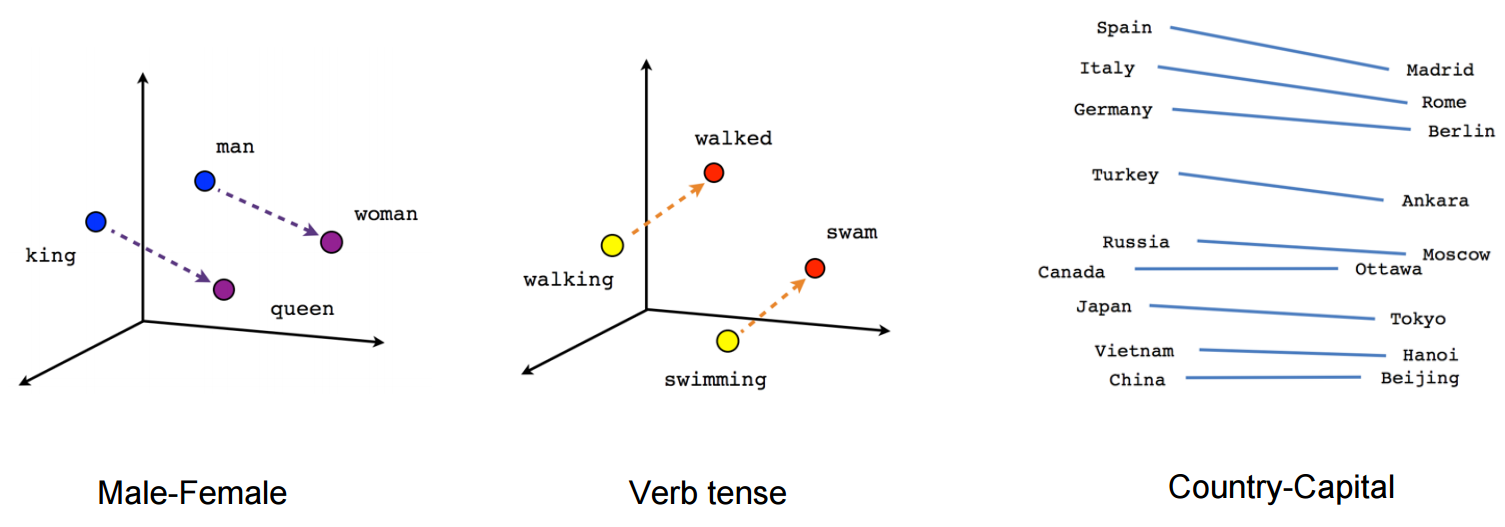
단어 자체의 의미를 multi-dimensional vector로 표시하기 위한 연구는 1980년대부터 있었다고 합니다. 하지만 2000년대 들어 NNLM (Neural Network based Language Model)과 RNNLM (Recurrent NNLM)을 거쳐 2013년 Google이 발표한 Word2vec이 현재 가장 state-of-the-art 기술로 각광받고 있습니다. Word2vec의 학습 결과를 시각화해보면 아래 그림처럼 벡터들의 방향과 단어들의 의미가 연관성이 있는 것을 확인할 수 있습니다.
이 그림에서 $n$은 문장에 나오는 단어의 개수, $k$는 word vector의 dimension, $h$는 filter window size를 의미합니다. 길이 $n$의 문장은 word vector 를 연결해 아래 (1)식과 같이 표현됩니다.
이 때, $\oplus$는 concatenation 연산자를 의미합니다. Convolution 연산은 윈도우 크기 $h$ 단위로 이뤄지며, filter의 weight $\mathbf{w}$에 대해 feature $c_i$는 아래 식과 같이 계산됩니다.
위 식에서 $b$는 bias, $f$는 non-linear (ReLU) 함수입니다. 모든 word window 에 필터를 적용해 아래 (3)식과 같이 feature map을 계산합니다.
여기에 max-pooling 연산을 거쳐 얻은 최대 값을 fully-connected layer에 집어 넣습니다. Fully-connected layer에는 dropout을 적용하고 마지막 단에서 softmax 출력을 얻습니다.
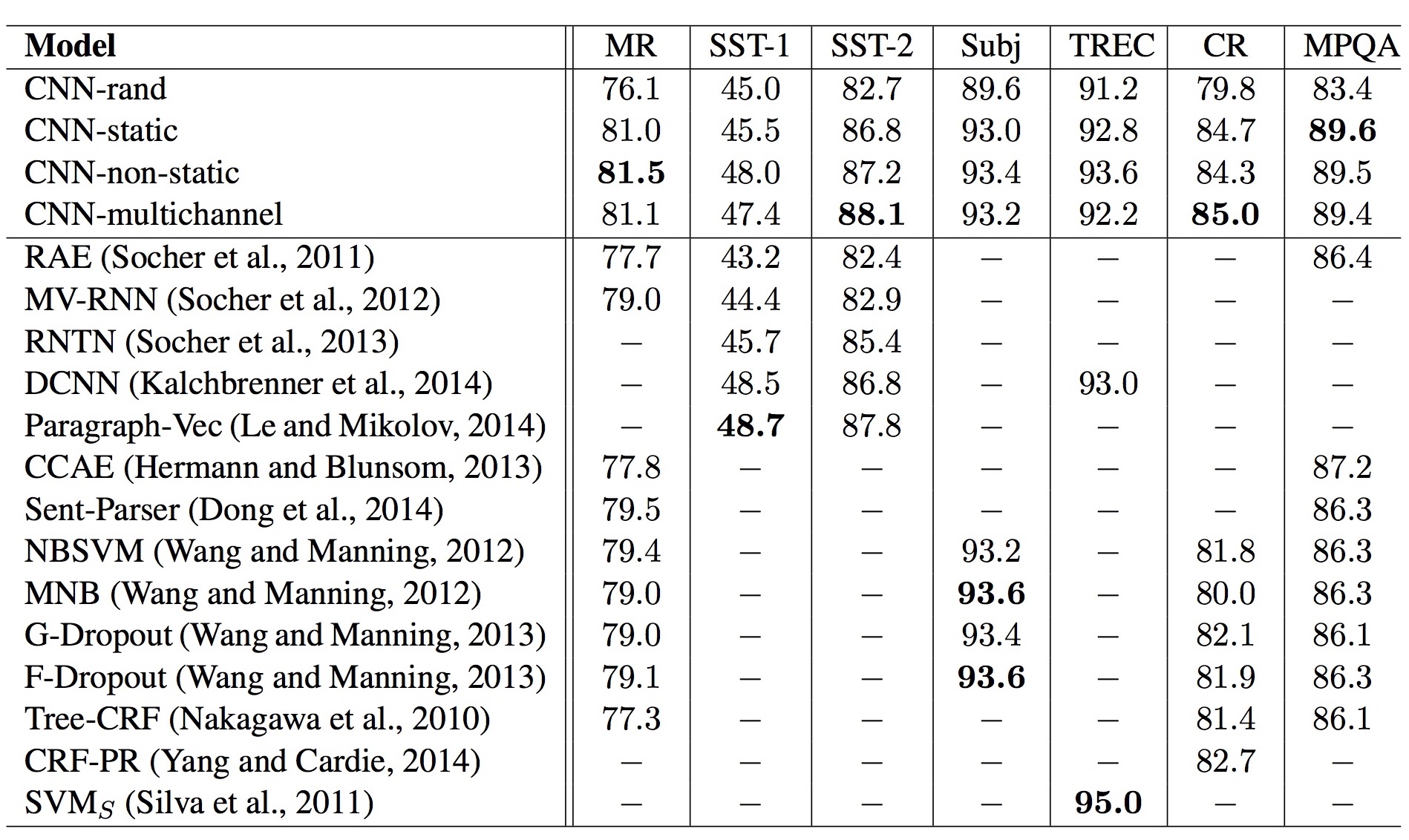
이 논문의 실험에서는 static과 non-static 두 가지 채널을 구분하고 있습니다. Word vector가 training 중에 변하지 않는 것이 static 채널이고, word vector를 backpropagation을 통해 fine-tune하는 것이 non-static 채널입니다.
Dataset과 실험 환경
실험에서 사용한 hyper-parameter들과 training 조건은 아래와 같습니다.
convolution layer: 1 layer with ReLU
filter window size ($h$): 3, 4, 5 with 100 feature maps each (total 300)
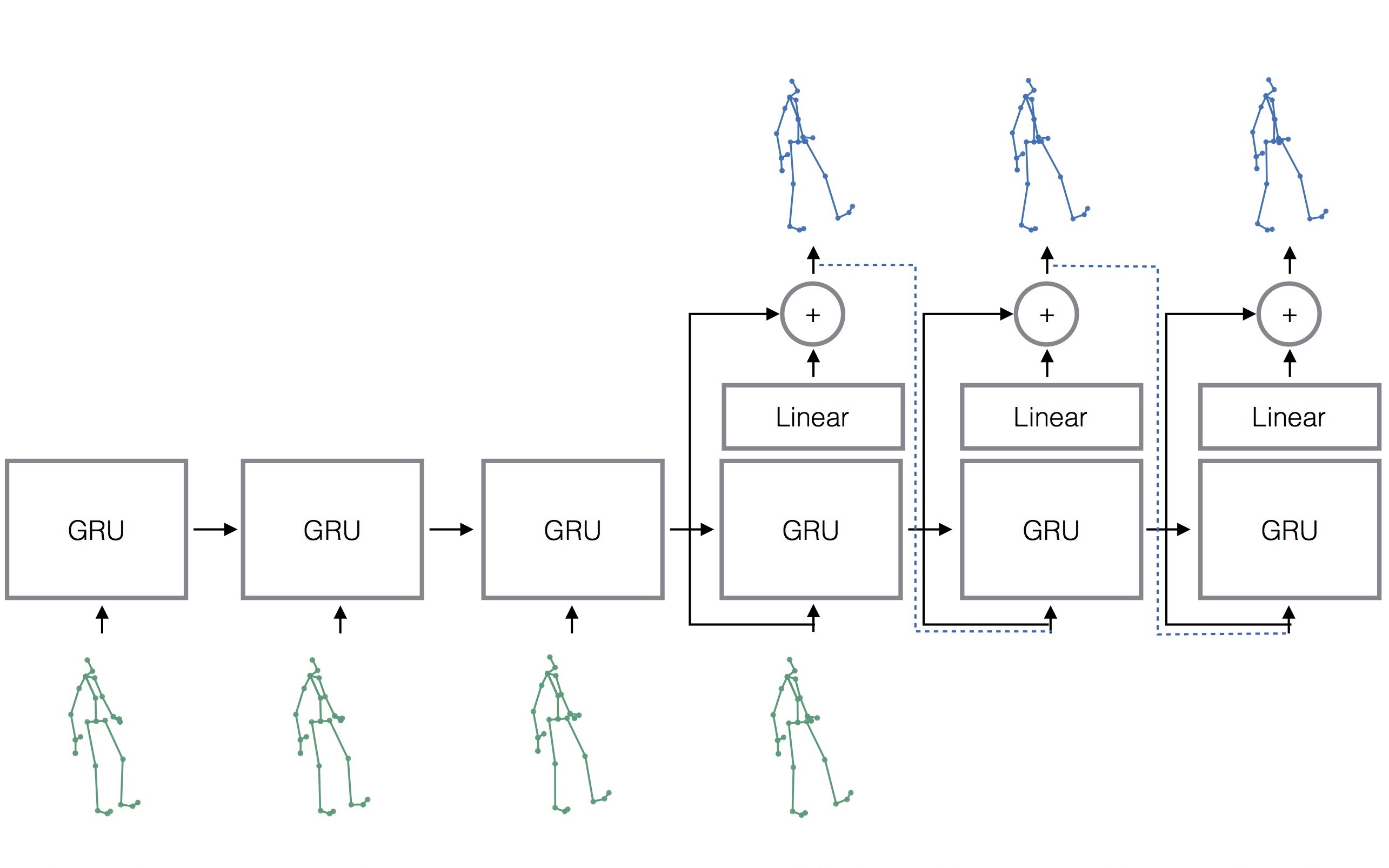
기존에는 training의 각 time-step에서 ground-truth를 입력으로 집어 넣었지만, 대신 prediction한 결과를 입력으로 넣는 구조를 사용 (sampling-based loss).
Prediction에 의한 noise가 반영되므로 별도의 noise scheduling이 필요 없어짐.
아래 그림에서 green 색 모형은 ground truth, blue 색 모형은 prediction을 의미하며, decoder 출력 값이 다음 step의 입력으로 들어가는 것을 확인할 수 있음.
Residual architecture
RNN cell의 input과 output 사이에 residual connection을 연결.
위의 그림의 decoder 부분에서 residual connection을 볼 수 있음.
Multi-action models
Action specific한 모델을 여러 개 만들지 않고, 여러 action을 prediction하는 하나의 모델을 만들어 전체 dataset으로 training함.
Experimental Setup
이 논문에서는 실험에서 다음의 세 가지를 확인하고자 합니다.
Seq2seq architecture and sampling-based loss: ground-truth 대신 prediction을 decoder의 입력으로 넣는 효과 확인
Residual architecture: residual connection의 효과 확인
Multi-action models: 여러 action을 데이터 전체로 training하는 효과 확인
실험에서 dataset으로는 Human 3.6M을 사용했고, 구현에는 1024개의 GRU (Gated Recurrent Unit)를 사용했습니다. 또한, 마지막 frame에서 움직이지 않는 경우(zero-velocity)를 baseline으로 함께 실험해 비교대상으로 삼았습니다.
Results
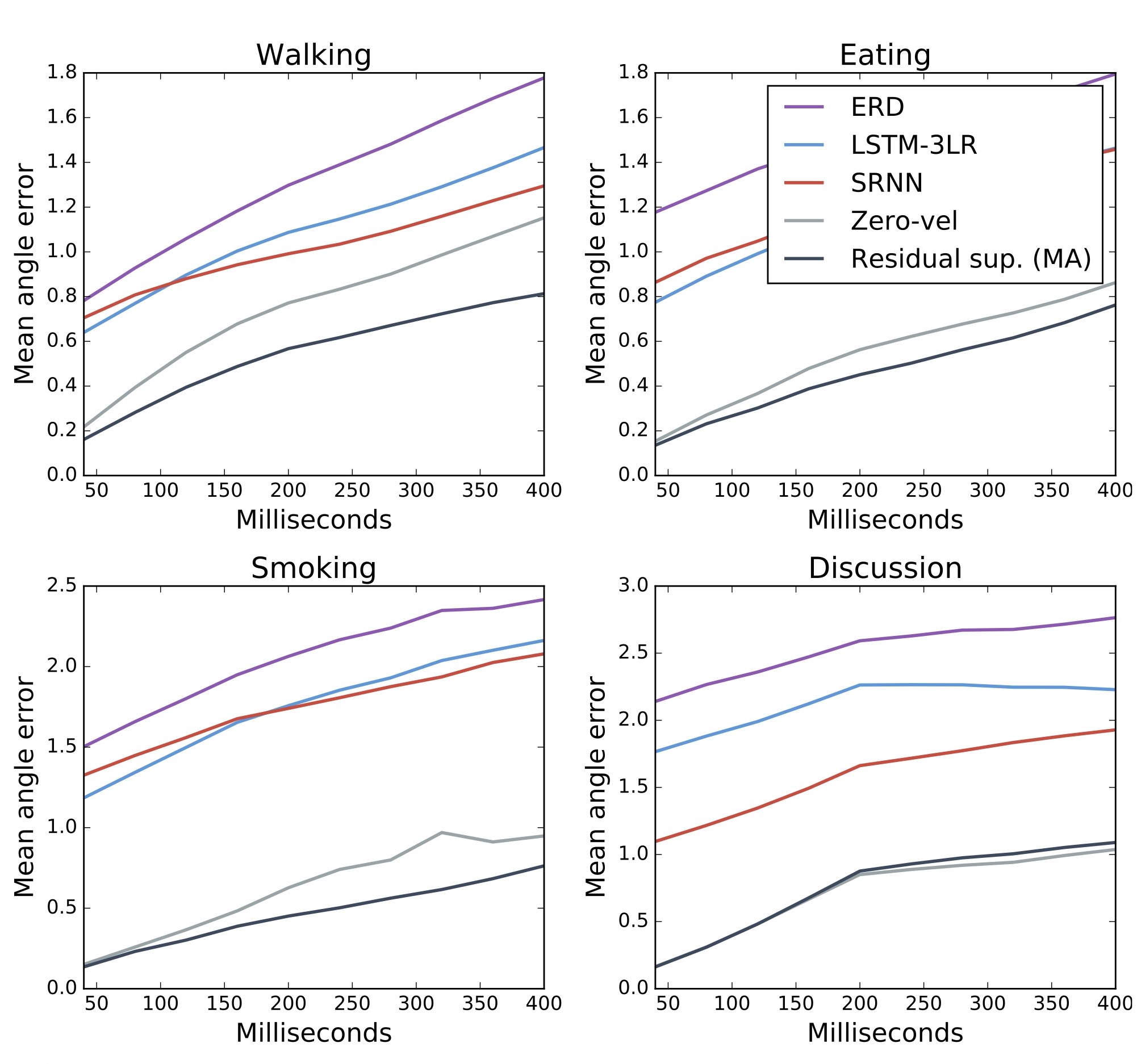
아래 그림은 ERD, LSTM-3LR, SRNN과 함께 zero-velocity와 이 논문에서 제안하는 Residual sup. (MA)의 결과를 보입니다.
실험 결과에서 몇 가지 알 수 있는 사실을 정리했습니다.
제안하는 검은 색 Residual sup. (MA) 라인이 가장 좋은 성능을 보임.
의외로 회색 zero-velocity baseline의 성능이 매우 높음.
Sampling-based loss의 효과로, noise scheduling이 필요 없으며 뛰어난 short-term motion prediction error와 plausible한 long-term motion generation을 달성.
Residual connection으로 성능 향상.
single action data를 사용하는 것보다 모든 action data를 사용하는 것이 효과적임 (data quality < data quantity).
RNN으로 aperiodic motion의 모델링은 어려움.
아래의 동영상은 저자가 공개한 비교 실험 결과입니다.
이 논문은 400ms ~ 1s 수준의 매우 짧은 시간에 대한 prediction을 하는 점이 한계라고 볼 수 있습니다. 즉, 시간이 짧기 때문에 RNN으로 어느 정도 prediction이 가능한 것으로 보입니다. 그 이상의 시간에 대해서는 전혀 다른 차원의 접근 방법이 필요할 것 같군요.
이 논문은 training time과 test time의 data distribution이 다른 경우, domain adaptation을 효과적으로 할 수 있는 새로운 접근 방법을 제시합니다.
Domain Adaptation
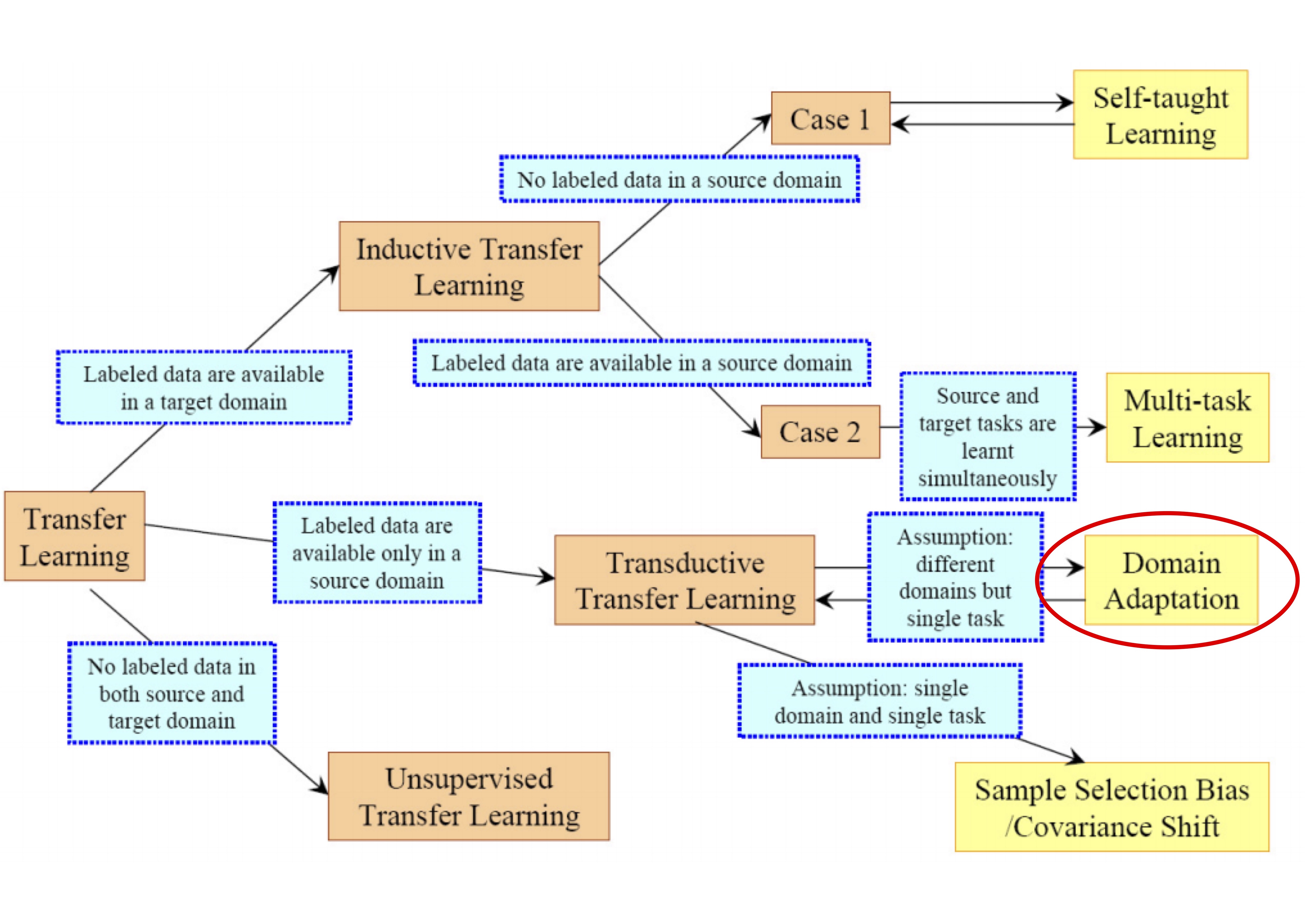
Domain Adaptation (DA)은 training distribution과 test distribution 간에 차이가 있을 때 classifier 또는 predictor의 학습 문제를 다루는 연구 분야입니다. 즉, source (training time)과 target (test time) 사이의 mapping을 통해 source domain에서 학습한 classifier가 target domain에서도 효과적으로 동작하는 것을 목표로 합니다. DA는 아래 그림에서 보는 것처럼 Transfer Learning에 속하며, source domain에서만 labeled data가 존재하는 경우를 다룹니다.
이 논문에서 풀려고 하는 문제는, input space $X$에서 가능한 label의 집합인 로의 classification task입니다. 이 때 source domain과 target domain을 각각 $\mathcal{D}_S$와 $\mathcal{D}_T$로 정의합니다.
이 논문에서 제안하는 알고리즘의 목표는 target domain 의 label에 대한 정보가 없더라도 target risk $R_{\mathcal{D}_T}(\eta)$가 낮도록 classifier 를 만드는 것입니다.
먼저, 두 도메인 간의 거리는 아래 식과 같이 $\mathcal{H}$-divergence로 계산할 수 있습니다.
여기서 $\mathcal{H}$가 symmetric하다고 가정하면 empirical $\mathcal{H}$-divergence는 아래 식과 같이 계산됩니다.
그런데, 일반적으로 이 값을 정확하게 계산하는 것이 어렵기 때문에 아래의 식으로 근사하고 Proxy A Distance (PAD)라고 부릅니다. 이후 이 논문의 실험들에서는 이 PAD 값을 사용합니다.
여기서 $\epsilon$은 classification error입니다. 즉, sample의 출처가 source domain인지 target domain인지 classifier가 정확히 구분할 수 있으면 $\epsilon = 0$ 입니다.
S. Ben-David의 논문에서 target risk $R_{\mathcal{D}_T}(\eta)$의 upper bound를 아래 식과 같이 계산했습니다.
복잡해 보이지만, 요약하자면 결국 target risk 을 줄이려면 source risk 와 domain 간의 distance $\hat{d}_{\mathcal{H}}(S,T)$를 모두 줄여야 하는 것을 알 수 있습니다.
Domain-Adversarial Neural Networks (DANN)
앞의 수식들의 의미를 정리하면 이렇습니다. 도메인이 달라지더라도 충분히 일반화할 수 있도록 모델을 학습하려면, source domain에서의 classifier 성능을 높이면서 한편 domain을 구분하는 성능은 낮아지게 훈련해야한다는 것입니다.
즉, 다른 말로 하면 label classifier의 loss를 minimize하면서 동시에 domain classifier의 loss를 maximize하도록 optimize하는 문제를 푸는 것이 되기 때문에 이 논문에서 adversarial이라고 표현하고 있습니다.
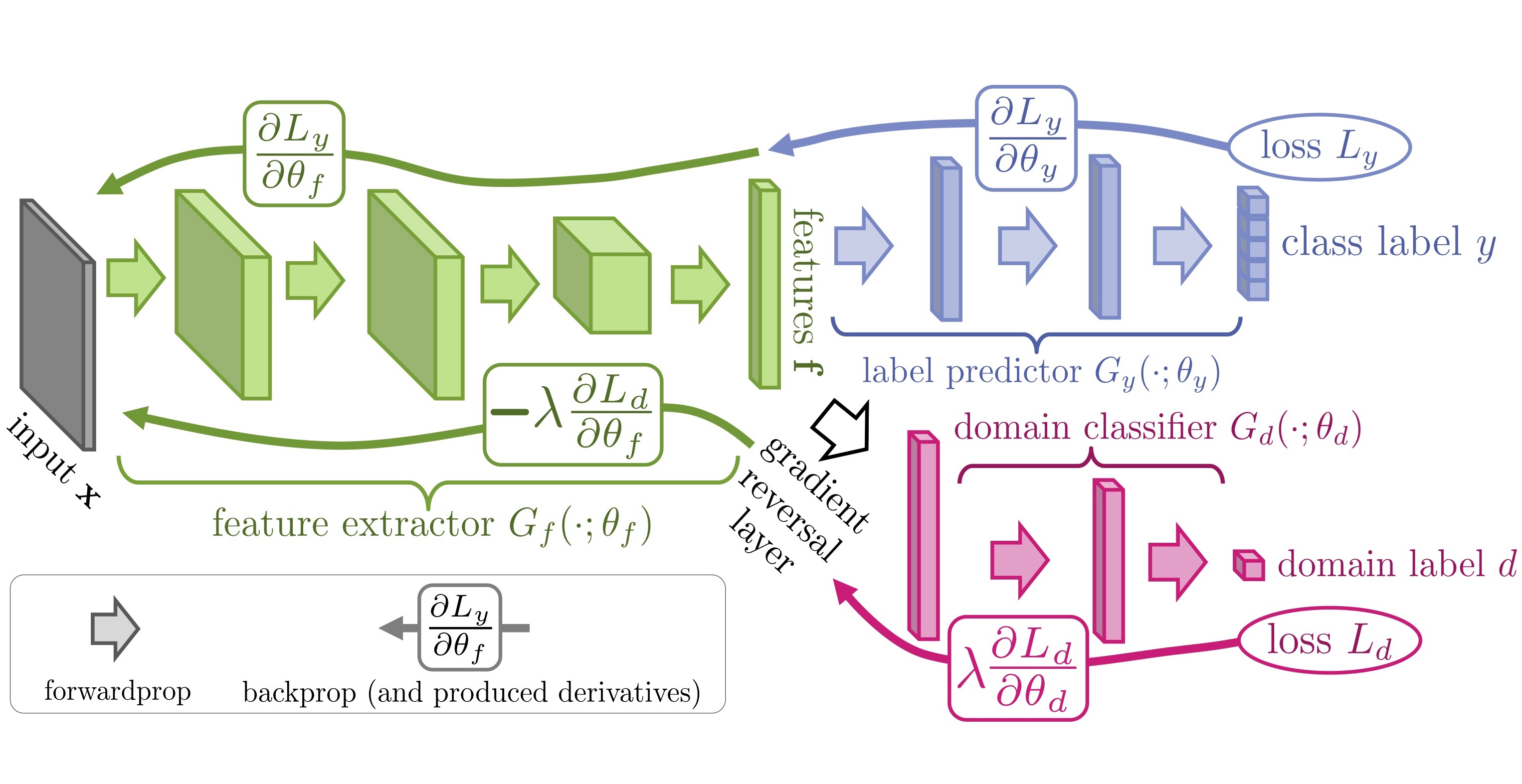
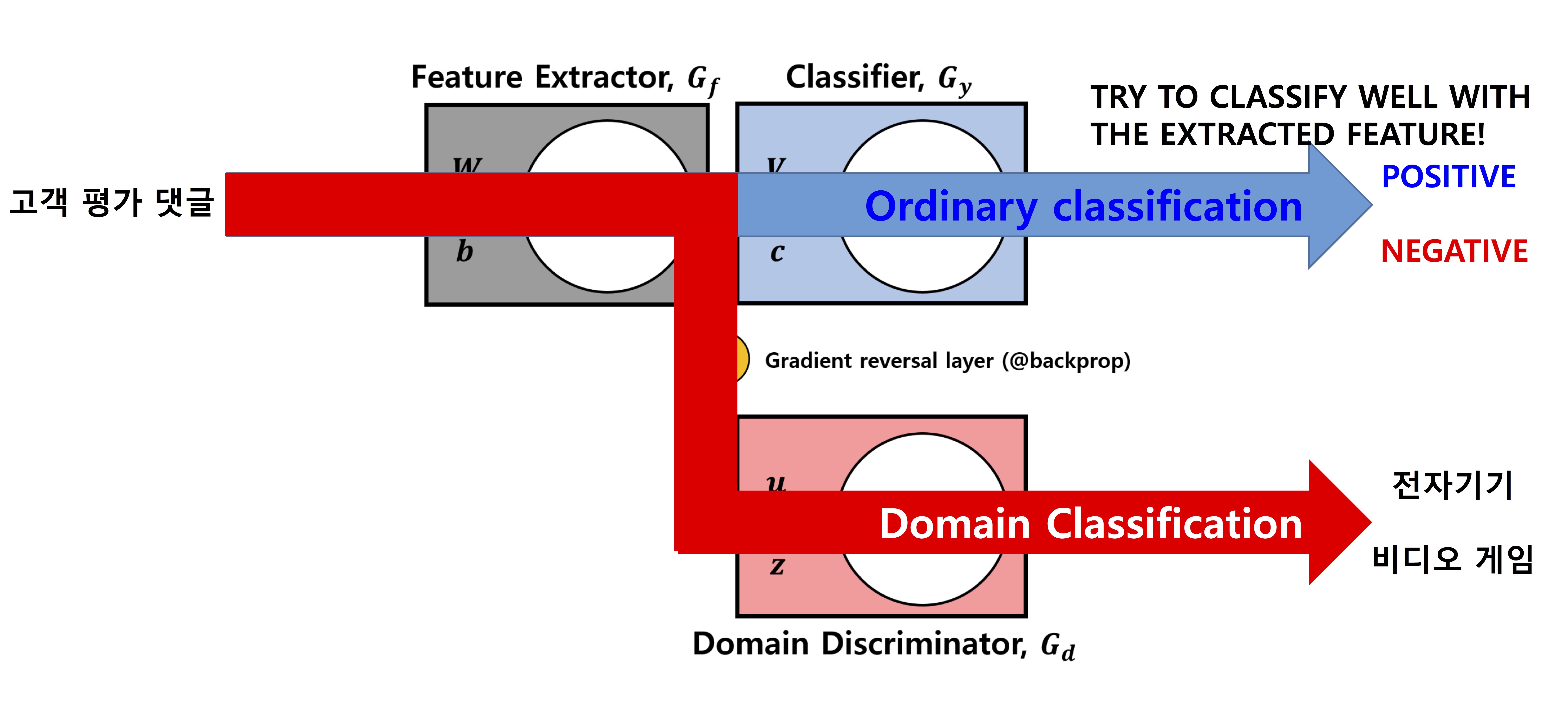
이 논문에서 제안하는 DANN의 구조는 다음과 같습니다.
그림은 크게 green 색의 feature extractor와 blue 색의 label predictor, red 색의 domain classifier로 구성되어 있습니다. 앞에서 설명한 것처럼 domain을 구분하는 성능을 낮추기 위해 추가된 부분이 domain classifier인데, 앞 단의 feature extractor와 gradient reversal layer (black)를 통해 연결되는 것을 볼 수 있습니다.
일반적인 neural network에서는 backpropagation을 통해 prediction loss를 줄이는 방향으로 gradient를 계산하는데, DANN에서는 domain classifier가 prediction을 더 못하게 하려는 것이 목적이므로 gradient reversal layer에서 negative constant를 곱해 부호를 바꿔 전달하는 것입니다.
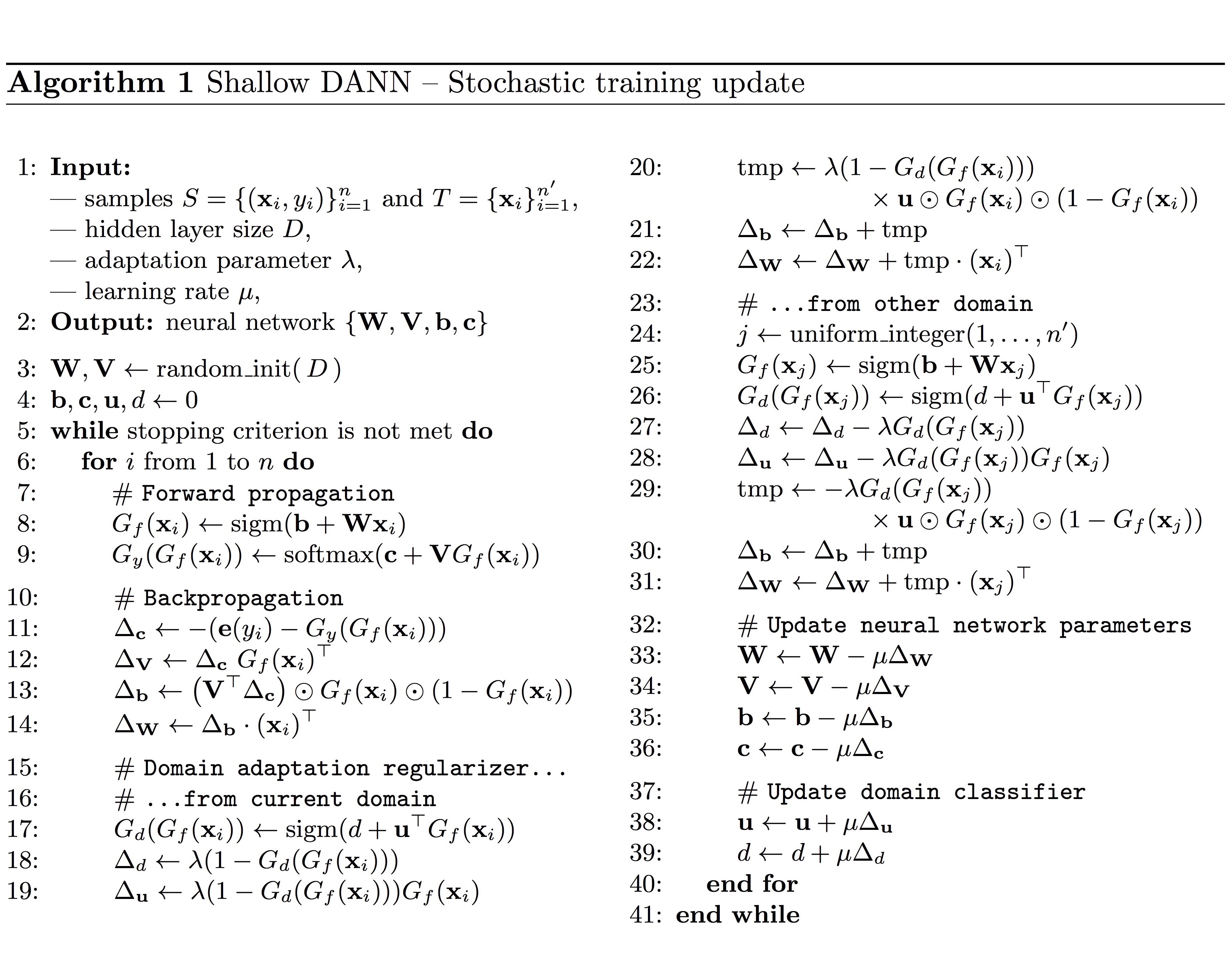
이 논문에서는 앞에서 보인 알고리즘을 inter-twinning moons 2D problem라고 하는 초승달 모양의 distribution을 가지는 dataset에 적용하고 그 결과를 보입니다.
아래 그림에서 red 색의 upper moon이 source distribution의 label 1이고, green 색의 lower moon이 source distribution의 label 0입니다. black 색의 target distribution은 source distribution을 35도 회전시키고 label을 제거해서 만들었습니다.
위 그림의 첫 번째 “Label Classification” 컬럼을 보면, (a) 일반 NN의 경우 target sample (특히 D 부분)을 완전히 분리하고 있지 못하지만 (b) DANN은 훨씬 잘 분리하고 있는 것을 볼 수 있습니다.
또한, 위 그림의 세 번째 “Domain Classification” 컬럼을 보면, (a) 일반 NN의 경우도 source와 target을 잘 분리하지 못하지만 (b) DANN은 훨씬 더 구분하지 못하는(이 논문에서 원하는 대로) 것을 확인할 수 있습니다.
다음은 MNIST와 SVHN 데이터셋을 사용한 실험 결과를 보여주는 그림입니다.
그림에서 blue 색은 source domain의 example이고, red 색의 target domain의 example을 보여줍니다. (a) DA를 거치기 전에는 두 색깔이 분리되어 있는 반면, (b) 거친 후에는 분리되지 않고 잘 섞여 있는 것을 확인할 수 있습니다.
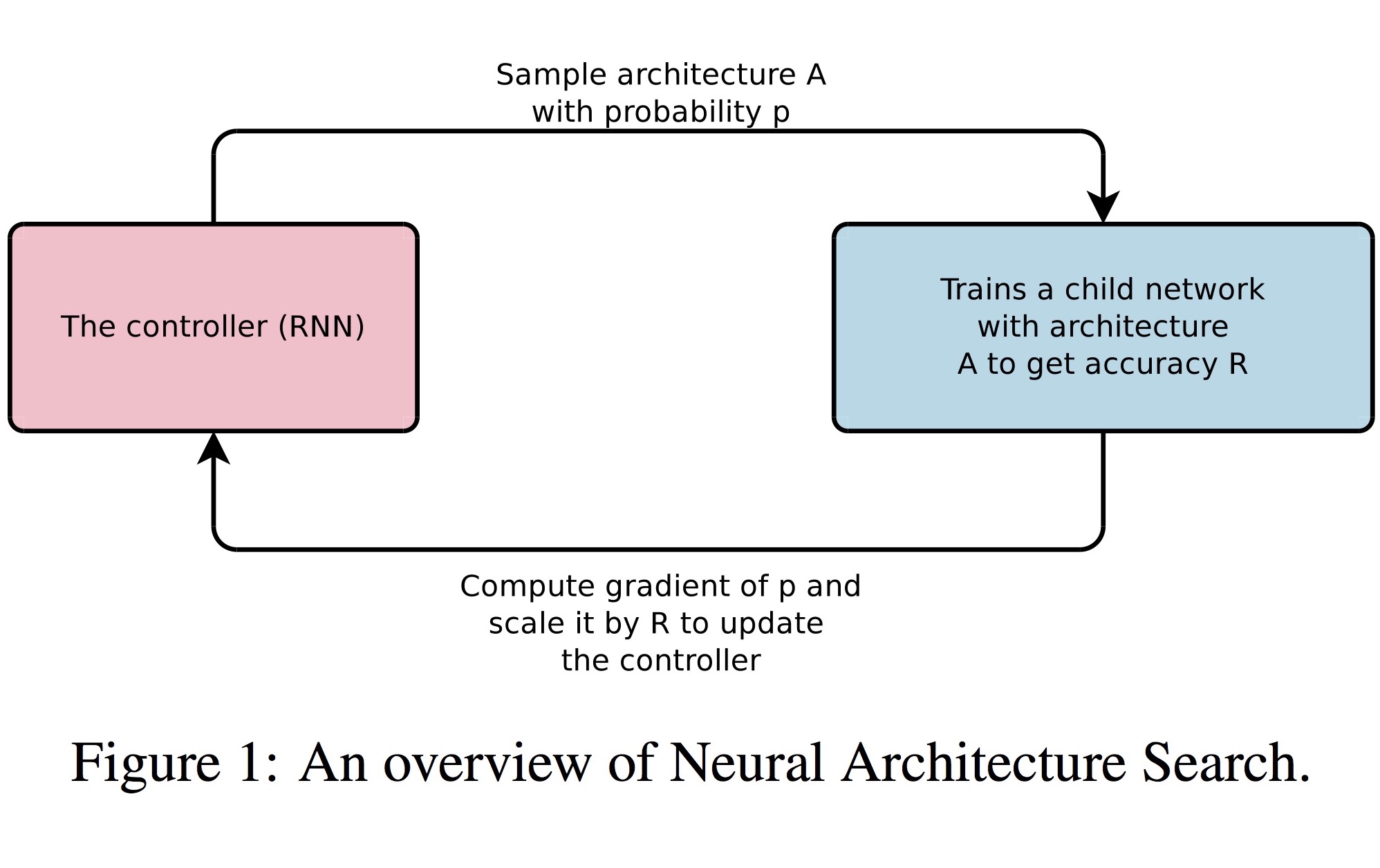
 (그림 출처: 서기호 님의 슬라이드 “Neural Architecture Search with Reinforcement Learning”)
(그림 출처: 서기호 님의 슬라이드 “Neural Architecture Search with Reinforcement Learning”)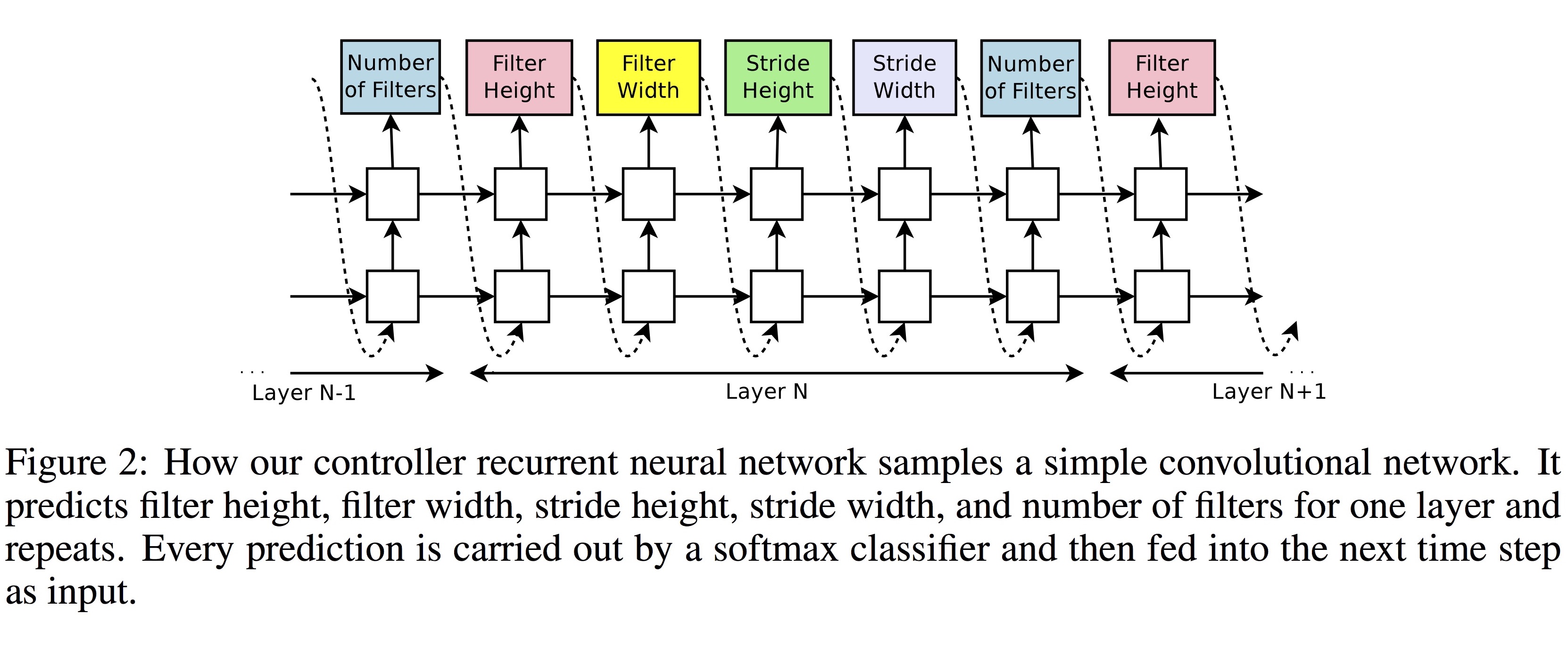

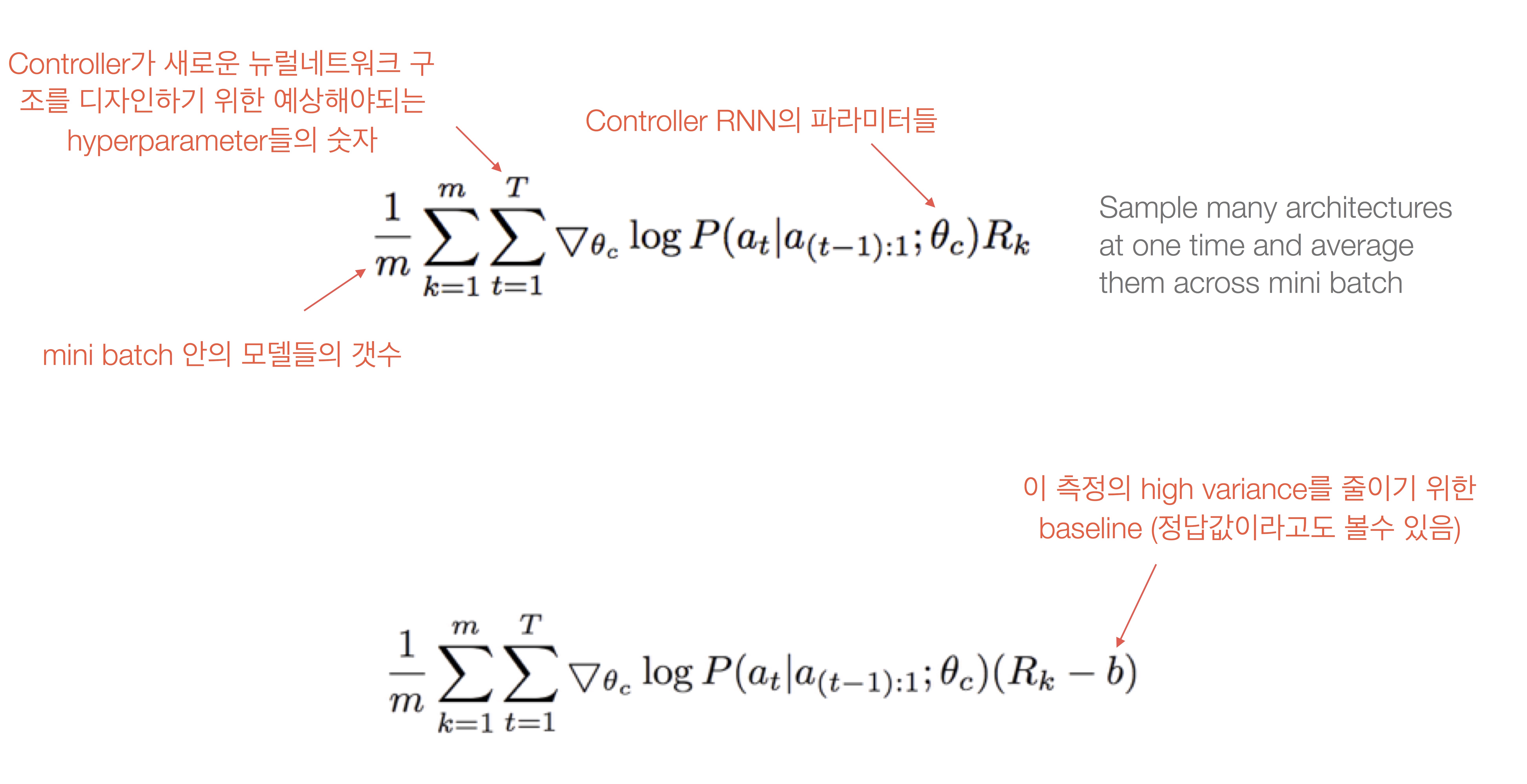
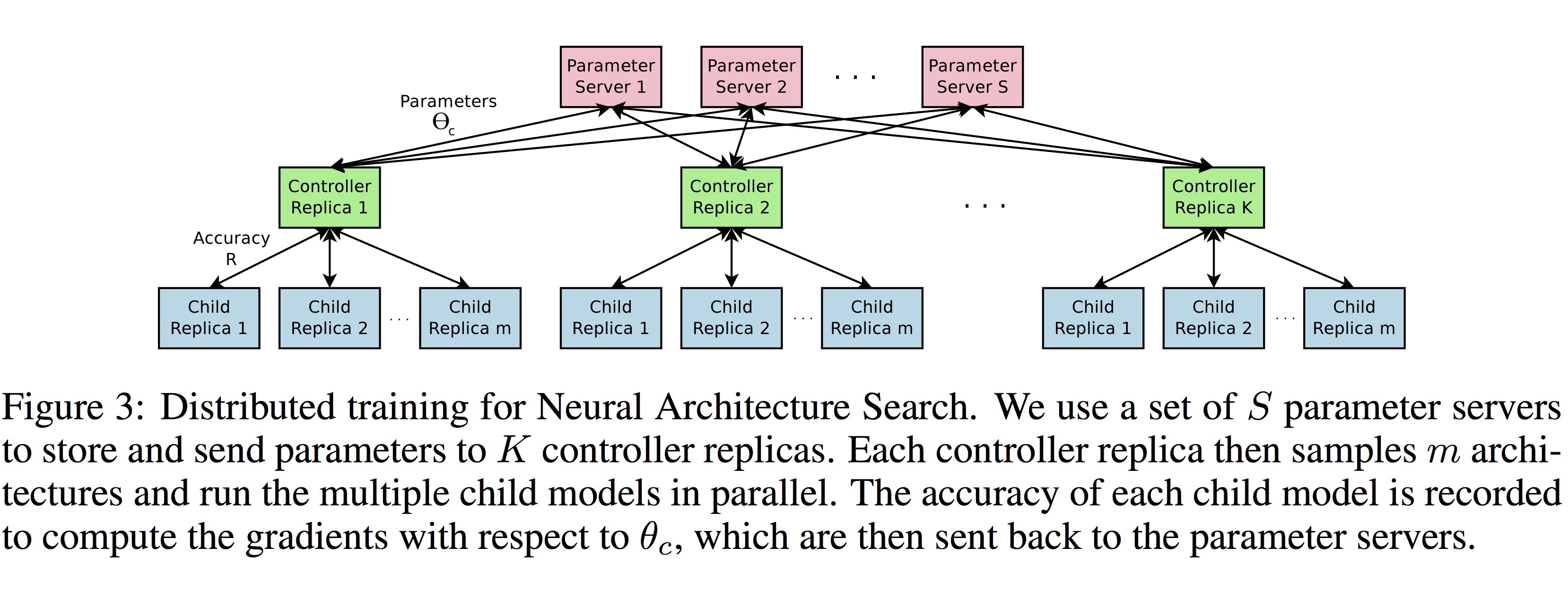
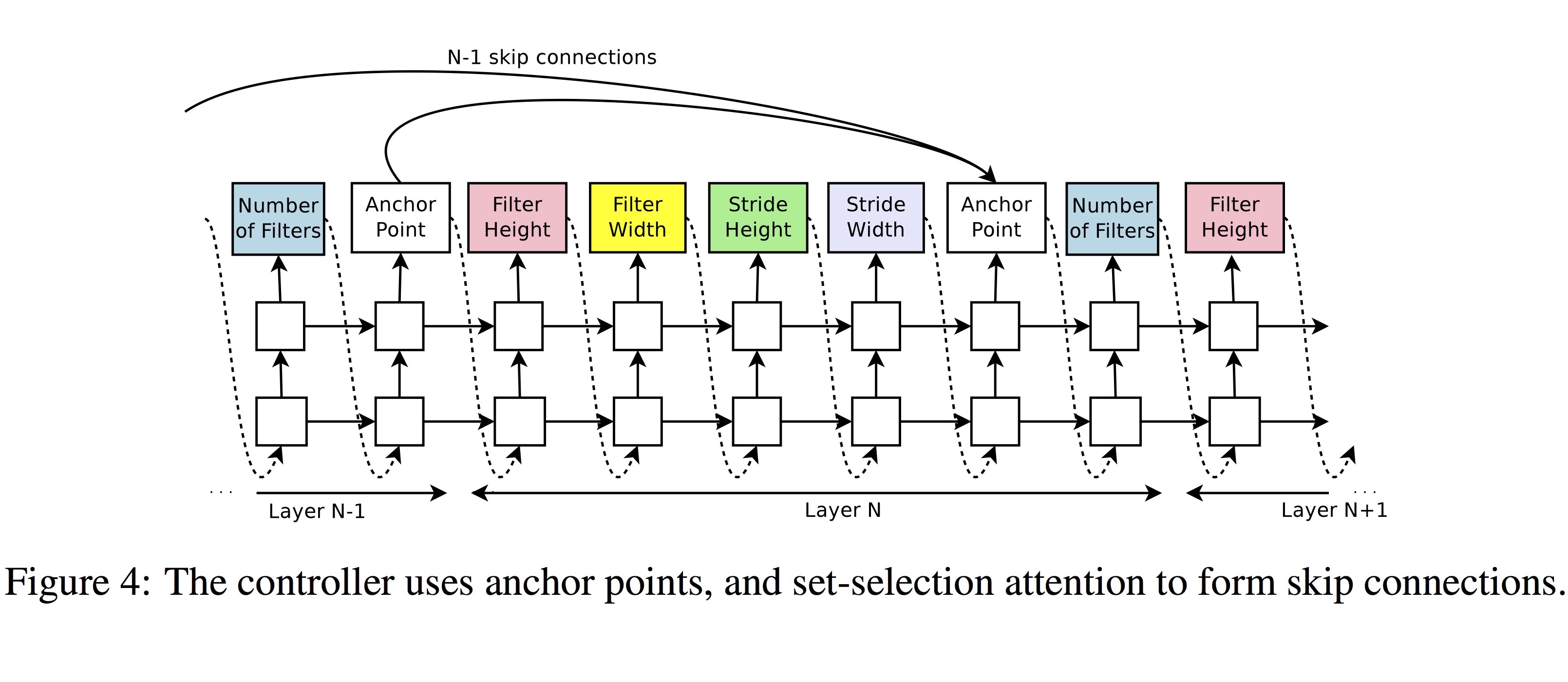

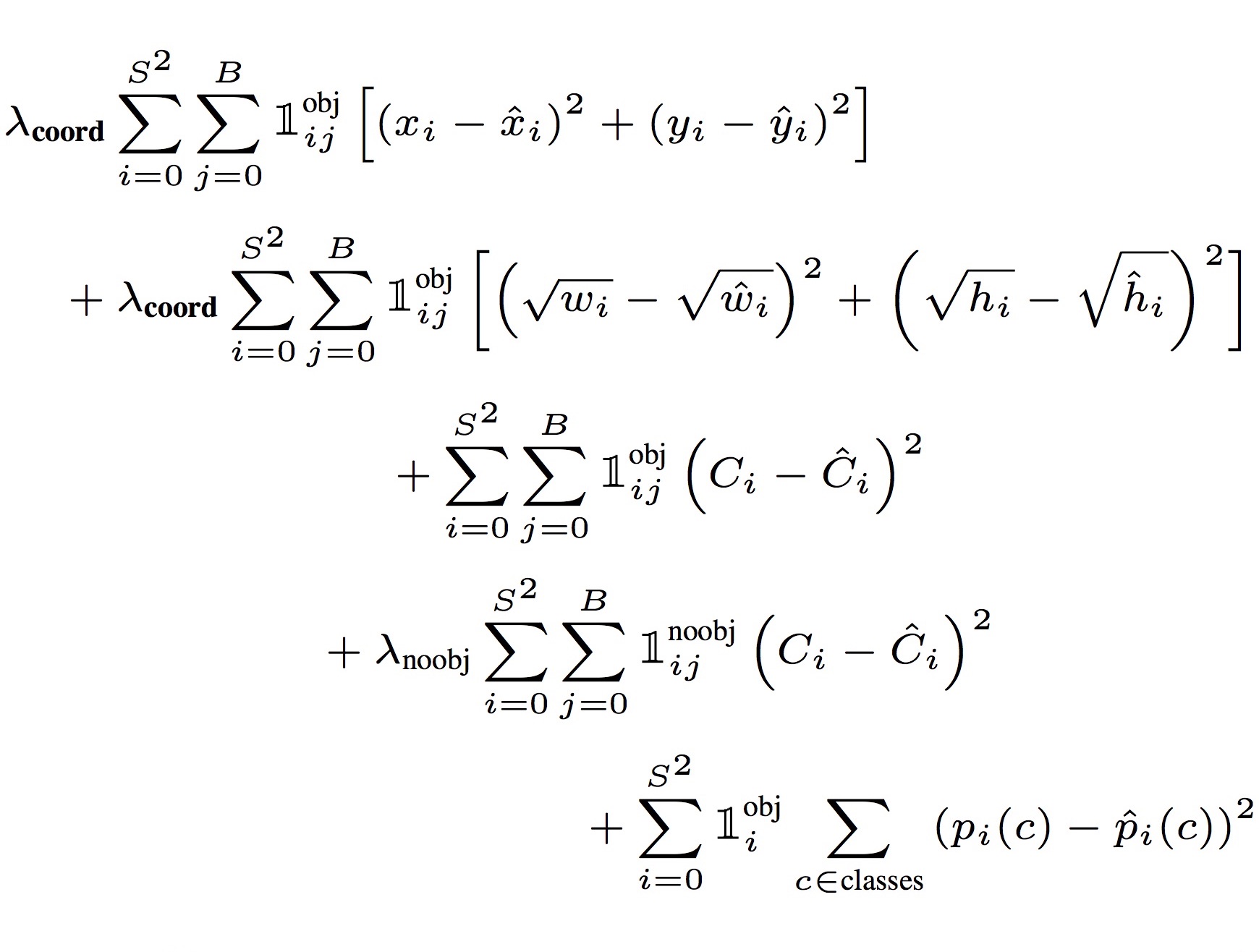

 (그림 출처: TensorFlow의
(그림 출처: TensorFlow의 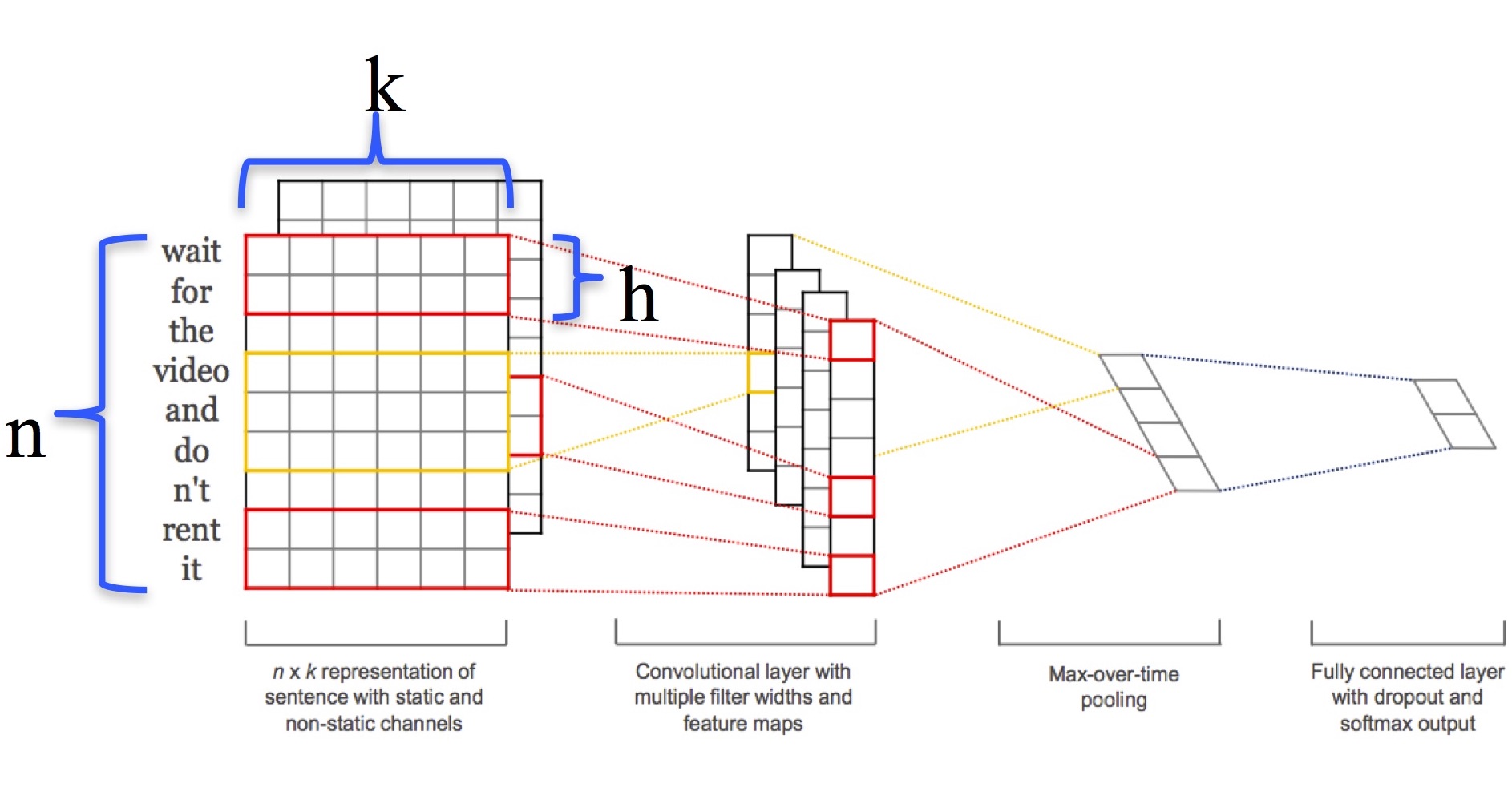

 (그림 출처: 유재준 님의 슬라이드
(그림 출처: 유재준 님의 슬라이드