Playing Atari with Deep Reinforcement Learning
07 May 2017 | PR12, Paper, Machine Learning, Reinforcement Learning이번 논문은 DeepMind Technologies에서 2013년 12월에 공개한 “Playing Atari with Deep Reinforcement Learning”입니다.
이 논문은 reinforcement learning (강화 학습) 문제에 deep learning을 성공적으로 적용한 첫 번째로 평가받고 있습니다. DQN (Deep Q-Network)이 바로 이 논문의 연구 결과입니다. 저자들은 이 내용을 발전시켜 2015년 Nature에 “Human-Level Control Through Deep Reinforcement Learning”라는 논문을 냈습니다.
이 논문에서 풀려는 문제는 다차원 sensory input으로부터 직접 학습하는 reinforcement learning model을 만드는 것입니다. 쉽게 말해, 사람이 찾아낸 feature를 사용하는 것이 아니라 raw sensory data (이 논문에서는 video 데이터)에서 스스로 feature를 추출합니다.
DQN 알고리즘
이를 위해 이 논문에서는 Q-learning 알고리즘에 CNN (Convolutional Neural Network)을 적용한 모델을 사용했습니다.
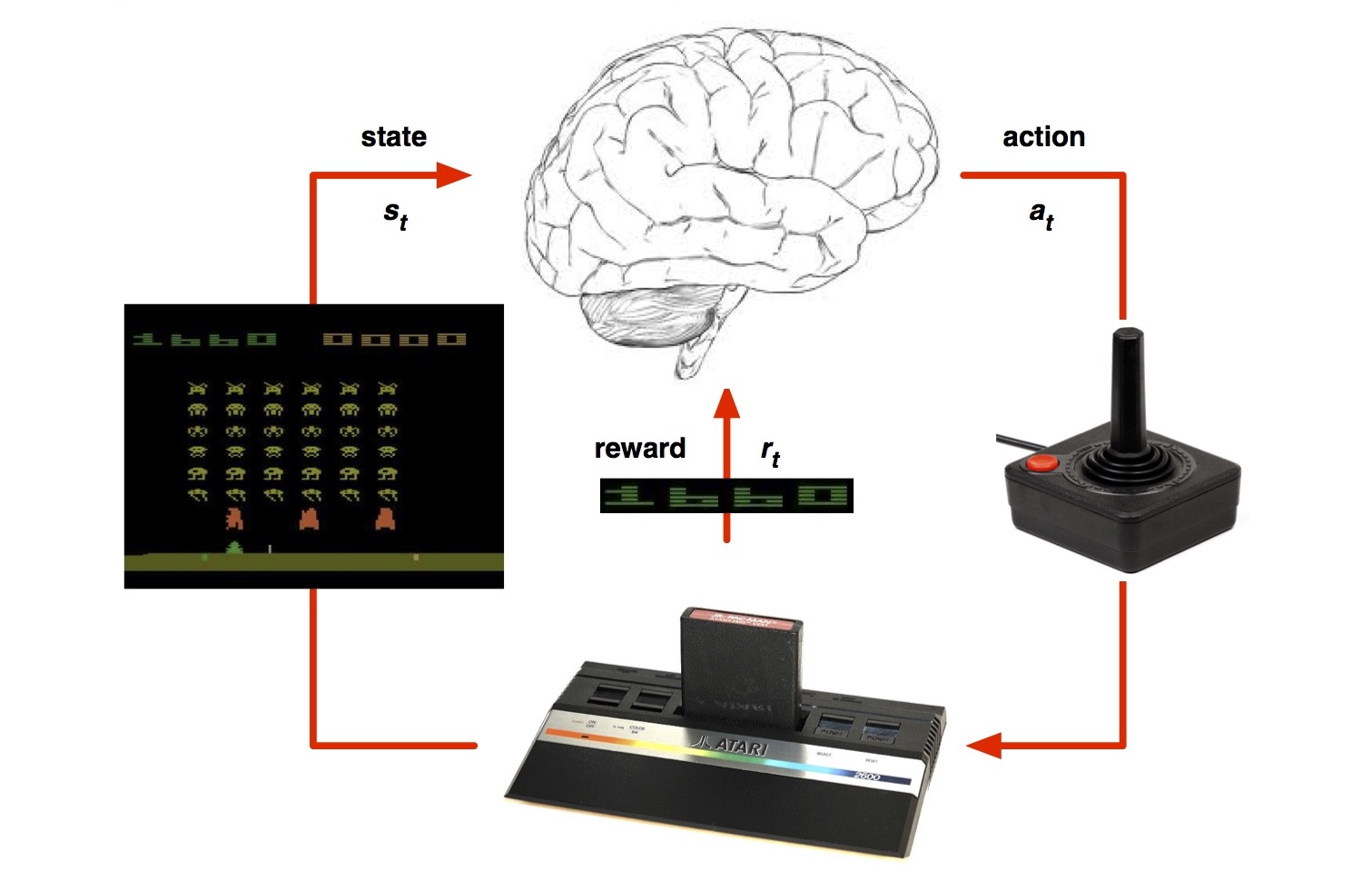
기존의 reinforcement learning 이론에서, 어떤 policy $\pi$에 따라 현재 state $s$에서 action $a$를 취했을 때의 expected total reward를 action-value function $Q^\pi(s, a)$로 정의합니다.
이 식에서 $R_t$는 time $t$ 시점의 future discounted return으로 정의됩니다.
주어진 reinforcement learning 문제를 풀기 위해 이 Q 값을 최대화하는 optimal policy를 찾는 것이 Q-learning 알고리즘입니다. 즉, optimal action-value function $Q^*(s,a)$는 아래와 같습니다.
Optimal action-value function $Q^*(s,a)$는 Bellman equation에 의해 아래와 같이 recursive한 형태로 표현됩니다. Bellman equation은 제어 이론, 응용 수학, 경제학 이론에도 자주 등장하는 유명한 식입니다.
이 식의 의미는 다음과 같습니다. 현 시점에서 가능한 모든 action $a’$에 대해서, 그 action를 했을 때 미래에 예상되는 reward를 계산해 봅니다. 그러면 그 중에서 최대가 되는 경우의 $a’$을 찾을 수 있습니다. 그 때의 미래에 예상되는 reward 값인 에 future discount factor $\gamma$를 곱해서 현재의 reward $r$ 값과 더하면 optimal action-value function 값을 계산할 수 있다는 것입니다. 다르게 말하면, ${r + \gamma \max_{a’} Q^*(s’, a’)}$의 기대값을 최대화하는 action $a’$을 선택하는 것이 optimal policy라고 할 수 있습니다.
여기까지는 아직 neural network를 적용하지 않은 reinforcement learning 이론입니다. 강화 학습에 대한 기본적인 내용은 DeepMind David Silver의 강의 슬라이드와 동영상, Richard Sutton의 “Reinforcement Learning: An Introduction” 책, 모두의 연구소 이웅원 님의 GitBook에 잘 설명되어 있습니다.
지금 이 연구에서 풀려는 Atari 2600 게임은 action에 대한 transition 확률과 reward가 명시적으로 주어지지 않는 model-free 문제입니다. 따라서 (3)식의 $Q^*(s,a)$를 table (Q-table)을 보고 산술적으로 계산할 수 없고, 대신 데이터에서 학습하여 prediction하는 접근 방법을 씁니다. 지금까지는 prediction에 supervised learning의 linear regression predictor 계열을 주로 사용해왔고, neural network을 사용했을 때에는 불안정해지거나 diverge하는 것으로 알려져 있었습니다.
이 논문의 가장 큰 contribution은 두 가지 아이디어로 Q-learning 알고리즘을 개선해서 neural network predictor 적용에 성공한 것입니다. 그 첫 번째는 experience replay이고, 두 번째는 target network의 사용입니다.
Experience replay는 인접한 학습 데이터 사이의 correlation으로 인한 비효율성을 극복하기 위한 기법입니다. 게임을 하는 agent의 경험 데이터 $(s,a,r,s’)$를 replay memory라는 이름의 buffer pool에 매 순간 저장해 뒀다가, update 할 때는 replay memory에서 random하게 minibatch 크기의 sample을 뽑아 계산하는 것입니다.
Target Network는 DQN과 똑같은 neural network을 하나 더 만들어, 그 weight 값이 가끔씩만 update 되도록 한 것입니다. $Q(s,a)$를 학습하는 순간, target 값도 따라 변하면서 학습 성능이 떨어지는 문제를 개선하기 위해서입니다. Target network의 weight 값들은 주기적으로 DQN의 값을 복사해 옵니다. Q-learning의 update에서 아래 식과 같은 loss function을 사용하는데, 먼저 나오는 $Q$는 target network에서 계산한 것이고 뒤의 $Q$는 원래의 DQN에서 계산한 것입니다.
이 연구에서 적용한 neural network은 3개의 convolutional layer와 2개의 fully-connected layer가 있는 구조입니다. Input state $s$는 이전의 $84 \times 84$ 크기의 프레임 4장이고, Output은 18개의 joystick/button 동작에 대한 $Q(s,a)$ 값, Reward는 score의 변경 값입니다.
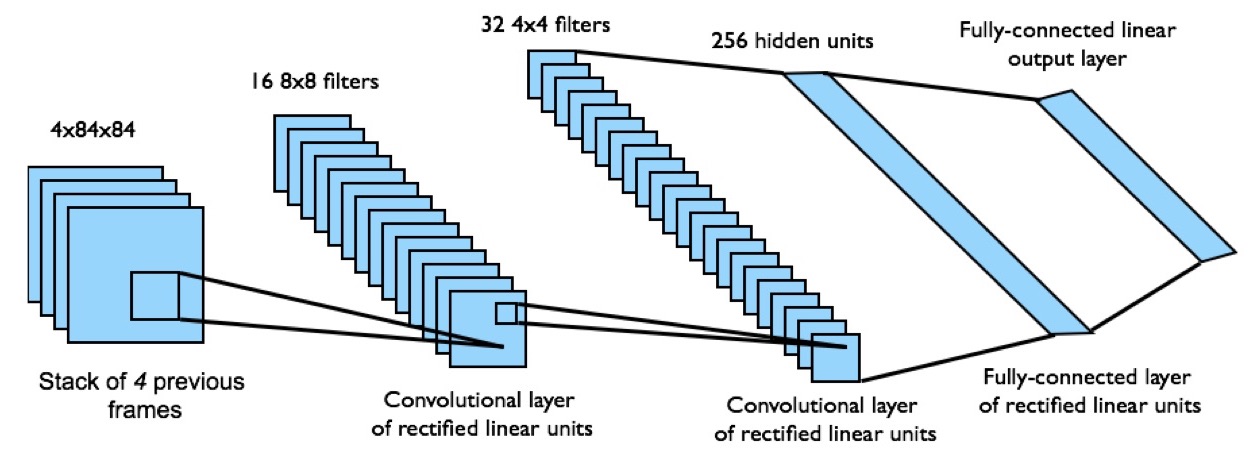
지금까지 설명한 전체 DQN 알고리즘은 아래와 같습니다.

실험 결과
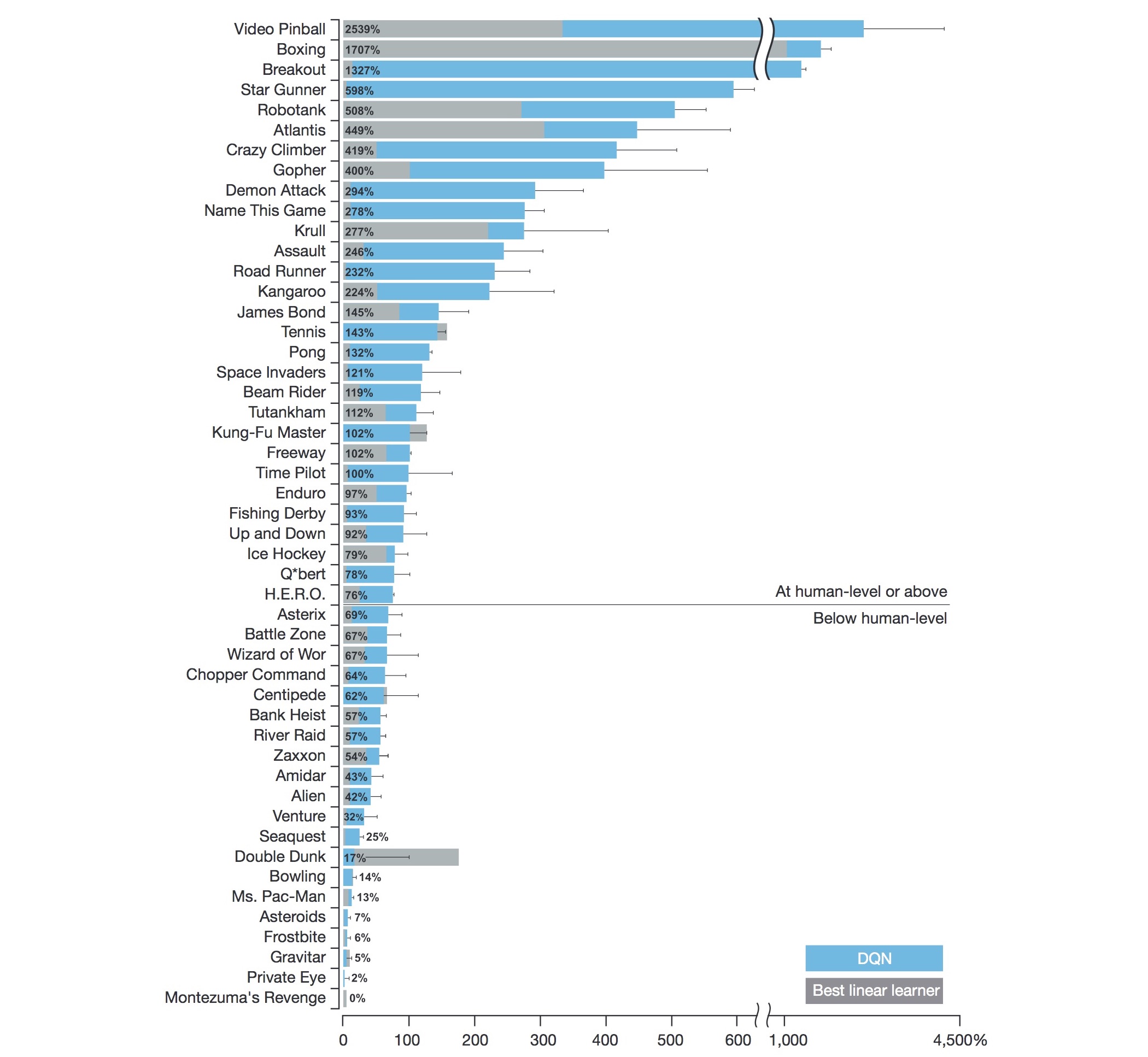
저자들은 이 논문에서 Atari 2600의 7가지 게임(Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, Space Invaders)의 실험 결과를 보였습니다. 하지만 나중에 나온 2015년 Nature의 논문에서는 아래 그림과 같이 총 49개의 게임에 대한 결과를 보입니다. DQN은 다른 알고리즘보다 43개 게임에서 점수가 높았고, 29개 게임에서 human tester 점수의 75% 이상을 얻었다고 합니다.
하지만 논문을 읽지 않은 분들이라도 DeepMind에서 직접 올린 아래의 YouTube 영상은 다들 보신 적이 있을 겁니다. 600개의 에피소드를 학습한 다음, 벽 옆으로 터널을 만들어 공략하는 기술이 지금 봐도 놀랍습니다.
후속 연구
Q-learning 값을 update하는 식에서 max 연산자를 사용하기 때문에 DQN은 Q-value를 실제보다 높게 평가하고 그 결과 학습이 느려지는 경향이 있습니다. 이를 개선한 Double DQN이라는 알고리즘이 2015년에 역시 DeepMind에서 발표되었습니다.
또한, replay memory에서 uniform random sampling하는 DQN의 방식을 개선한 prioritized experience replay라는 기법이 제안되기도 했습니다. 이 방법은 더 중요한 experience를 더 자주 replay하도록 weight을 주어 효율적인 학습 효과를 보였습니다.
– Jamie;
References
- Volodymyr Mnih의 paper @arXiv.org
- Volodymyr Mnih의 Nature 논문 “Human-Level Control Through Deep Reinforcement Learning”
- Volodymyr Mnih의 DQN 3.0 소스 코드
- Sung Kim 님의 동영상 “PR-005: Playing Atari with Deep Reinforcement Learning”
- 김태훈 님의 슬라이드 “Reinforcement Learning : An Introduction”
- Wikipedia의 CNN (Convolutional Neural Network)
- Wikipedia의 Q-learning 알고리즘
- Wikipedia의 Bellman equation
- David Silver의 강의 슬라이드 UCL Course on RL
- David Silver의 강의 동영상 “RL Course by David Silver - Lecture 1: Introduction to Reinforcement Learning”
- 모두의 연구소 이웅원 님의 GitBook “Fundamental of Reinforcement Learning”
- Richard Sutton의 책 “Reinforcement Learning: An Introduction”
- Hado van Hasselt의 Double DQN paper @arXiv.org
- Tom Schaul의 “Prioritized Experience Replay” paper @arXiv.org