GitHub에 블로그를 만들려면 알아야 할 것이 많습니다. 티스토리나 WordPress를 쓰던 것과는 사뭇 다른 방식이라서 처음에 고생하게 되는데, 이 블로그를 꾸미며 배운 것들을 간단히 정리해 보겠습니다.
GitHub의 블로그는 GitHub Pages가 제공하는 기능으로, GitHub repository에서 직접 static한 웹 페이지를 호스팅합니다. 이를 위해서는 Jekyll이라는 정적 사이트 생성기(static site generator)를 설치해야 합니다. Jekyll 자체가 ruby 언어의 gem 형태로 번들 되기 때문에, 터미널에서 설정하고 설치하는 작업이 약간 필요합니다.
Jekyll Now
먼저 알아야 할 것은, GitHub pages에서 Jekyll을 사용하는 것이 일반적이지만 Jekyll의 모든 기능이 GitHub pages에서 허용되는 것은 아니라는 점입니다. 예를 들어, Jekyll의 plugin 기능은 GitHub에서 동작하지 않습니다. 그래서 Jekyll 자체의 문서만 보면서 작업을 하다 보면 GitHub에서 여러가지 문제가 생길 수 있습니다. 또한 ruby의 설치 등 잡다한 과정이 다소 귀찮을 수도 있습니다.
검색해 보면 Jekyll로 GitHub에 블로그를 더 쉽게 시작하도록 도와주는 프로젝트들이 있습니다. 그 중에서 검색 결과 최상단에 나오는 것이 Jekyll Now이며, 저도 사용했습니다. 역시 또 알아야 할 것은, Jekyll Now 또한 Jekyll로 GitHub에 블로그를 설치하는 여러 방법 중의 하나일 뿐이며 제약점도 많이 가지고 있다는 점입니다. 아래에서 더 설명하겠습니다.
Theme
Jekyll의 웹페이지에는 마치 많은 Theme이 있는 것처럼 보입니다. 하지만 Jekyll Now를 사용할 경우, Jekyll Now에서 검증된 별도의 Theme을 사용하는 것이 훨씬 쉽습니다. Jekyll Theme을 적용하는 GitHub Pages의 공식 문서의 설명은 Jekyll Now에서는 동작하지 않습니다. 섣불리 시도했다가 ruby의 알 수 없는 에러 메시지들을 만나는 것은 물론, 파일도 날아가는 경우가 있습니다. Jekyll Now의 새로운 Theme을 적용하는 것은 처음 GitHub에서 fork하는 것부터 시도하는 것이 가장 쉬운 방법인 것 같습니다.
Front Matter
Front matter는 각 페이지에서 Jekyll에 특별한 속성 정보(메타 데이터)를 전달하는 방법입니다. Front matter는 각 페이지(html 또는 markdown)의 시작 부분에 아래처럼 ---로 구분된 블록 형태로 되어 있습니다.
---
layout: post
title: Blogging Like a Hacker
---
<!--
your markdown or html starts here
-->
Front matter는 다소 생소한 yaml 문법으로 되어 있지만 사용하기 쉽습니다. 위의 예에서 보인 layout, title 외에도, date, permalink, published, categories, tags 등을 설정해 줄 수 있습니다.
먼저, _config.yml을 수정하고 _includes 디렉토리에 mathjax_support.html라는 파일을 추가합니다. 그 다음으로 mathjax_support.html 파일을 읽기 위해 _layouts/default.html (Jekyll Now의 기본 theme) 또는 head.html(Lanyon theme)의 <head></head> 사이에 아래의 코드를 추가하면 설정이 완료됩니다.
{% if page.use_math %}
{% include mathjax_support.html %}
{% endif %}
이 때 주의할 것은, 수학식이 들어가는 페이지(예를 들면 새 post)의 front matter 부분에서 use_math : true라고 선언을 해줘야 한다는 점입니다. 방금 위에서 보인 코드라면 아래처럼 수정해주면 됩니다.
---
layout: post
title: Blogging Like a Hacker
use_math: true
---
<!--
your markdown or html starts here
-->
Google Analytics
티스토리, 네이버 블로그와 달리 Jekyll은 자체적으로 방문자 통계를 관리하지 않습니다. 오늘 내 블로그에 몇 명이 방문했고, 어떤 검색으로 찾아 왔는지와 같은 기본 정보를 알기 위해서는 Google Analytics 서비스를 사용합니다.
이 논문은 single image super-resolution (SR) 문제에 최초로 deep learning을 적용한 연구입니다. 이후 거의 모든 super-resolution 연구들이 이 논문에서 제안된 SRCNN을 기반으로 하고 있습니다.
Introduction
SR 문제는 하나의 저해상도 이미지에서 고해상도 이미지를 복원하는 것으로, 하나의 입력에 대해 복수의 결과물이 나올 수 있는 어려운 (ill-posed) 문제로 알려져 있습니다.
지금까지 SR 문제를 풀어 왔던 가장 대표적인 방법은 example-based 방법과 sparse-coding-based 방법이었습니다. Example-based 방법은 저해상도/고해상도 이미지 patch의 쌍을 미리 dictionary 형태로 구축하는 방식이고, sparse-coding-based 방법은 입력된 저해상도 이미지를 sparse coefficient로 encoding했다가 dictionary를 거쳐 복원하는 방식입니다.
Convolutional Neural Networks for Super-Resolution
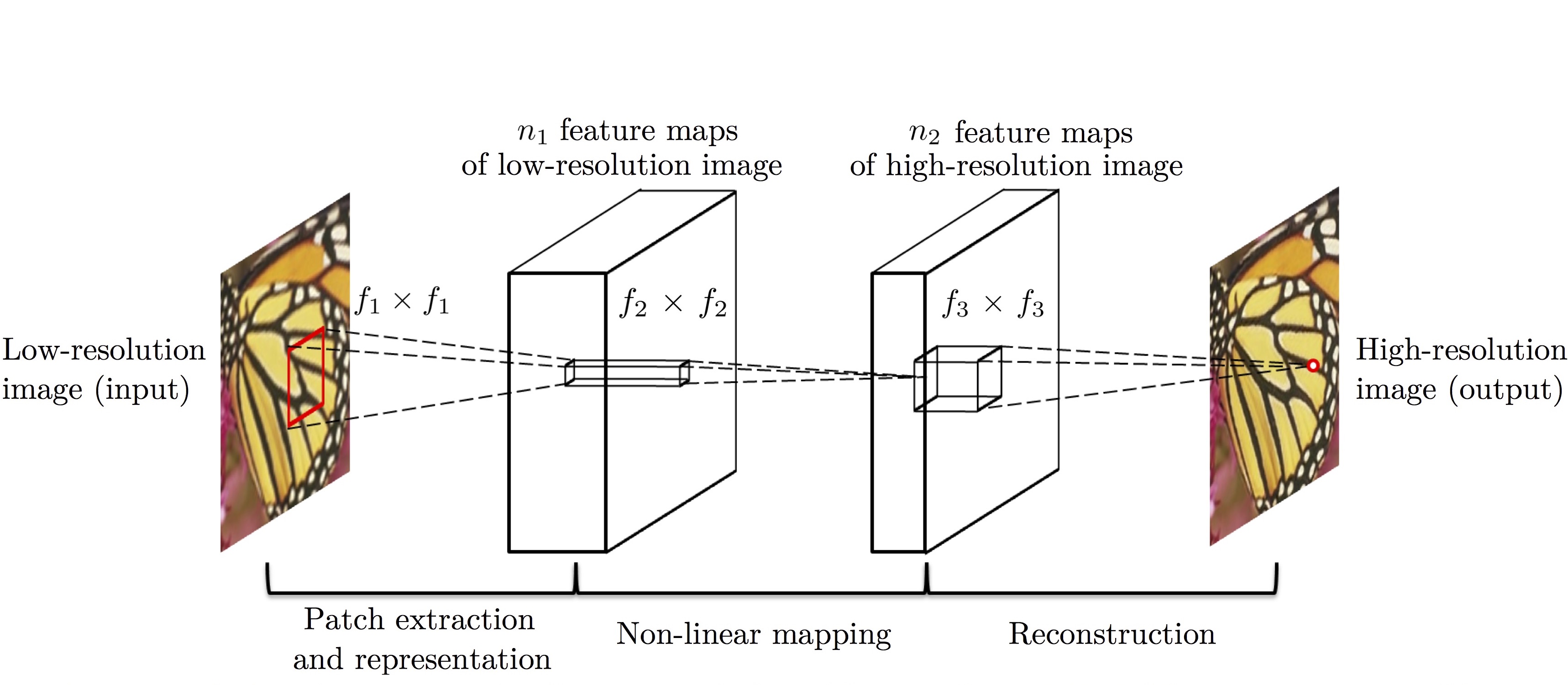
이 논문에서 입력 저해상도 이미지는 $\mathbf{Y}$, 복원한 출력 고해상도 이미지는 $F \left( \mathbf{Y} \right)$, ground truth 고해상도 이미지는 $\mathbf{X}$로 표현하고 있습니다. 고해상도 이미지를 복원하는 mapping $F$는 아래의 세 가지 연산으로 구성됩니다.
Patch extraction and representation: 저해상도 이미지 $\mathbf{Y}$로부터 patch 추출
Non-linear mapping: 다차원 patch 벡터를 다른 다차원 patch 벡터로 mapping
Mapping function $F$의 학습에는 Mean Squared Error (MSE)를 loss function으로 사용합니다.
Experiments
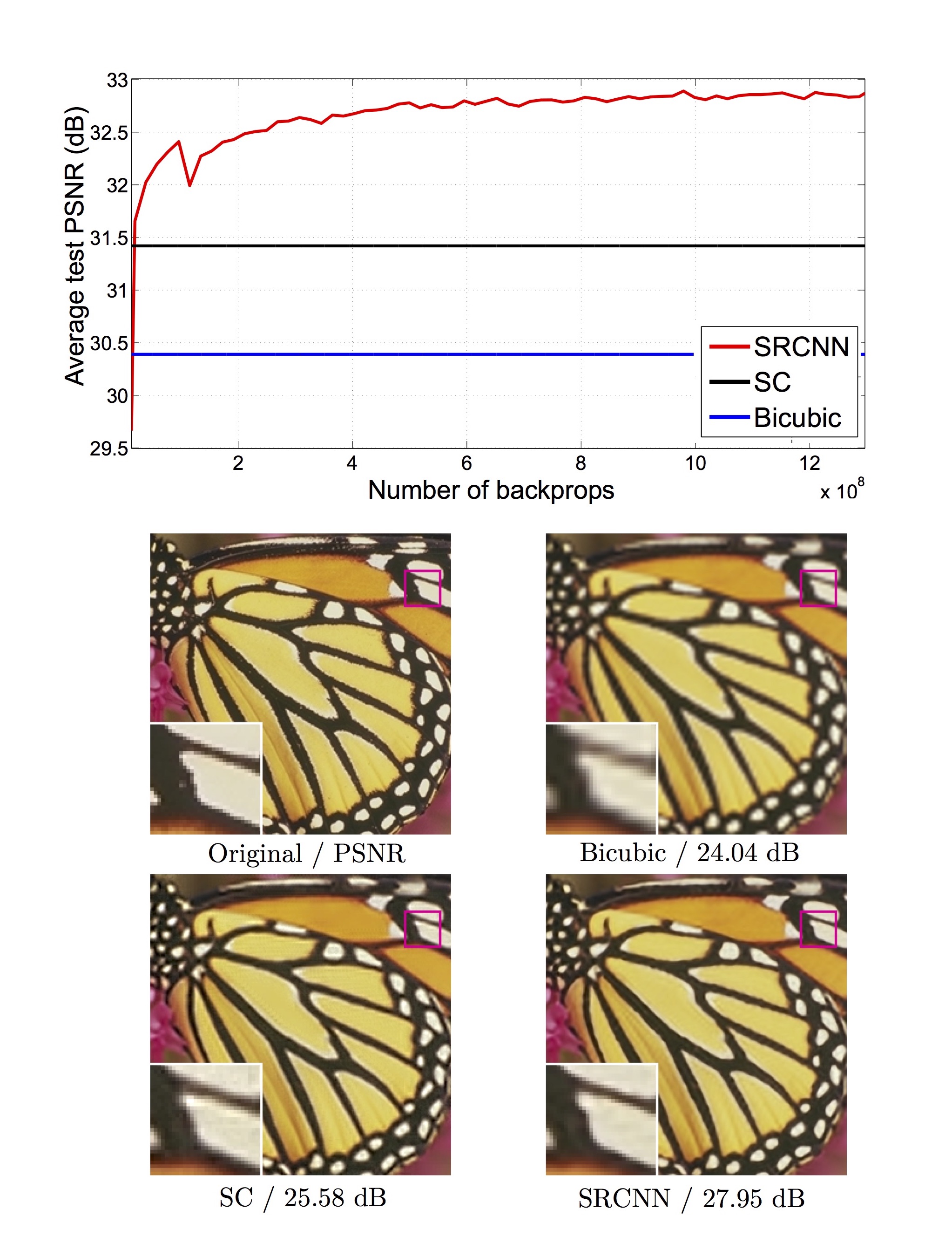
실험 결과를 다른 SR 방법과 비교한 그래프와 출력 이미지를 아래에 보입니다.
먼저 위 그래프에서 sparse-coding-based 방법이나 bicubic에 비해서 SRCNN의 PSNR이 월등히 높은 것을 볼 수 있습니다. 또한 아래 4개의 나비 날개 이미지에서도 SRCNN이 원본에 비교해도 디테일이 크게 떨어지지 않는 좋은 성능을 보이고 있습니다.
이 실험은 super resolution을 luminance 채널 (YCbCr color space의 Y 채널)에만 적용한 것이지만, 저자들은 이후 다른 실험에서 RGB 모든 채널에 적용하면 성능이 더 좋아짐을 보이고 있습니다.
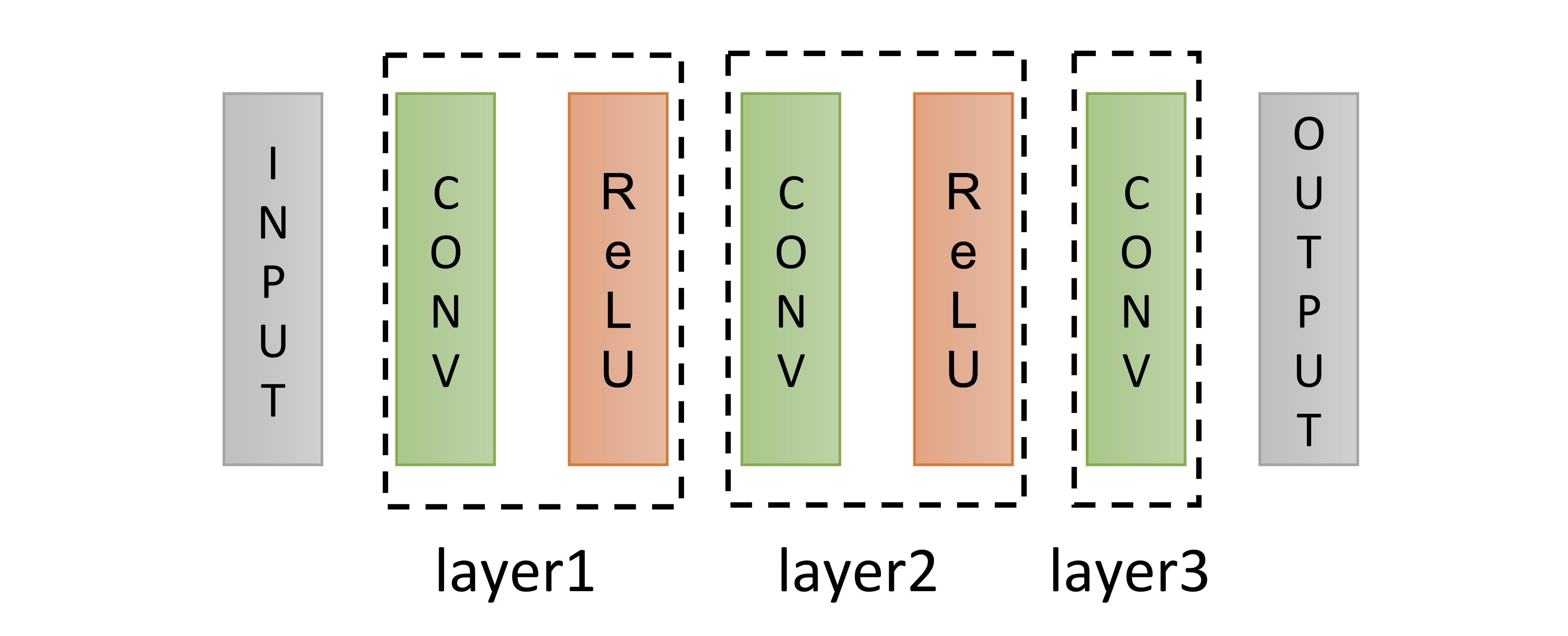
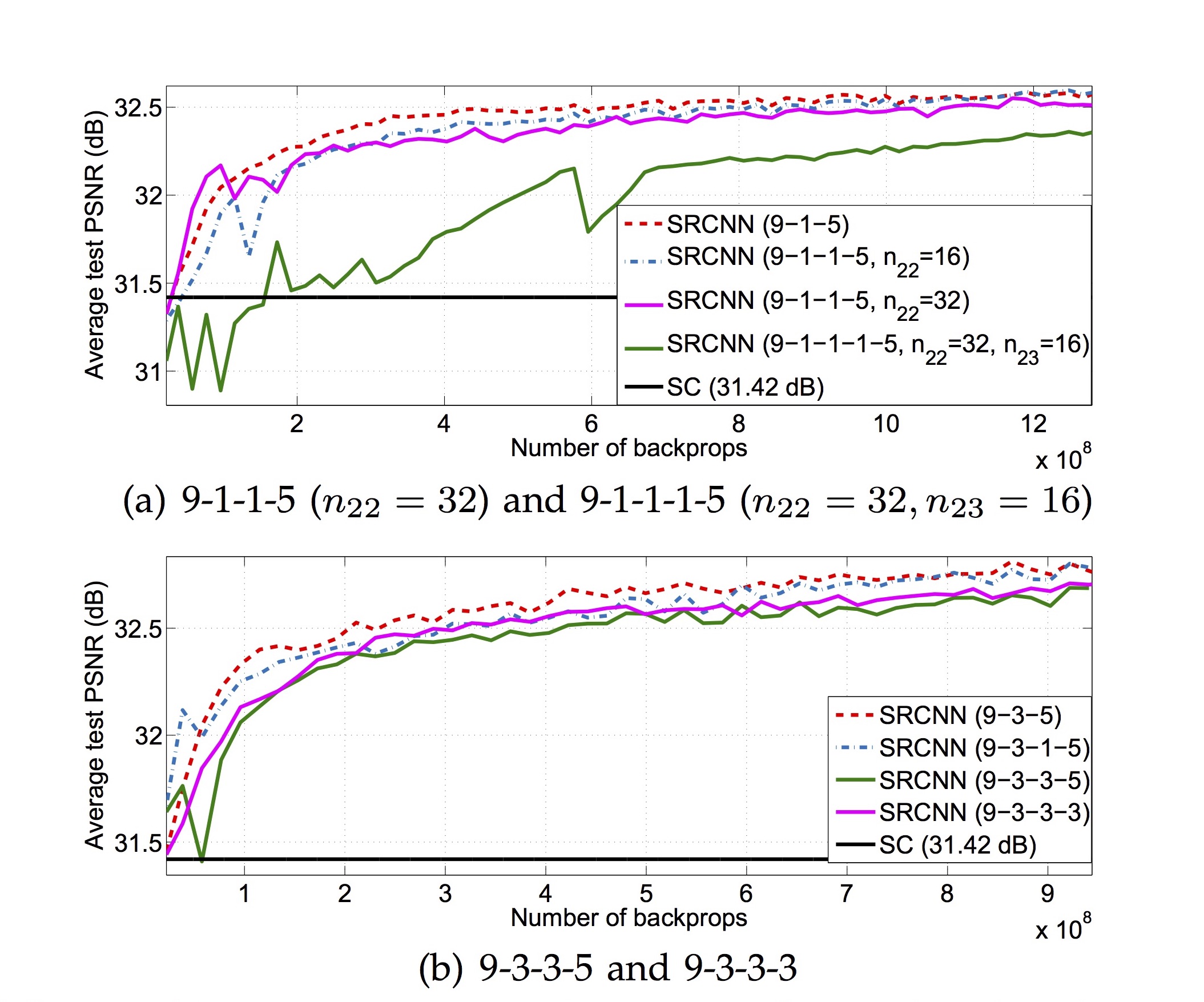
또한, 더 많은 데이터(ImageNet)로 학습했을 때, 더 많은 필터, 더 큰 필터를 사용하면 역시 성능이 향상되는 것을 볼 수 있었습니다. 한편, CNN의 layer 수를 4개, 5개로 더 늘려도 성능이 더 좋아지지 않는 것이 관찰되었는데 그 이유는 training의 어려움으로 추정하고 있습니다 (아래 그림).
다음은 다른 SR 알고리즘들과 3배 확대한 결과물을 비교하는 그림입니다. 이 실험에는 filter size $f_1 = 9$, $f_2 = 5$, $f_3 = 5$을 사용했으며, filter 개수는 $n_1 = 64$, $n_2 = 32$를 사용했고 ImageNet으로 training했습니다.
이 논문의 의의를 정리하면 다음과 같습니다.
기존 sparse-coding-based 방법을 일반화한 방법을 단순한 CNN 구조로 제시
LSTM에 대해서는 추후 다른 논문에서 설명드릴 계획이므로 여기서는 자세히 언급하지 않겠습니다. 간단히 리뷰가 필요하신 분께는 유명한 Christopher Olah의 블로그 post “Understanding LSTM Networks”를 추천 드립니다.
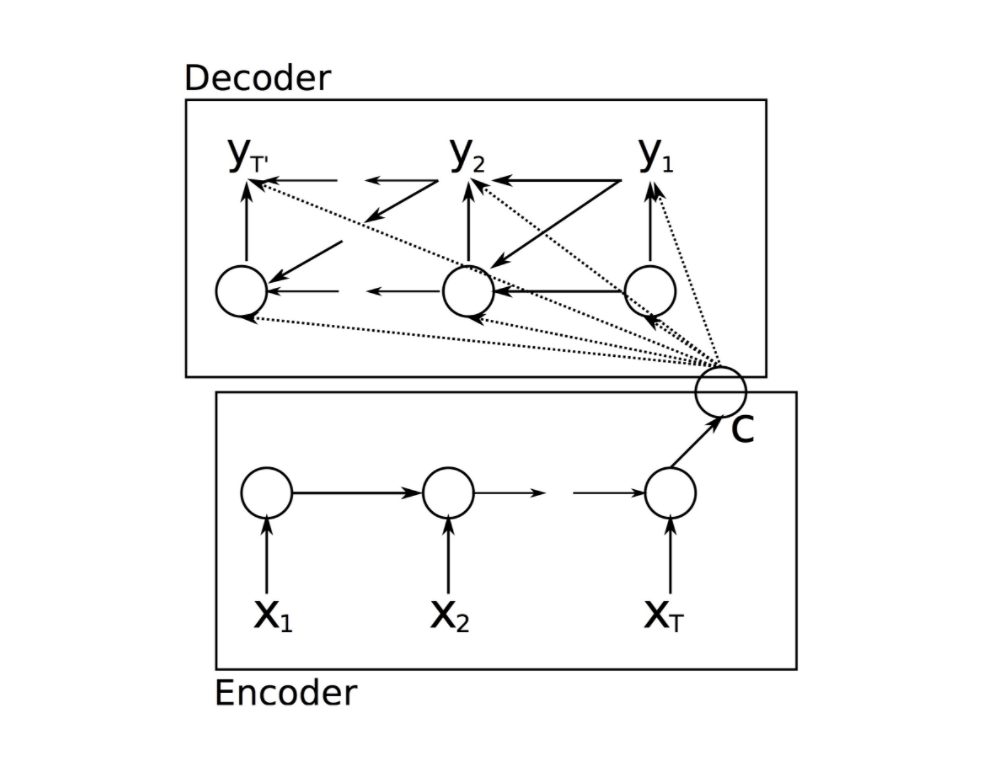
RNN Encoder-Decoder
이 논문에서는 기계 번역에서 뛰어난 성능을 보이는 새로운 neural network 모델을 제안합니다. 저자들은 RNN Encoder-Decoder라고 부르고 있지만, 일반적으로는 seq2seq라는 이름으로 더 잘 알려져 있습니다.
Seq2seq 모델은 아래 그림과 같이 두 개의 RNN 모델로 구성되어 있습니다.
첫 번째 RNN(encoder)은 가변 길이의 문장을 단어 단위로 쪼개어 고정 길이의 벡터로 mapping합니다. 두 번째 RNN(decoder)은 인코딩된 벡터를 하나의 단어씩 디코딩하여 다시 하나의 문장으로 만듭니다.
Encoder가 input sequence $\mathbf{x}$의 각 symbol을 순차적으로 읽는 것에 따라 내부의 hidden state가 update 됩니다. Encoder가 input sequence의 마지막 심볼 (eos, end-of-sequence)을 읽고 나면, hidden state는 전체 input sequence의 summary인 벡터 $\mathbf{c}$가 됩니다.
Decoder는 주어진 hidden state 에서 다음 symbol $y_t$를 생성하도록 train된 또 다른 RNN입니다. 그런데, decoder의 $y_{t}$와 는 이전 symbol $y_{t-1}$ 뿐만 아니라 input sequence의 summary인 $\mathbf{c}$에도 의존성이 있습니다. 즉, decoder의 hidden state는 아래 식과 같이 계산됩니다.
여기서 $f \left( \right)$는 non-linear activation function입니다.
이 두 개의 네트워크는 주어진 source sequence에 대해 target sequence가 나올 조건부 확률을 maximize하도록 함께 training 됩니다. 수식으로 쓰면 아래와 같이 log-likelihood로 표현됩니다.
여기서 $\theta$는 모델의 parameter이고, 이를 추정하기 위해 gradient 기반의 알고리즘을 사용할 수 있습니다.
이 모델은 두 개의 다른 언어(예: 입력-영어, 출력-프랑스어) 간 번역에 사용할 수 있고, 챗봇과 같은 질문-답변 대화 모델로도 사용할 수 있습니다.
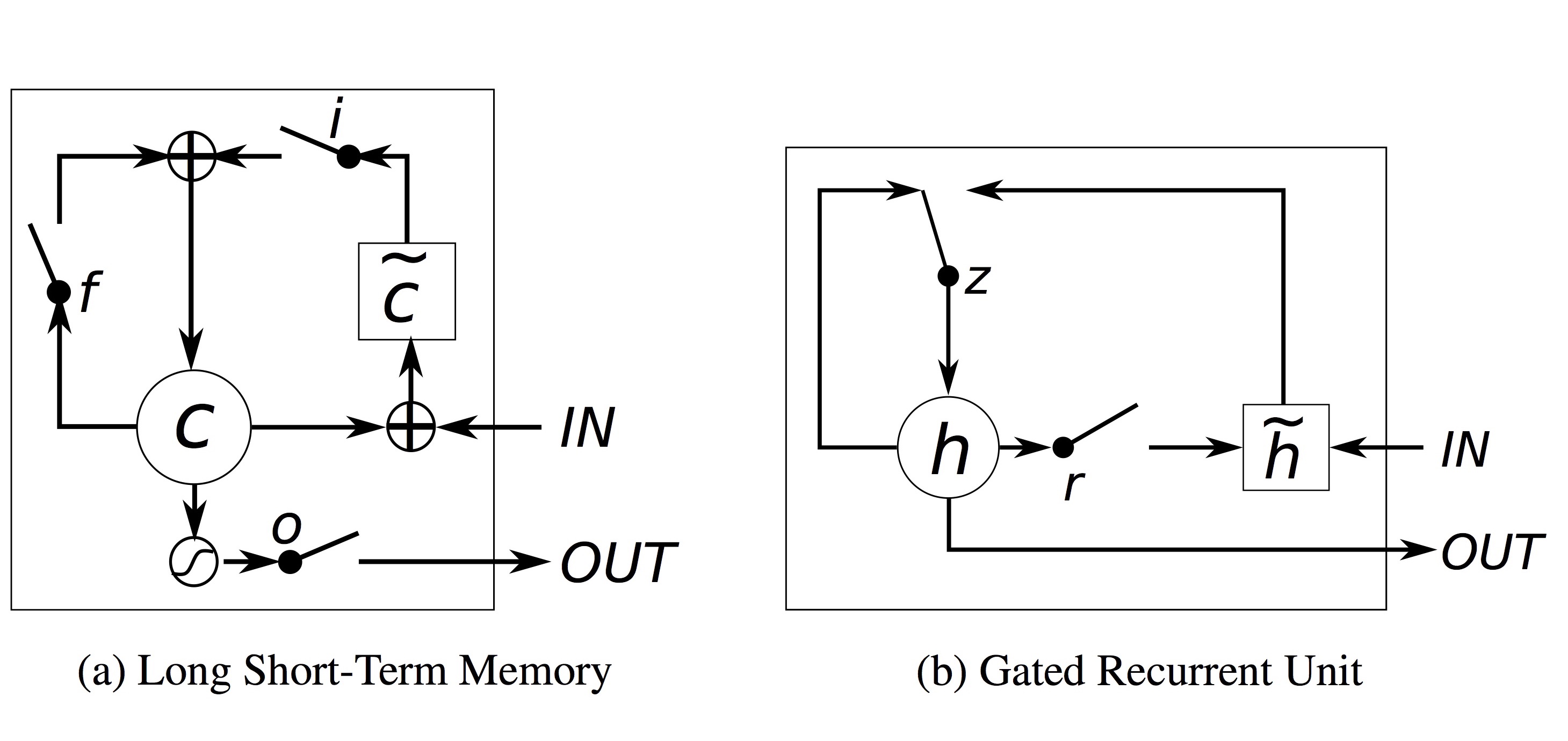
Input, forget, output gate로 구성된 LSTM과 달리, GRU는 update gate $z$와 reset gate $r$ 두 가지로 구성됩니다. Update gate는 과거의 memory 값을 얼마나 유지할 것인지를 결정하고, reset gate는 새 input과 과거의 memory 값을 어떻게 합칠지를 정합니다.
GRU는 LSTM처럼 hidden state과 분리된 별도의 memory cell을 가지지 않습니다. 다시 말하자면 외부에서 보는 hidden state 값과 내부의 메모리 값이 같습니다. LSTM에 있었던 output gate가 없어졌기 때문입니다.
마지막으로, output을 계산할 때 non-linear 함수(tanh())를 적용하지 않습니다.
통계 기반 기계 번역 Statistical machine translation (SMT)는 대규모 데이터를 학습해 만든 통계적 모델을 사용해 번역하는 방법입니다. 기본적으로 단어마다 번역해서 조합하는 방식이며, 현재 가장 많이 사용되는 기계 번역 방식이기도 합니다. 언어학자 없이도 개발을 할 수 있고 데이터가 많이 쌓일수록 번역의 품질이 높아지는 장점이 있습니다.
SMT 시스템의 목표는 주어진 source sentence $\mathbf{e}$에 대해 아래 식의 확률을 maximize하는 translation $\mathbf{f}$를 찾는 것입니다.
이 때, $p \left( \mathbf{e} \; | \; \mathbf{f} \right)$을 translation model, $p \left( \mathbf{f} \right)$을 language model이라고 합니다.
하지만 대부분의 SMT 시스템은 아래와 같은 log-linear 모델 식으로 대신 $\log p \left( \mathbf{f} \; | \; \mathbf{e} \right)$를 계산합니다.
여기서 $f_n$과 $w_n$은 각각 $n$번째 feature와 weight이고, $Z \left( \mathbf{e} \right)$는 normalization constant입니다. Weight는 BLEU score를 maximize하도록 optimize 됩니다.
이 논문에서는 SMT 중에서도 phrase-based 방법을 사용하는데, translation model $p \left( \mathbf{e} \; | \; \mathbf{f} \right)$을 source와 target sentence에서 matching하는 phrase들의 확률로 분해해서 구합니다. 즉, 완전히 새로운 번역기 시스템을 만드는 것이 아니라 구현의 편의를 위해 기존 SMT 시스템의 phrase pair table에 점수를 매기는 부분에만 RNN Encoder-Decoder를 적용했습니다.
Experiments
실험에는 WMT’14 workshop의 English/French translation task를 사용했습니다. 이 task는 영어를 프랑스어로 번역하는 작업인데, 이때 영어 phrase를 프랑스어 phrase로 번역하는 쌍의 확률을 학습하도록 모델을 training하고, 이 모델을 baseline 시스템에 적용해 phrase pair table에 점수를 매기도록 했습니다.
Baseline의 phrase 기반 SMT 시스템으로는 대표적인 free software SMT 엔진인 Moses를 default setting 상태로 사용했습니다.
기타 실험에서 사용한 parameter들과 training 조건은 아래와 같습니다.
1000 hidden units (GRU)
SGD with Adadelta
64 phrase pairs used per each update
most frequent 15,000 words (both English and French)
또한, 실험에는 target language model을 습득하는 neural network인 Schwenk의 CSLM를 추가로 적용해 사용하기도 했습니다.
실험에서 사용한 4가지 조합은 다음과 같습니다.
Baseline: Moses 기본 세팅
Baseline + RNN: RNN Encoder-Decoder 적용
Baseline + CSLM + RNN: CSLM 추가 적용
Baseline + CSLM + RNN + Word penalty: 모르는 단어에 penalty 추가 적용
Results
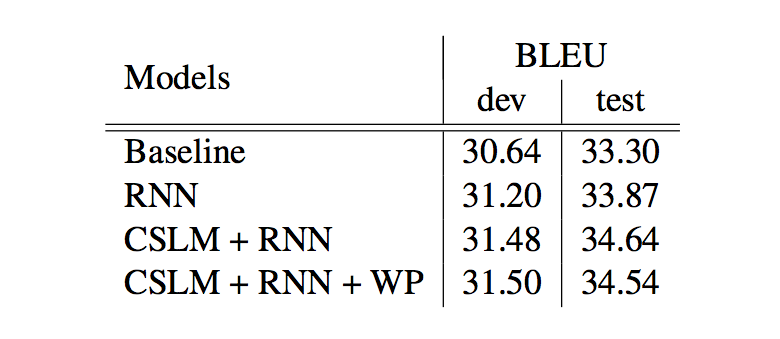
아래 그림은 실험 결과를 요약한 테이블입니다.
간단히 정리하면 다음과 같습니다.
RNN Encoder-Decoder를 적용해 baseline 대비 성능이 개선되었다.
CSLM과 함께 적용했을 때 가장 성능이 좋았다. 즉, 두 방법이 성능 향상에 독립적으로 기여한다.
Word penalty까지 적용한 경우는 test set에서 성능이 약간 떨어졌다.
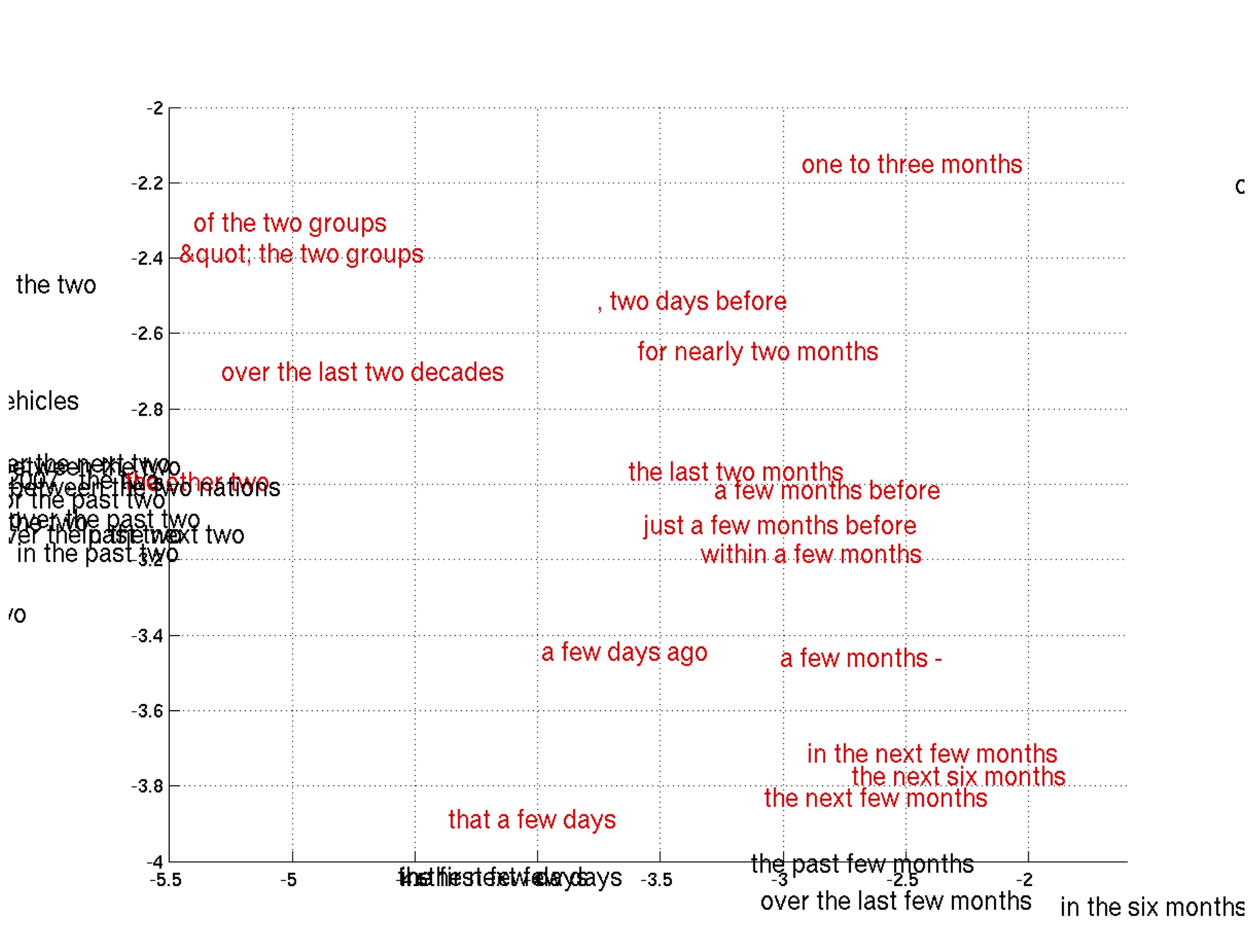
또한, 정성적인 실험 결과에서는 제안하는 모델이 phrase들을 의미적으로(semantically) 그리고 문법적으로(syntactically) 잘 표현하는 것을 볼 수 있었습니다. 아래 그림은 학습한 phrase representation의 2D embedding 일부를 확대해 보인 것입니다.
이 논문에서는 임의의 길이를 가지는 sequence를 다른 (역시 임의의 길이를 가지는) sequence로 mapping하는 학습을 할 수 있는 새로운 neural network인 RNN Encoder-Decoder (seq2seq)를 제안했습니다. 이 모델은 sequence pair들에게 조건부 확률에 기반해 점수를 매기는 용도로 쓸 수도 있고, source sequence 입력에 대한 target sequence 생성에도 쓸 수 있습니다.
또한 이 논문에서는 reset gate와 update gate로 구성되어 개별 hidden unit들이 기억하거나 잊는 정도를 adaptive하게 제어할 수 있는 새로운 hidden unit (GRU)를 제안했습니다. GRU는 현재까지 RNN 구현에 LSTM과 함께 필수적인 구성요소로 자리매김하고 있습니다.
이 논문의 저자들은, CNN (Convolutional Neural Network)이 (지금까지 image 처리 분야에서 많은 성과를 거뒀지만) 근본적으로 한계가 있다고 주장합니다. CNN에서 사용하는 여러 연산(convolution, pooling, RoI pooling 등)이 기하학적으로 일정한 패턴을 가정하고 있기 때문에 복잡한 transformation에 유연하게 대처하기 어렵다는 것입니다. 저자들은 그 예로 CNN layer에서 사용하는 receptive field의 크기가 항상 같고, object detection에 사용하는 feature를 얻기 위해 사람의 작업이 필요한 점 등을 들고 있습니다.
이를 해결하기 위해 이 논문에서는 Deformable Convolution과 Deformable ROI Pooling이라는 두 가지 방법을 제안합니다.
Deformable Convolution
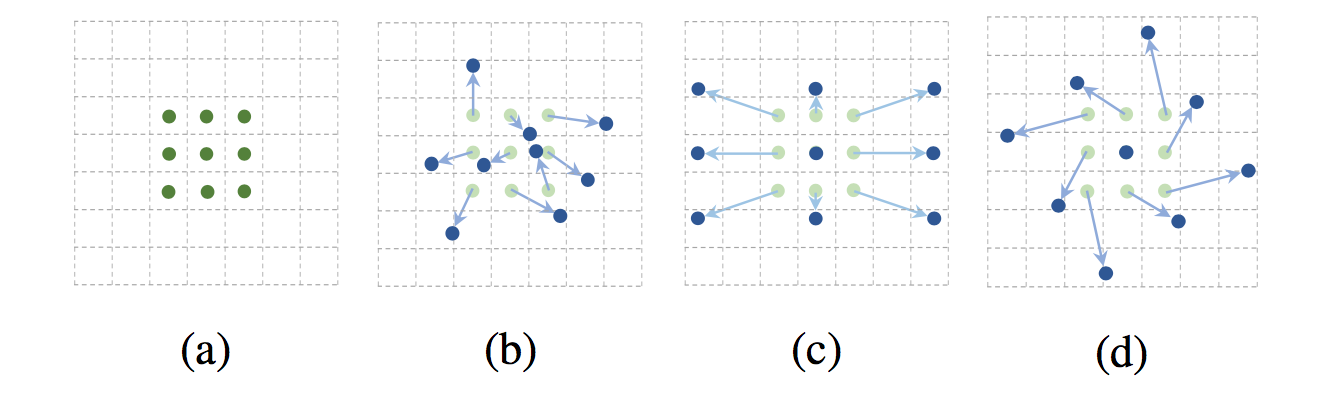
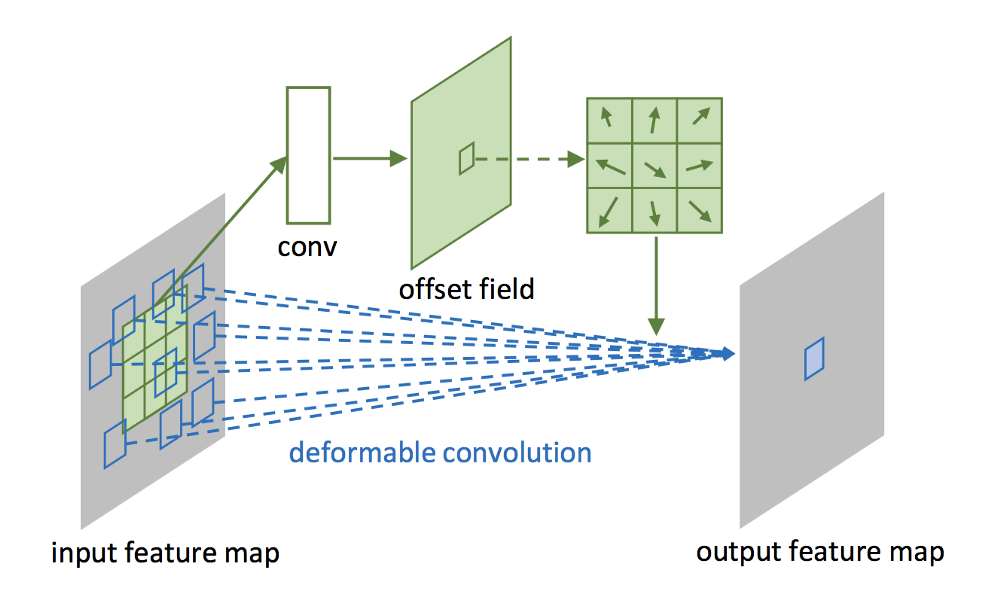
Deformable Convolution은 아래 그림처럼 convolution에서 사용하는 sampling grid에 2D offset을 더한다는 아이디어에서 출발합니다.
그림 (a)의 초록색 점이 일반적인 convolution의 sampling grid입니다. 여기에 offset을 더해(초록색 화살표) (b)(c)(d)의 푸른색 점들처럼 다양한 패턴으로 변형시켜 사용할 수 있습니다.
아래 그림은 $3 \times 3$ deformable convolution의 예를 보이고 있습니다.
그림에서 보는 것처럼 deformable convolution에는 일반적인 convolution layer 말고 하나의 convolution layer가 더 있습니다. 그림에서 conv라는 이름이 붙은 이 초록색 layer가 각 입력의 2D offset을 학습하기 위한 것입니다. 여기서 offset은 integer 값이 아니라 fractional number이기 때문에 0.5 같은 소수 값이 가능하며, 실제 계산은 linear interpolation (2D이므로 bilinear interpolation)으로 이뤄집니다.
Training 과정에서, output feature를 만드는 convolution kernel과 offset을 정하는 convolution kernel을 동시에 학습할 수 있습니다.
위의 그림은 convolution filter의 sampling 위치를 보여주는 예제입니다. 붉은 점은 deformable convolution filter에서 학습한 offset을 반영한 sampling location이며, 초록색 사각형은 filter의 output 위치입니다. 일정하게 샘플링 패턴이 고정되어 있지 않고, 큰 object에 대해서는 receptive field가 더 커진 것을 확인할 수 있습니다.
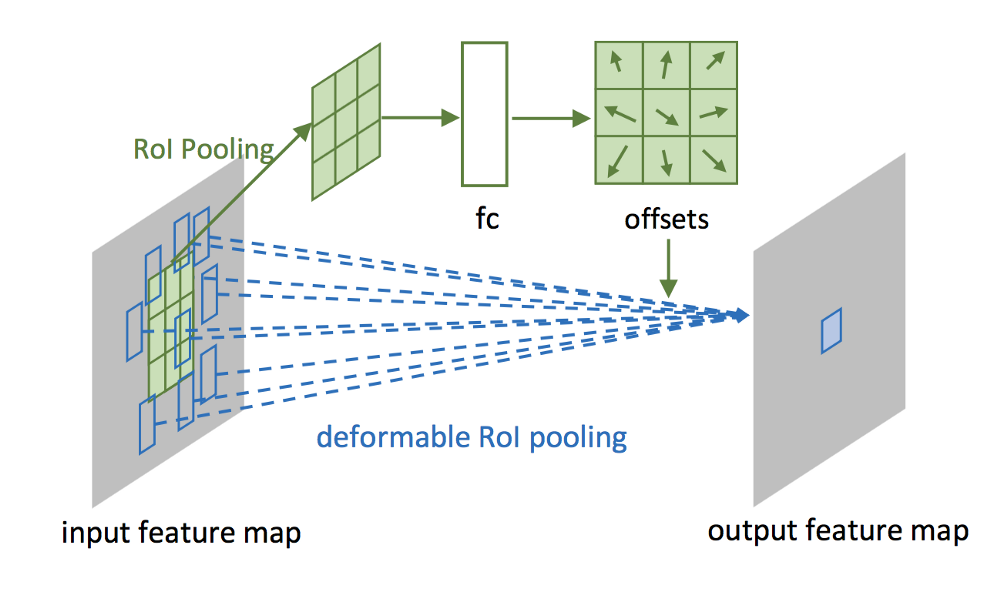
Deformable RoI pooling도 일반적인 RoI pooling layer와 offset을 학습하기 위한 layer로 구성됩니다. 한 가지 deformable convolution과 다른 점은, offset을 학습하는 부분에 convolution이 아니라 fc (fully-connected) layer를 사용한 것인데 아쉽게도 그 이유가 논문에 밝혀져 있지 않습니다. Neural network에서 convolutional layer와 fully-connected layer의 차이에 대해서는 Reddit의 관련 post를 참고하시기 바랍니다.
마찬가지로 training 과정에서 offset을 결정하는 fc layer도 backpropagation을 통해 학습됩니다.
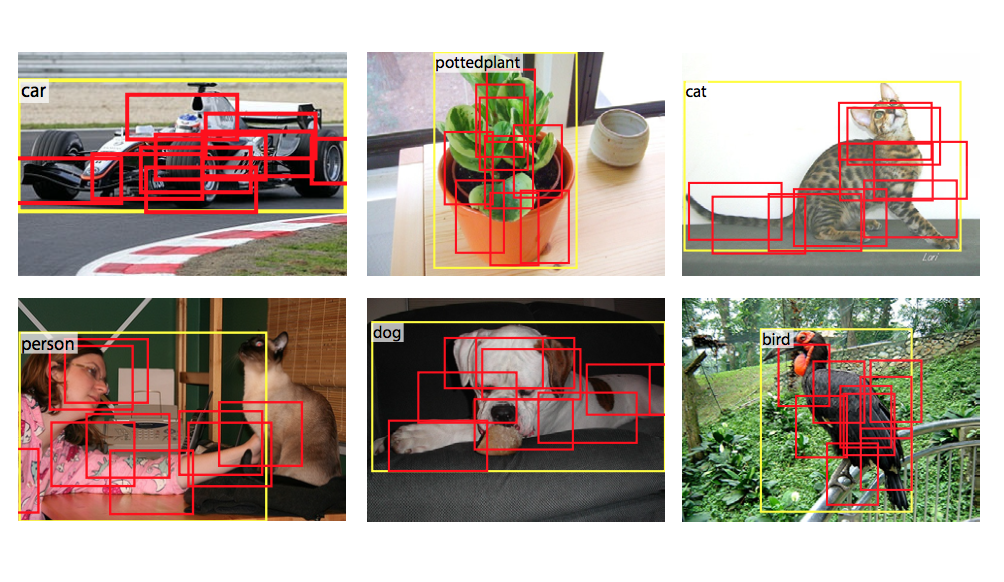
아래 그림은 노란색 입력 RoI에 대해 붉은색 deformable RoI pooling 결과를 보여줍니다. 이 실험 결과에서, RoI에 해당하는 붉은 사각형의 모양이 object 형태에 따라 다양한 형태로 변형되는 것을 볼 수 있습니다.
지금까지 deep learning 분야의 많은 연구들이 predictor의 weight 값 $w$를 구하는 방법에 초점을 맞췄던 반면, 이 논문은 어떤 데이터 $x$를 뽑을 것인가에 초점을 맞췄다는 점이 참신하다는 평가를 받고 있습니다. 이제 갓 발표된 논문인 만큼, 향후 다른 연구에 어떤 영향을 미칠지 앞으로 주목할 필요가 있을 것 같군요.
GAN의 핵심 아이디어는 두 개의 뉴럴넷(Discriminator와 Generator)을 동시에 트레이닝해서 서로 경쟁시키는 것입니다. Generator $G(z)$는 진짜 같은 data를 만들어 내려 하고, Discriminator $D(x)$는 현재 자기가 보고 있는 sample이 실제 data인지 Generator가 만든 가짜인지 판별하려고 합니다. (여기서 $G(z)$의 $z$는 Generator의 입력이 되는 확률 변수로 $p_z(z)$라는 분포를 따르고, $D(x)$의 $x$는 실제 데이터(주어진 이미지)를 의미하며 $p_{data}(x)$라는 분포를 따릅니다.)
Value function을 식으로 정리하면 아래와 같습니다.
오른쪽 첫 번째 항 에서 Discriminator $D(x)$는 실제 data와 $G(z)$가 만들어낸 data에 정확한 label을 붙(일 확률을 높)이려는 방향으로 학습됩니다. 한편, 두 번째 항 에서 Generator $G(z)$는 $log(1-D(G(z)))$을 최소화하려는 방향으로 학습됩니다. 이와 같은 특성 때문에 GAN의 value function은 흔히 min max, 또는 minimax라는 문제가 됩니다. 이 용어는 게임 이론에서 유래된 단어입니다.
GAN의 구현 알고리즘
이 논문에 예시된 알고리즘은 아래와 같습니다.
요약하면, stochastic gradient descent (SGD) 계열의 알고리즘을 적용해 minibatch 단위로 Discriminator $D(x)$와 Generator $G(z)$를 번갈아 가며 training 시킵니다. 일반적으로 $D(x)$가 $G(z)$보다 빨리 성장하는 경향이 있습니다. 그런 경우, $G(z)$가 아직 미숙한데 $D(x)$가 너무 결과를 잘 판별해 버리면 $G(z)$가 쉽게 죽어버립니다. 두 모델이 균형 있게 성장하도록 많은 튜닝이 필요합니다.
구현 시 더 빠른 학습을 위해 learning rate를 adaptation하는 Adam 등의 최적화 기법을 적용하기도 합니다. 참고로 Adam을 포함해 흔히 사용되는 gradient descent optimization algorithm들은 Sebastian Ruder의 블로그와 논문에 잘 정리되어 있습니다.
위의 알고리즘이 converge하는 것을 이 논문에서는 KL (Kullback-Leibler) divergence와 JS (Jensen-Shannon) divergence를 사용해서 증명을 시도합니다. 그런데 실제 구현을 neural network으로 하면서도 증명은 probability function의 관점에서 하기 때문에 다소 억지로 맞춘 듯한 느낌이 있습니다. Training이 어려운 것과 함께 이러한 GAN의 단점을 극복하기 위해, 더 엄밀한 수학적 전개를 적용한 Wasserstein GAN (WGAN)이라는 논문이 후에 주목받게 됩니다.
GAN에 대한 평가
현재까지 알려진 GAN의 장단점은 아래와 같습니다.
장점
결과물의 quality가 좋다: VAE등 기존 연구 대비 선명
출력이 빨리 나온다: PixelRNN등 픽셀 단위 출력 대비
단점
training이 unstable하다.
정량적 quality 측정 기준 미비: 사람의 주관적 판단에 의존
oscillation: 오래 training해도 더 이상 수렴 못하는 현상
mode collapsing 문제: 비슷비슷한 결과물이 나오는 현상
최근 GAN의 인기는 앞서 언급한 Arjovsky의 WGAN, Radford의 DCGAN, Chen의 InfoGAN 등 다양한 후속 연구에 힘입은 바가 큽니다. 이에 대해서는 다른 포스팅에서 더 다뤄보도록 하겠습니다.

 (그림 출처: TensorFlow 공식 사이트의
(그림 출처: TensorFlow 공식 사이트의