On Human Motion Prediction Using Recurrent Neural Networks
05 Jun 2017 | PR12, Paper, Machine Learning, RNN이번 논문은 2017년 CVPR에서 발표될 예정인 “On Human Motion Prediction Using Recurrent Neural Networks”입니다.
이 논문은 RNN을 써서 1초 미만의 human motion을 예측할 때, 단순한 모델을 사용하더라도 state-of-the-art 수준의 성능을 낼 수 있는 3가지 개선 방안을 제시합니다.
Related Work
Motion forecasting (Motion prediction) 문제는 인간의 과거의 동작으로부터 가까운 미래의 가장 가능성이 높은 3D 자세(pose)를 예측하는 것입니다.
전통적으로 이 분야의 연구는 Markov 모델에 기반한 것이었는데, 비교적 최근인 2015년부터 RNN을 활용하는 연구들이 등장했습니다. 이 논문에서는 특히 K. Fragkiadaki의 CVPR 2015 논문 “Recurrent Network Models for Human Dynamics”과 A. Jain의 CVPR 2016 논문 “Structural-RNN: Deep Learning on Spatio-Temporal Graphs”를 언급하고 있습니다.
K. Fragkiadaki의 “Recurrent Network Models for Human Dynamics”
- LSTM-3LR: joint angle들의 sequence를 받아 sequence를 출력하기 위해 3계층의 LSTM 네트워크를 사용.
- ERD (Encoder-Recurrent-Decoder): Motion data를 raw input 그대로 사용하지 않고 encoder를 거친 feature를 input으로 사용.
- Error가 축적되므로 training할 때도 noise를 점점 늘림 (noise scheduling).
- short-term prediction에서는 LSTM-3LR이 제일 잘함.
A. Jain의 “Structural-RNN: Deep Learning on Spatio-Temporal Graphs”
- 움직임이 비슷한 팔끼리, 다리끼리 따로 네트워크를 구성.
- aperiodic한 움직임은 잘 예측하지 못함.
Evaluation Criteria
이들 최근 연구의 performance validation 방법은 두 가지입니다.
(1) quantitative prediction error
- 단기 (short-term) 예측
- mean-squared loss로 측정 (angle-space)
(2) qualitative motion synthesis
- 장기 (long-term) 예측
- 적당한 (feasible) motion 생성
하지만 최근의 연구들은 (1)(2)의 관점에서 성능이 만족스럽지 않았습니다.
Problems
이 논문에서는 최근 연구들의 문제를 크게 네 가지로 들고 있습니다.
First frame discontinuity
- 기존 연구에서는 ground truth와 첫 번째 prediction된 frame 사이에 큰 차이(discontinuity)가 발생합니다(아래 그림).

Hyper-parameter tuning
- 특히 Noise scheduling이 어렵습니다. Noise scheduling은 test time에 점점 noise가 커질 것에 대비해서 training time에도 점점 더 큰 noise를 주고 학습시키는 것입니다 (일종의 curriculum learning).
Depth and complexity of the models
- Depth가 깊고 복잡한 모델은 training이 어렵습니다.
Action-specific networks
- 기존 연구에서는 특정한 작은 action에 특화된 training을 해왔는데, 반면 deep learning은 다양한 dataset을 사용하는 것이 성능이 좋은 것으로 알려져 있습니다.
바로 다음에 말씀드리겠지만, 요약하자면 이 논문은 문제들을 이렇게 해결합니다.
- First frame discontinuity: residual architecture로 개선.
- Hyper-parameter tuning: 명시적 noise scheduling이 필요 없는 architecture
- Depth and complexity of the models: simple한 model 사용.
- Action-specific networks: 특정 action에 무관하게 전체 data로 training
Solutions
이 논문에서는 해결 방안으로 네 가지 아이디어를 제시합니다.
Sequence-to-sequence architecture
- machine translation과 유사한 형태의 seq2seq 아키텍처를 사용.
Sampling-based loss
- 기존에는 training의 각 time-step에서 ground-truth를 입력으로 집어 넣었지만, 대신 prediction한 결과를 입력으로 넣는 구조를 사용 (sampling-based loss).
- Prediction에 의한 noise가 반영되므로 별도의 noise scheduling이 필요 없어짐.
- 아래 그림에서 green 색 모형은 ground truth, blue 색 모형은 prediction을 의미하며, decoder 출력 값이 다음 step의 입력으로 들어가는 것을 확인할 수 있음.
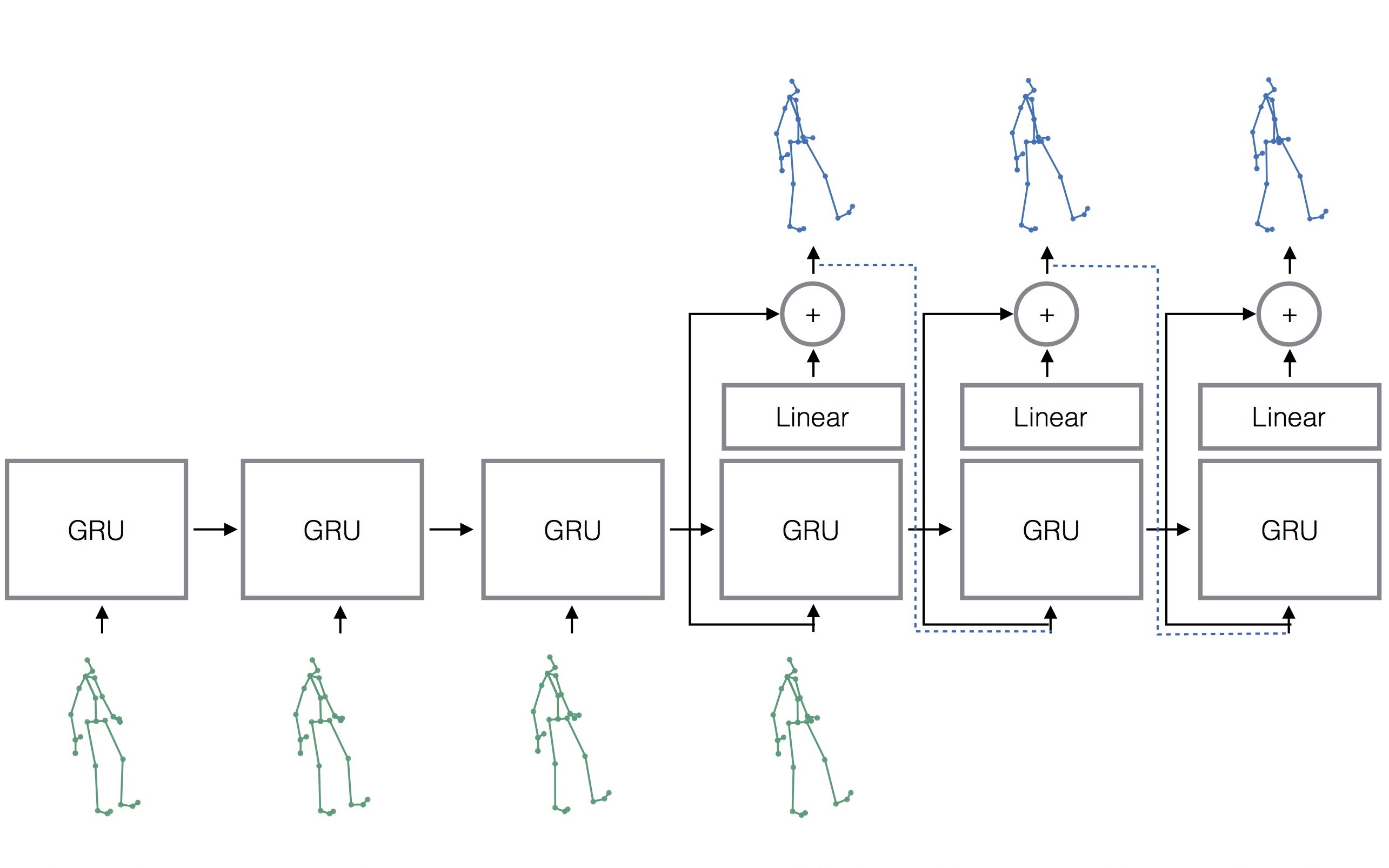
Residual architecture
- RNN cell의 input과 output 사이에 residual connection을 연결.
- 위의 그림의 decoder 부분에서 residual connection을 볼 수 있음.
Multi-action models
- Action specific한 모델을 여러 개 만들지 않고, 여러 action을 prediction하는 하나의 모델을 만들어 전체 dataset으로 training함.
Experimental Setup
이 논문에서는 실험에서 다음의 세 가지를 확인하고자 합니다.
- Seq2seq architecture and sampling-based loss: ground-truth 대신 prediction을 decoder의 입력으로 넣는 효과 확인
- Residual architecture: residual connection의 효과 확인
- Multi-action models: 여러 action을 데이터 전체로 training하는 효과 확인
실험에서 dataset으로는 Human 3.6M을 사용했고, 구현에는 1024개의 GRU (Gated Recurrent Unit)를 사용했습니다. 또한, 마지막 frame에서 움직이지 않는 경우(zero-velocity)를 baseline으로 함께 실험해 비교대상으로 삼았습니다.
Results
아래 그림은 ERD, LSTM-3LR, SRNN과 함께 zero-velocity와 이 논문에서 제안하는 Residual sup. (MA)의 결과를 보입니다. 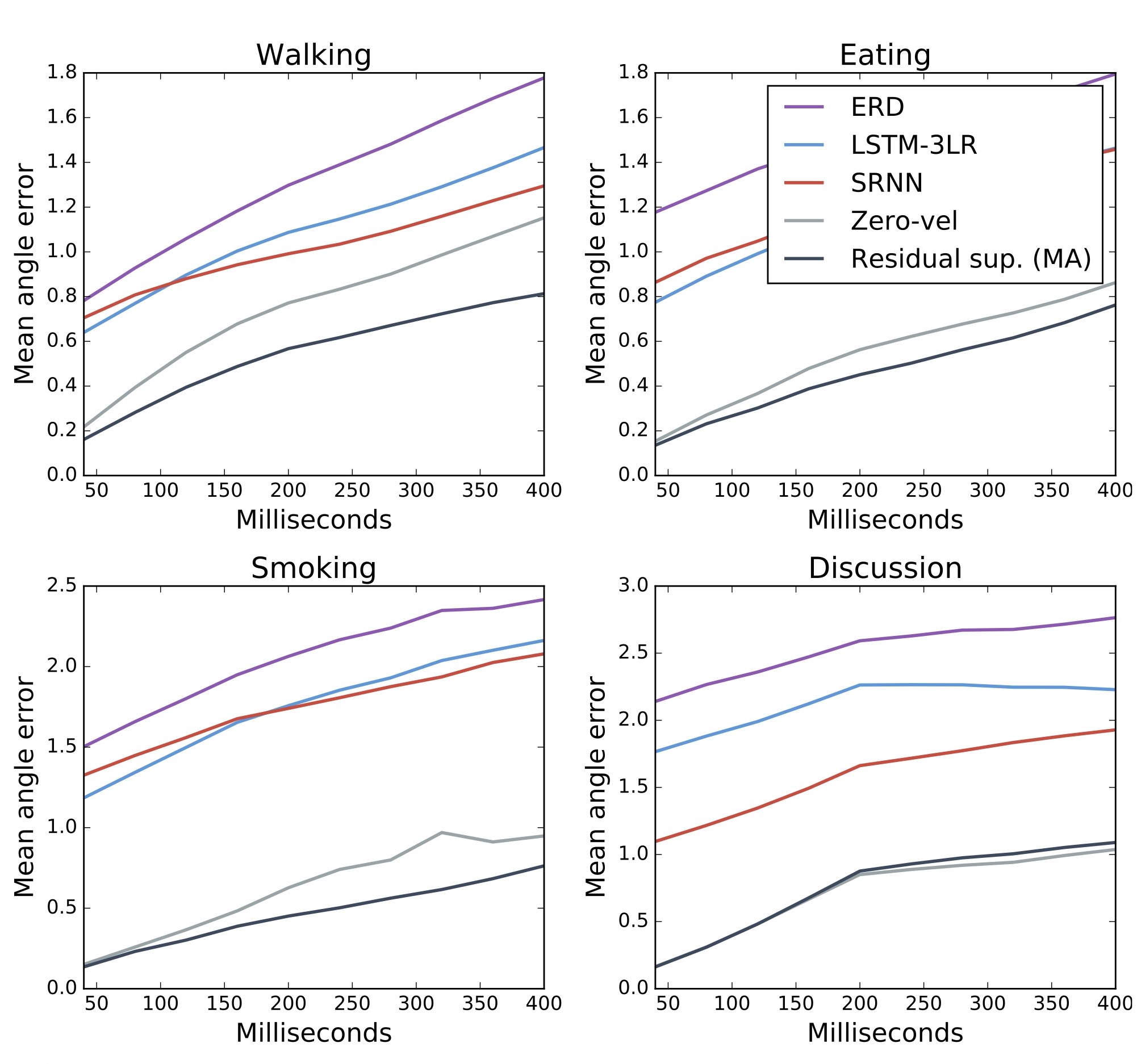
실험 결과에서 몇 가지 알 수 있는 사실을 정리했습니다.
- 제안하는 검은 색 Residual sup. (MA) 라인이 가장 좋은 성능을 보임.
- 의외로 회색 zero-velocity baseline의 성능이 매우 높음.
- Sampling-based loss의 효과로, noise scheduling이 필요 없으며 뛰어난 short-term motion prediction error와 plausible한 long-term motion generation을 달성.
- Residual connection으로 성능 향상.
- single action data를 사용하는 것보다 모든 action data를 사용하는 것이 효과적임 (data quality < data quantity).
- RNN으로 aperiodic motion의 모델링은 어려움.
아래의 동영상은 저자가 공개한 비교 실험 결과입니다.
이 논문은 400ms ~ 1s 수준의 매우 짧은 시간에 대한 prediction을 하는 점이 한계라고 볼 수 있습니다. 즉, 시간이 짧기 때문에 RNN으로 어느 정도 prediction이 가능한 것으로 보입니다. 그 이상의 시간에 대해서는 전혀 다른 차원의 접근 방법이 필요할 것 같군요.
– Jamie;
References
- Julieta Martinez의 논문 “On Human Motion Prediction Using Recurrent Neural Networks”
- Julieta Martinez의 YouTube 동영상
- Julieta Martinez의 GitHub “una-dinosauria/human-motion-prediction”
- 엄태웅 님의 슬라이드 “On Human Motion Prediction Using Recurrent Neural Networks”
- K. Fragkiadaki의 CVPR 2015 논문 “Recurrent Network Models for Human Dynamics”
- A. Jain의 CVPR 2016 논문 “Structural-RNN: Deep Learning on Spatio-Temporal Graphs”
- Google GitHub 블로그의 seq2seq
- Human 3.6M dataset 공식 웹 페이지
- K. Cho의 논문 “On the Properties of Neural Machine Translation: Encoder-Decoder Approaches”